

【解构系统设计面试】什么是系统设计?以及如何设计一个新鲜事系统?
source link: http://blog.luoyuanhang.com/2020/05/24/system-design-0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
这篇文章是《解构系统设计面试》系列博文的第一篇,在这篇文章里我会介绍一下面试中的系统设计是什么,面试官大体上会从哪些方面来考量系统设计的答案,介绍一种分析系统设计问题的方法论(4S 分析法)以及会以“设计一个新鲜事系统”为例,解构这一经典的系统设计面试题。
我为什么要写这一系列文章?
笔者最初萌生写系统设计博客的时候还是 2017 年底的时候,那时候正在北美刷算法题、系统设计题、面向对象设计题等等,备战 FLAG 等大厂的面试。那时笔者准备写这一系列博客的一个主要原因是,将自己学习到的知识通过写博文的形式重新整理消化一遍,同时供自己反复查阅、增补。如今已经 2020 年了,其间的两年多的时间里笔者经历了很多的事情,没有加入北美大厂,回国之后加入了一家区块链公司(如有兴趣,请见文章末尾投递简历),逐渐从被面试的面试者走上了面试官的岗位。我对面试者的技术考察主要会关注项目经历、基础知识、基本算法以及系统设计等方面,尤其更感兴趣面试者对系统设计问题的解答(当然,具体问题具体分析,对应届毕业生和社招人员的考察方面也会有所侧重)。
从面试者对系统设计问题的解答中,通常能够了解到:
- 面试者对面试本身是否做过充足的准备;
- 面试者有没有拆解问题的能力;
- 面试者思路是否清晰;
- 面试者有没有了解过基本的架构设计;
- 面试者有没有具体的实操经验;
总之,系统设计是能说明很多问题的,如果你想给面试官一个眼前一亮的印象,对系统设计问题的解答是很重要的,是能很大程度上证明自己的技术素养和技术思维的。除此之外,系统设计往往也是大厂面试中非常看中的一部分。
在面试的过程中,在我和面试者的交流中,系统设计这一环节也是对我自己有很大提升的部分。因为系统设计面试题通常是没有标准答案的,在一步步往下聊、挖掘问题的过程中,常常能够发现新的问题、新的解决方案。我希望,通过这一系列的文章,一方面把系统设计的问题与解决方案总结起来,把这些知识反复迭代消化,让自己对系统设计的理解有所提升,另一方面希望这一系列文章能对面试者们有所帮助。我认为,即便一个技术人员不以面试为目的,也应该去了解一些系统设计的知识与场景,当然,这些积累可能是来源于工作中的项目经验,也可能来源于阅读博客、文章、论文等。
(说句题外话,很多人在毕业之后就很少看论文文献了,其实很多论文中包括了很多解决工程问题的方案方法,我还是很推荐大家多了解下大厂发表的论文等,比如这篇文章中提到的惊群效应的实际解决方案就来源于 Facebook 发表的 Paper; 比如现在经典的一些分布式系统设计题目多数都脱不开 Google 的三架马车【MapReduce、GFS、BigTable】,笔者这一系列文章会对相关问题进行讨论,对于 GFS 的介绍可以参考笔者另一篇文章 - 《GFS 阅读笔记》)。
在文章正题的开始之前,我要感谢九章算法,是九章在一开始的时候带我进入了系统设计的世界,这一系列文章内容很大一部分也是受九章算法的系统设计课程的启发,对课程中提到的问题进行了解释与延伸,并且加入了我在工作中所遇到的实际问题的思考与解决方案。
下面进入这一系列文章的正题:
系统设计是什么?
系统设计(System Design)本身是一个很宽泛的话题。在互联网上有各种各样的资源是关于系统设计的,这些资源里更多的是面向准备面试软件工程师岗位的初学者们的。有些面试者往往会把系统设计、面向对象设计以及 API 设计混为一谈,而往往这几种设计是存在区别和联系的:
- 面向对象设计(OO Design)往往考察的是:
- 面向对象的基础知识;
- 设计模式;
- 实现一段子系统的代码骨架(Class Design)
- API 设计往往考察的是:
- 网站前端与后端程序交互的 API 设计;
- 或者 APP 与后端程序交互的 API 设计;
- (这一面试题往往对有过实际 Web/APP 后端编码经验的面试者来说是小菜一碟)
- 而系统设计(System Design)往往考察的要更为宽泛与全面一些:
- 它是一项围绕系统架构设计的面试;
- 往往会围绕一个具体的技术目标来展开;
- 通常没有一个最佳的正确答案;
- 往往需要全面但不那么细节的知识储备
系统设计也是不同于程序设计的,通常来说:
程序 = 算法 + 数据结构
系统 = 服务 + 数据存储
程序设计是微观上的设计,而系统设计是面向宏观的设计。
这一系列文章会重点围绕着系统设计展开,从如何解构系统设计面试题的方法论开始,逐渐引入各种常见的面试题以及实际生产 CASE 的解决方案,可能中间会穿插一部分面向对象设计与 API 设计的内容。
系统设计面试题的形式
系统设计面试题主要会有下面两种形式:
设计一个 XX 系统:
- 设计微博 / Twitter;
- 设计人人 / Facebook;
- 设计滴滴 / Uber;
- 设计微信 / Whatsapp;
- 设计大众点评 / Yelp;
- 设计短网址系统;
- 设计 NoSQL 数据库;
找问题并提出解决方案:
- 网站挂了怎么办?
- 网站访问太慢怎么办?
- 网站流量激增怎么办?
系统设计评分维度
针对系统设计面试题的解答答案评价,九章算法总结的要从以下方面进行考量,笔者还是很认同的:
- 可行解:可行解往往是答案最重要的一部分,也是能够引出后续系统设计面试过程的重要一步,往往面试官会从这一可行解中找到可优化或者有缺陷的地方提出针对性的问题,是后续面试过程的基础;
- 特定问题:面试者是否有分析饼解决系统设计特定问题的能力;
- 分析问题:对一个系统设计问题的分析过程往往比设计这个系统得到的结果更重要;
- 权衡(tradeoff):永远不会有一个在任何场景下都表现最优秀的系统,系统设计的结论往往是权衡利弊的结果(可类比分布式系统设计中的 CAP 定律、不可能三角);
- 知识储备:往往系统设计需要比较全面的知识储备,比如说:缓存、SQL/NoSQL 数据库、分布式基础知识、常见系统架构……
如何解构系统设计问题?
正如这篇文章中【系统设计面试题的形式】这一部分内容中提到的,如果面试官上来抛出了一道形如“请设计一个微博系统”,我相信绝大多数未经过系统设计面试准备的面试者们是很迷茫的,根本不知道从什么地方入手来回答这一问题。出现这一现象是完全正常的,因为这个问题实在是太笼统了,微博一整个系统也太庞大了,从什么地方入手开始设计呢?该如何回答面试官的这一问题呢?
因此,我们需要对系统设计问题进行解构,九章算法提出的 4S 分析法就是一套简单、易于理解的方法论,4S 指的是:
- 场景 - Scenario
- 服务 - Service
- 存储 - Storage
- 扩展 - Scale
通常,对一道系统设计面试题的解构也是按照上述步骤来依次递进的。接下来,笔者会详细对上述的关键词进行解释与分析:
场景 - Scenario
简单来说,场景指的是,在这一系统设计中需要设计哪些功能、这一设计需要多牛(扛得住多少并发、支持多少用户、可用程度能达到什么标准等)。
首先,第一个入手点应该是,这一系统需要设计哪些功能,这时开始对该系统的功能列举,然后选择出系统中的核心功能,因为你不可能在短短的面试过程中完成所有功能的设计。通常这一步时,面试官会挑出一个或者几个功能来进行后续问答。
然而,即便是将系统设计问题缩小到了特定功能这一范围,往往还是不能够开始进行设计的。因为不确定系统的规模、用户量是很难进行系统设计的,比如设计一个 100 人使用的微博与 10M 人使用的微博系统肯定是截然不同的,这些指标会影响我们在进行系统设计时的权衡(tradeoff)与策略选择。
而确定场景的过程中往往需要了解一些名词与经验值:
- 日活跃用户(DAU,Daily Active User)
- 月活跃用户(MAU,Monthly Active User)
- 读/写频率(QPS,Queries Per Second)
而一些经验值的计算如下:
- 并发用户(秒) = 日活跃用户 * 美股用户平均每日请求次数(估算)/ 86400 秒
- 访问峰值 = 并发用户 * 倍数(通常 2~9 倍都是合理的)
- 通过上述数值做出对读/写 QPS 的估算
分析出 QPS 能够帮助我们确定在设计系统时的规模:
- QPS < 100:使用单机低配服务器就可以了;
- QPS < 1K:稍好一些的中高配服务器(需要考虑单点故障、雪崩问题等);
- QPS 达到 1M:百台以上 Web 服务器集群(需要考虑容错与恢复问题,某一台机器挂了怎么办,如何恢复)
QPS 和 Web Server 或者 数据库之间也是存在关联性的:
- 一台 Web Server 的承受量约为 1K QPS;
- 一台 SQL Database 的承受量约为 1K QPS(如果数据库访问中涵盖大量的 JOIN 和索引相关查询,这一数值会更小);
- 一台 NoSQL Database(如 Cassandra)承受量约为 10K QPS;
- 一台 NoSQL 缓存 Database(如 Memcached 内存 KV 数据库)承受量约为 1M QPS
在这一步骤中,最关键的是要多与面试官交流、多问,这样才能确定好即将设计的这一系统的功能、系统规模等,而在问与交流的过程中,同时就已经在体现一个面试者的专业程度和思考方式了,这是很重要的一点。
服务 - Service
在这一步骤中,面试者需要做的事情是:将大系统拆分为小服务。
什么是服务呢?
- 服务其实就是对逻辑处理的整合;
- 把同一类的逻辑处理整合在同一个服务中;
- 把整个系统拆分为若干个小的服务
因此,在这一过程中,需要:
- 第一步 - Replay:重新过一下所有需求,为每个需求添加一个或多个服务
- 第二步 - Merge:将相同的服务进行归并
这一步是应该很快就能够完成的。
存储 - Storage
说到系统设计中的存储,其实就是设计这个系统中的数据是如何进行存储和访问的。简单来讲,就是什么数据?用什么存?怎么存?
从常用数据库的分类来看,一般会涉及到下面几种数据库类型:
- SQL 数据库 - 关系型数据库:一般用于存储结构化数据,例如用户信息(Profile)、各种业务表单数据等;
- NoSQL 数据库 - 非关系型数据库:一般用于存储非结构化数据,文章、社交图谱等;
- 文件系统:严格来讲,文件系统其实不属于数据库,但是在系统设计中,作为一种对数据进行存放、读写的容器,也是常常会出现在系统设计的相关问题中的。文件系统可以存放图片(非常推荐小图片可以用 fastDFS 这类分布式存储)、视频。AWS 的 S3 也属于一种文件系统。
在系统设计的存储设计中,通常可以分为以下两步:
- 第一步 - Select:为每个服务选择合适的存储结构
- 第二步 - Schema:细化数据库的表结构
扩展 - Scale
扩展这一部分内容主要围绕的是该如何对系统进行优化和维护。
因此,分为两个主要部分:
- 优化(Optimize):
- 解决设计缺陷;
- 更多功能设计;
- 特殊用例的设计(极端情况、边界处理)
- 维护(Maintainance):
- 系统的鲁棒性:如果有一台/几台服务器/数据库挂了,怎么办?
- 系统的扩展性:如果流量暴增如何扩展系统?
CASE:设计一个新鲜事系统
以上内容对 4S 分析法做了一个方法论层面的概述,但是仅仅来谈方法论对很多人来说还是很模糊的,依旧不知道该如何使用这一套方法论来解答系统设计面试题。接下来的内容,会围绕一个经典的系统设计面试题进行展开,一步一步根据上边的方法论来对这一案例进行解构。同时,后边的内容还有许多具体的问题,能够帮助大家更好的理解 4S 分析法以及系统设计面试题的套路。
这一个 CASE 就是:该如何设计一个新鲜事系统?
新鲜事系统是什么?
如果要开始设计一个新鲜事系统,就要了解什么是新鲜事系统(News Feed)。在我们的互联网系统中,存在着各种各样的新鲜事系统,其中 Facebook,Twitter,微博,微信朋友圈都属于新鲜事系统。
在新鲜事系统中,有两个概念很容易被混淆,一个是新鲜事,另一个是时间线。以新浪微博为例,先来解释一下时间线的概念,时间线就是打开一个用户的首页,看到的以时间为序列展示的,该用户的微博、转发等等;而新鲜事则是,你打开微博,看到的你所关注的用户、明星、大V等发布的内容,以时间为序列展示在你的首页的内容。
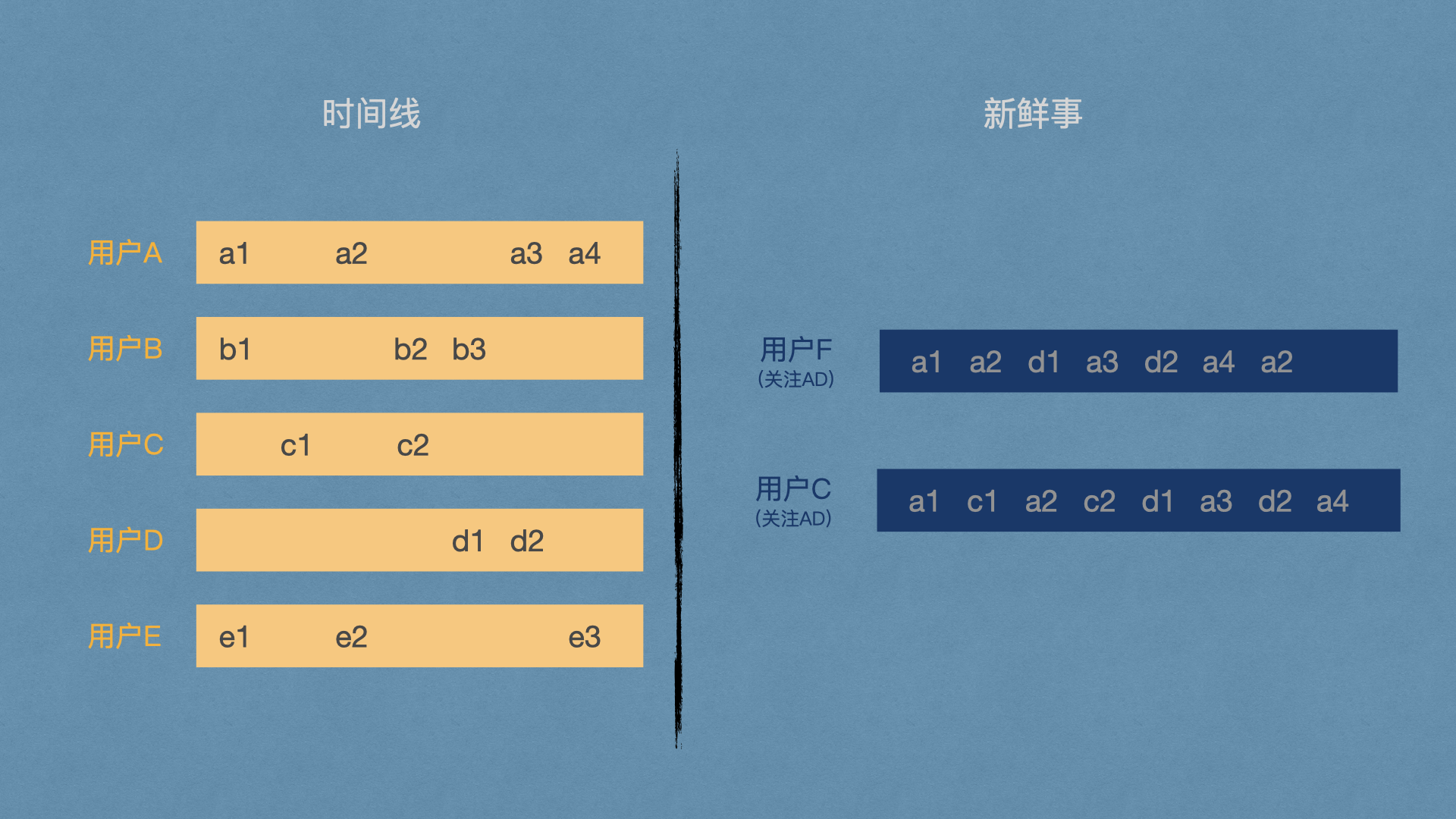
有些人习惯将两个概念反过来区分,这也是没有问题的,只不过本篇文章通篇都会以上边的解释对新鲜事和时间线进行区分。
解构问题(4S 分析法)
了解了什么是新鲜事系统,接下来的内容就要使用 4S 分析法来解构这一系统设计问题了。
场景 - Scenario
首先,根据方法论,在场景设计这一阶段首先要分析出这一系统需要设计那些功能,最简单的方式就是将这些功能列举出来。
功能列举:
- 发布/转发新鲜事;
- 时间线/新鲜事;
- 用户关注/取消关注;
- 登录/注册;
- 搜索新鲜事;
- 用户 Profile 的展示与编辑;
- 上传图像/视频;
其中加粗的功能是我认为在一个新鲜事系统里最重要也是面试官最喜欢考察的部分。在系统设计的面试中,要快速的选择出功能列表中哪些功能是该系统中最核心的功能,因为在面试短短的时间里你没有办法做到设计好全部功能的。
挑选出了核心功能,后面一步就是要分析、推断、预测出系统中的用户规模与访问量。下图是 Twitter 的月活跃用户的统计图表:
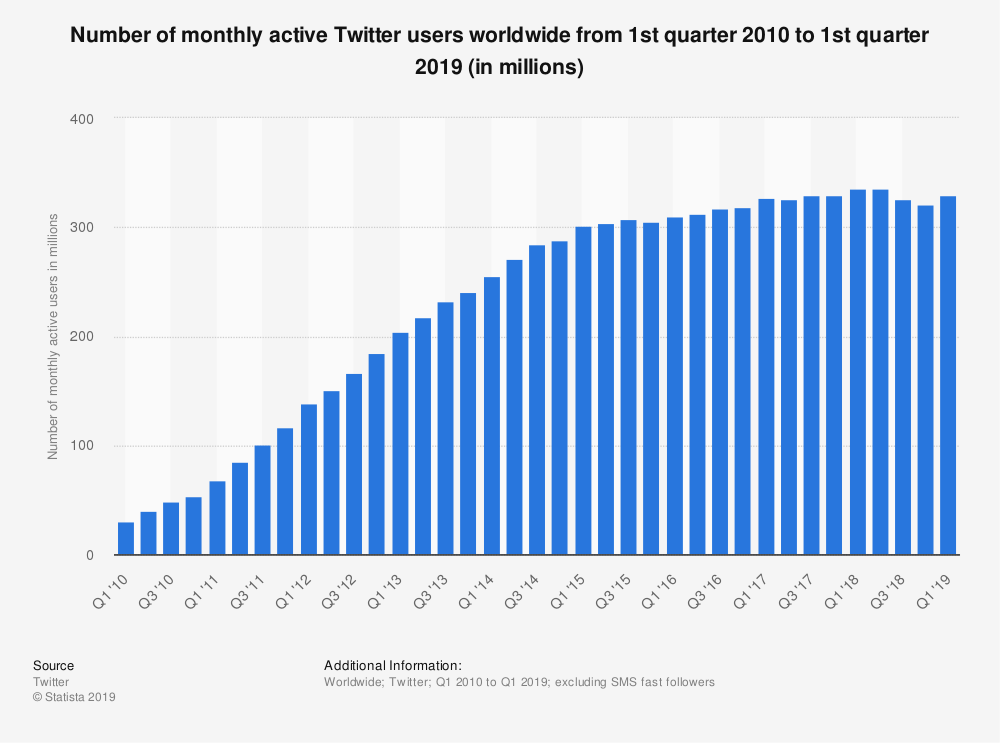
从图表中我们可以看到,Twitter 的 MAU 差不多在 300M,MAU(月活) 与 DAU(日活)的数量根据经验值来讲大约是两倍的关系,因此可以推断出 DAU 为 150M 左右。根据 150M 的 DAU,假设用户每天平均请求的次数为 60 次,可以计算出平均每秒的并发访问量约为:150M * 60 / 86400 = 100 K/s。而通常每日访问的峰值大约在平均每秒并发访问量的 2~9 倍,因此,访问峰值的合理估计数值在 200 K/s ~ 900 K/s 之间。
总结一下,我们大约可以推断出来以下与系统规模相关的数字:
- DAU:150M
- MAU:300M
- 平均每秒并发访问量:300K
- 读 QPS:300K(读一定比写多)
- 写 QPS:5K
当然,以上数字全部都是估计与推断的结果,重要的不是这个推断出来的结果,有时这个推断过程更加重要,言之有理能够给出合理解释即可。但请记住:系统的性能瓶颈由系统中各个部分的最短板决定。
服务 - Service
在这一过程中,我们将会执行上边提到的两步:
- 第一步 - Replay:重新过一下所有需求,为每个需求添加一个或多个服务
- 第二步 - Merge:将相同的服务进行归并
我们可以将新鲜事系统大体上拆分为以下服务,每个服务中会包含场景分析中提到的各个功能:
- User Service(用户服务):
- News Service(新鲜事服务):
- 发布/转发新鲜事
- Friendship Service(好友服务):
- Media Service(媒体服务):
存储 - Storage
存储设计,同样是两个步骤:
- 第一步 - Select:为每个服务选择合适的存储结构
- 第二步 - Schema:细化数据库的表结构
选择合适的存储结构:
- SQL 关系型数据库
- NoSQL 非关系型数据库
- 新鲜事内容(推文、微博内容)
- 文件系统
- 图片/视频
这是一个简单的表结构设计的实例:
- 针对 User Service(用户服务),我们的用户表可以这样设计:

(通常在数据库中存放的密码都经过hash之后的)
- Friendship Service(好友服务)可能会包含如下的关系表结构:

该关系表表示的是from 用户关注了to用户,其中的 from_user_id 和 to_user_id 是 User表的外键关联。
- News Service(新鲜事服务)中用于存储新鲜事的表结构可以这样设计:

扩展 - Scale
关于系统扩展部分的设计将会在接下来的每个具体的 CASE 中进行介绍。
Q1:如何存取信息流(News Feed)/ 时间线(Timeline)?
在新鲜事系统中,最最重要的部分就是信息流和时间线。因为当用户打开微博或者 Twitter 这类软件时,通常的操作就是:
- 打开首页,看看自己关注的用户们都发布了哪些新内容;
- 打开某个用户的时间轴,浏览该用户发布过的内容。
这一 CASE 会从信息流和时间线的数据存储和数据访问入手,来分析、权衡如何设计一个合理的系统。
Solution A:拉模型(Pull Model)
什么是【拉模型】呢?
拉模型是一个主动型的模型。举个例子,当你打开微博查看自己的新鲜事订阅(其他你所关注的用户发的微博)时,系统会先去取出你所关注的的用户列表,再分别把这些你所关注的的用户的时间线上的微博取出来,最终按时间进行归并排序,返回给你所需要的新鲜事订阅。这一流程就属于拉模型。
拉模型这一表述是很形象的,当你需要获取新鲜事列表时,系统是去你所关注(Follow)用户的时间线列表上去拉取到你所需要的新鲜事。
这一算法可以简单总结如下:
- 用户打开新鲜事列表,获取所有关注的其他用户;
- 获取这些用户时间轴中的前 100 条新鲜事;
- 将【2】中取到的新鲜事按时间排序合并成为一个 100 条的新鲜事列表(K 路归并)

复杂度分析:
假设该用户有 N 个关注的用户:
1
2
100 * N 次 DB 读操作 + N 路归并操作
即:100N 次 DB 访问 + 100log(N) 的内存处理操作
通常情况下,内存处理的时间往往要远远小于 DB 访问的时间,因此通常可以忽略不计。在系统设计的考察中,会弱化算法实现的考察,并且算法执行其实在系统设计中,对程序或者系统的执行时间的影响是有限的。
现在我们来分析一下,在【拉模型】下,如果用户发布了一条新鲜事会发生什么:其实在这一模型下,用户发表一条新鲜事是非常简单的,只需要在用户自己的时间轴中插入一条数据即可,也就是进行一次 DB 写操作。
基本伪代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 获取新鲜事列表
function getNewsFeed(request) {
let followings = db.readFollowings(request.user);
let newsFeedList = [];
followings.forEach(f => {
let feeds = db.getTimeLine(f.to_user, 100);
newsFeedList.push(feeds);
});
return K_sort(newsFeedList);
}
// 发布新鲜事
function postNews(request, content) {
db.insertNews(request.user, content);
return "success";
}
但是,这一模型有一个很明显的缺陷:那就是,当用户想要拉取自己订阅的新鲜事列表时,需要执行较多的 DB 操作,而这些操作恰恰也是阻塞的,也就意味着用户需要等待这一系列 DB 操作执行完成,系统才回将新鲜事列表返回给客户端显示出来,相比较而言,用户需要等待较长的时间。
Solution B:推模型(Push Model)
那么,什么又是【推模型】呢?
在推模型下,你可以理解为,系统为每一个用户都维护了一个新鲜事列表,当某个用户发了一条新鲜事,所有关注该用户的新鲜事列表里都会被插入一条该新鲜事;当一个用户查看自己订阅的新鲜事列表时,仅仅需要从自己的列表中取出前 K 条新鲜事就可以了。
算法描述:
- 为每个用户建立一个存储他的新鲜事的列表,列表中只包含他所关注的用户发布的新鲜事;
- 当某个用户发布了新鲜事之后,会将该新鲜事逐个推送至每个关注他的用户的新鲜事列表中;
- 当用户需要查看自己订阅的新鲜事列表时,只需要按时间从该新鲜事列表中取出即可。
复杂度分析:
当用户在刷新自己订阅的新鲜事列表时,只需要 1 次 DB 读取即可。
当用户发一条新鲜事时,情况会稍复杂一些,如果该用户被 N 个用户关注,那么则需要执行 N 次 DB 写入。这一操作的好处是,可以做成异步的,在用户的请求到达服务端之后,服务端可以先返回给用户“已经发送成功”的消息,用户无需等待所有数据插入完成,这一操作可以在系统异步地执行,这一操作有一个名词,叫做【Fanout】。
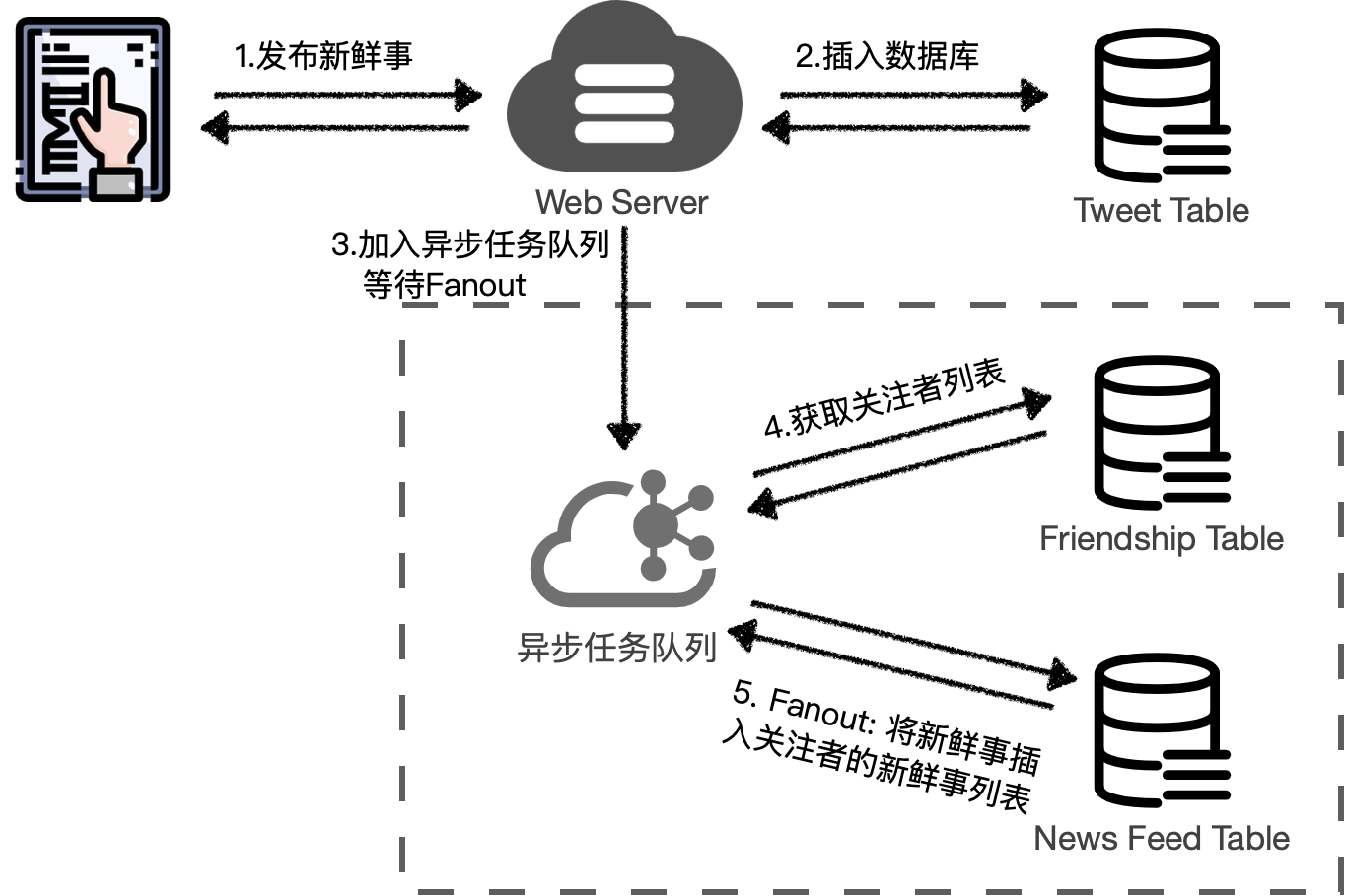
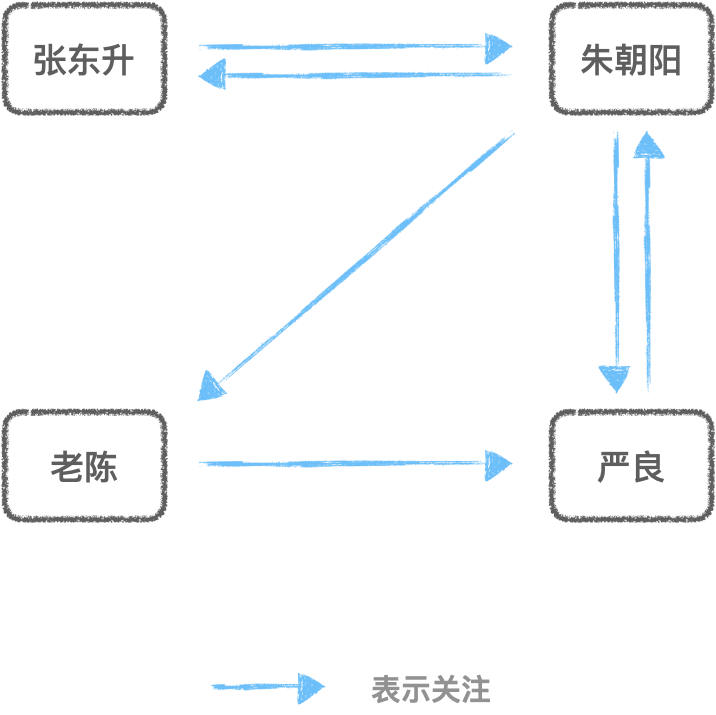
假设现在有四个用户:
张东升、朱朝阳、严良、老陈,他们之间的好友关系如下所示:
- 张东升在 2020 年 06 月 20日 8:30 发了一条新鲜事:“一起去爬山啊!”,此时新鲜事数据库表中数据如下:
- 老陈发了一条新鲜事“今天碰上一个臭小子!”之后:
- 严良发了一条:“我爸爸在哪呢?”:
- 朱朝阳结束了疲惫的一天发了条“终于记完了今天的日记。”:
基本伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 获取新鲜事列表
function getNewsFeed(request) {
return db.getNews(request.user);
}
// 发布新鲜事
function postNews(request, content) {
db.insertNews(request.user, content);
AsyncTask.asyncExec(request.user, content);
return "success";
}
AsyncTask.asyncExec = (user, content) => {
let followings = db.readFollowings(request.user);
followings.forEach(f => {
db.insertNews(f, content);
});
}
缺陷:
- 浪费数据库空间:我们可以看到同一条新鲜事会在数据库表中存储多条(尽管这一问题可以通过在 fanout 的表中,只记录新鲜事 id 来优化,但是相比较而言,这一方案是更浪费数据库存储空间的);
- 新鲜事更新可能会不及时:比如说一个明星有 1M 的粉丝量,整个 Fanout 的过程可能要持续一段时间,有一些粉丝可能已经收到这个明星发布的新鲜事了,但是有的粉丝可能半个小时之后才收到,这是影响用户体验的,一个吃瓜群众肯定是希望第一时间吃到瓜的。
哪种方案更好?
比较两个方案的好坏,首先我们要分别列举出两个方案的优缺点:
方案 优点 缺陷 Pull 模型 1. 设计清晰,实现简单2. 通过机器的横向扩展很容易提升性能
3. …… 1. 拉取新鲜事列表时,DB 操作较多,且是阻塞的
2. …… Push 模型 1. 拉取新鲜事列表时 DB 操作更少,更快
2. …… 1. 浪费空间
2. 不活跃用户会占用大量资源
3. 新鲜事更新不及时,影响用户体验
4. ……
我们从表格中可以看到,这两个方案其实是各有千秋的。但是在实际系统中,往往更多系统设计会选择使用【拉模型】,比如:
- Facebook 使用的是 Pull 模型;
- Twitter 使用的是 Pull 模型;
- Instagram 使用的是 Push + Pull 的模型;
往往完全只使用推模型的例子比较少,这一选择可能往往是考虑到了产品方面的问题,比如说用户体验等。
在实际情况中,如果系统的流量不大,使用 Push 模型是最经济/省力的方法。
在系统设计面试中,对方案之间的比较进行分析与回答是存在一定误区的:
- 切记不能不坚定想法,在几个方案之间来回摇摆:比如说面试官对你提出的 Pull 模型提了一点质疑,指出了缺陷,然后你的回答又摇摆到了 Push 模型,说“那我们选用 Push 模型就好了”。这是错误的回答方式。
- 要展现出 tradeoff 的能力:要针对当前系统设计方案的缺陷去做权衡。
如何优化?
这一部分我们主要讲的是如何针对上述两种方案的缺陷进行优化。这一部分对应的就是 4S 分析法中的【扩展 - Scale】部分,专注于解决设计中的缺陷。
解决 Pull 模型的缺陷
我们来分析一下 Pull 模型可能存在的系统瓶颈(bottleneck),我们会发现这一模型最慢的部分发生在用户请求新鲜事列表时,并且这一过程需要消耗用户的等待时间。
针对这一情况我们可以选择在系统中加入缓存(Cache),在访问 DB 之前加入一个缓存层,如果在缓存中命中了,则直接将数据返回给用户,可以大大缩减用户的等待时间。我们知道,一般缓存是存放在系统的内存中的,对缓存的操作是远远快于操作数据库的。
但是缓存我们该缓存什么呢?是缓存每个用户的时间线呢?还是缓存每个用户的新鲜事列表呢?
- 缓存每个用户的时间线(Timeline):如果我们缓存每个用户的时间线,就相当于把之前的 N 次(N 为关注的好友的个数) DB 请求替换成了 N 次缓存访问,明显是可以提速的。但是,缓存的空间一般是内存,是很宝贵的,是不能存储海量数据的,因此我们就要做出相应的 tradeoff,比如说,每个用户只缓存最新 1000 条或者最新 100 条的新鲜事;比如说,我们还可以将明星、热点用户(用友大量关注者的用户)的缓存长期保存在缓存系统中,不轻易让缓存失效;
- 缓存每个用户的新鲜事列表(News Feed):如果我们来将每个用户的新鲜事列表缓存起来,那么拉取新鲜事列表是就仅仅需要一次 Cache 访问了。针对没有缓存新鲜事列表的用户,归并 N 个关注好友的最新 100 条新鲜事,取出前 100 条放入缓存中;针对已经做了缓存的用户,只需要归并 N 个用户在某个时间之后的所有新鲜事,加入缓存即可。在这一方案中,我们也可以针对不同的用户来做优化,比如说针对经常使用系统、经常频繁刷新新鲜事的用户做优化,将他们的缓存长期存放,对于一些长期不使用的僵尸用户,将他们的缓存清理掉。
提到了缓存,不得不提的就是,由于系统的突然爆发式的访问,造成了缓存的失效该如何处理呢?这就是我们经常会听到的系统雪崩和缓存重建的问题。针对这一问题,我们会在接下来的问题中探讨一些解决的思路和方案。
解决 Push 模型的缺陷
首先,Push 模型有一个缺陷是,浪费数据库的存储空间,但是其实这个并不算问题,因为毕竟当前“Disk is cheap.”。
第二,由于 Fanout 的时间可能会比较长,导致用户有可能在自己所关注的用户发布了新鲜事的一段时间后才能够在自己的新鲜事列表里刷到该条消息。对此,我们可以采用一定的方案来提升用户体验,比如说在 Fanout 的时候先对粉丝按照某种规则进行排序,例如,按照用户的活跃度进行排序(可以按最新登录系统的时间进行排序),针对活跃度越高的用户优先进行推送。
另外,针对某些明星用户或者说热点用户(关注他们的用户数量远远大于他们自己所关注用户的数目),整个 Fanout 的时间可能会很长。解决这一个问题有一个很粗暴的方案,就是增加机器的数量,采用分布式 Fanout 的方案。
Push 模型 + Pull 模型的方案
其实,还有一种方案,是将 Push 方案 和 Pull 方案结合起来进行优化。
比如说,针对普通用户我们采用 Push 的方案;针对明星这类热点用户,我们在系统里进行标记。对于明星用户发布新鲜事,不进行 Push,也就是不将新鲜事 Push 到关注了这一明星的列表里。当用户需要获取自己的新鲜事列表时,到自己所关注的明星用户的时间线上取,并且合并到自己的 News Feed 列表里。
Q2:热点用户(明星)的迅速涨粉/掉粉(摇摆问题)
基于上述针对“明星用户”的解决方案,会引发一个“摇摆问题”。这一问题的描述大致如下:
在系统中我们需要标记为热点明星用户采用不同的策略,例如,在上一问题的解决方案中,对于明星用户的处理方式是,将明星用户进行标记,对于非明星用户使用“Push”的方案,对于明星用户采用“Pull”的方案。这会带来什么问题呢?如果系统定义被关注数量有 1M 以上的用户为明星用户,此时有一个用户的被关注数量为 1M,同时存在大量的用户在点击对该用户的关注/取关,这一用户在系统中就会被频繁的被标记为“明星”/“非明星”用户。于是针对这一类“明星用户”,会在“Pull”和“Push”模型之中来回切换,于是会导致有用户收不到该“明星用户”发布的新鲜事。这一问题被称为“摇摆问题”。
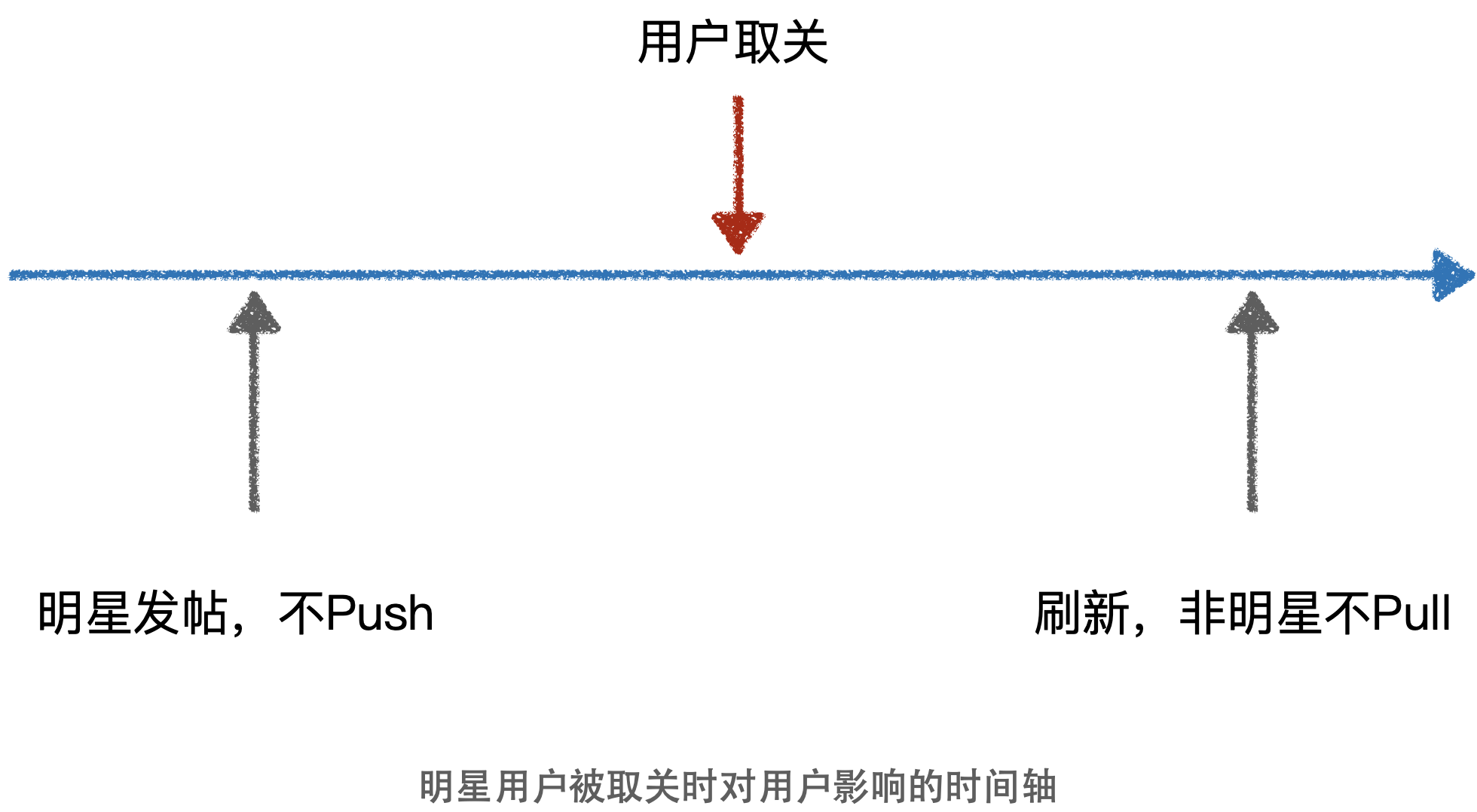
该如何解决这一问题呢?
其实解决这一问题最简单的方法就是,不会动态的对明星用户进行标记。也就是说,用户的关注、取关行为不会立刻影响到该用户会不会被标记为“明星用户”,这一标记过程可以异步使用一个线程,定期来做。
还有另外一种解决思路,是使用一个缓冲地带,比如给用户加入一个“伪明星”的状态,针对这一状态的用户单独处理。
Q3:僵尸粉会带来哪些问题?
我们可以来定义一下“僵尸粉”,该类用户主要表示的是在系统中长期不活跃的用户,但是他们也有许多关注的用户,也会有少量的粉丝。而这种用户有时会给系统带来一些不必要的负载,从而影响到整个系统的性能。
其实,我们在系统设计过程中,可以单独针对这一类用户单独处理。比如,我们在系统中对这些长期不活跃的用户进行标记,系统如果使用的是 Push 模型的话,在 Fanout 的过程中,将该类用户设置优先级,放到该过程的最后来执行。
Q3:如何实现关注(Follow)与取关(Unfollow)?
针对 Follow 与 UnFollow 的实现方案,如果采用的是 Push 模型的话,这里提供一种思路:
- 当一个用户 A 去 Follow 了用户 B 之后:将用户 B 的 Timeline 异步合并到 A 的 New Feed 中;
- 当一个用户 A 去 Unfollow 了用户 B 之后:将用户 B 的 Timeline 异步从 A 的 New Feed 中删除;
采用异步处理的原因是,这一过程可能会比较缓慢,采用异步处理可以迅速给到用户反馈,让用户觉得“似乎已经”关注或者取关完成了。随之带来的问题就是,用户在刷新自己的 News Feed 的时候会发现,可能还会收到自己已经取关的用户的新鲜事。但是终究,该用户的 Timeline 中是会把自己已经取关的用户的新鲜事删掉的。
Q4:明星出轨会带来哪些问题?如何解决?
我们经常可以看到,微博在吹嘘自己技术架构优秀的时候会提到,当前系统支持“八路明星并发出轨”。其实,这一问题就是描述的是,当系统流量非常大的时候,如何来解决系统不可用,或者工作不正常的问题。
这一问题的关键词是:惊群效应、缓存、缓存雪崩、缓存重建。
针对这一问题,我在这篇文章里不会过多进行描述,将会在后续的“数据库与缓存”的主题中进行重点描述。
有兴趣的读者可以先阅读一下这篇 Facebook 发布的非常著名的论文《Scaling Memcache at Facebook》。
Q5:如何查询共同好友?
当你去访问一个 Facebook 的个人页面的时候,Facebook 会告诉你,你和他的共同好友有哪些人。其实,不仅仅 Facebook,QQ空间等社交媒体也有这一功能,包括微博也会有查看共同关注这一功能。我们该如何设计这一功能呢?
常规的思路是:
其实针对这一问题的实际需求,没有一个系统会让你展现出来你所有的好友与你之间的共同好友的,一般的系统可能只会展示出来你和另一用户之间共同好友的 Top10 或者 Top20。基于这一需求来考虑,其实是可以简化系统设计的。
如果每次都去请求好友的好友列表进行一次遍历,复杂度将会是 O(N * max(N,M)) ,N 是这个用户的好友数,M 是他的好友的好友数量,响应时间会比较慢,但是其实是可以提升响应速度而牺牲一点精确度(其实对用户体验的牺牲也并没那么大),因为基于我们的需求其实只需要 TOP10 就可以的,最终结果差别一两名也影响不大。
针对这一方案的话,也是有对应的优化策略的,比如说:
- 每个用户都额外使用一个表来记录与自己共同好友较多的 Top10 用户列表, 每次用户请求 Top10 时直接返回;
- 当新加一个好友时,异步使用上述算法去求两个用户之间的共同好友,并且使用共同好友 Top10 表里面的最少共同好友的记录去比较,看是否需要更新结果。 同时,异步地更新这两个好友的共同好友列表,因为有可能由于这次操作他们直接多了一个共同好友。
还有一个比较暴力的方法,但是也很科学:
比如说,对于 Facebook 来说是有好友上线的,目前的 Facebook 好友上线是 5000。其实针对系统来说,就算把一个用户的所有好友的 id 存放到缓存(比如 Memcached)中的话也只有 80 KB左右,如果计算交集,即便是不使用 HashMap ,计算量的数量级大概在 10^7,系统的计算反应时间也是毫秒级的,其实直接使用缓存系统 + 暴力也是可行的。因为其实查询共同好友这一功能并不是一个非常常用的功能,通常也不会出现缓存雪崩或者缓存失效的情况。
Q6:朋友圈的可见/不可见是如何实现的?
TODO.
这一部分内容其实比较繁琐,需要针对具体业务需求来分析。后续的补充内容应该会针对“微信朋友圈”的策略来做具体分析,敬请关注。
QN:欢迎补充
欢迎大家在文章底部评论(使用的是 Facebook 提供的 Comment 服务,需要科学上网才能留言)里补充问题,或者提供更好的解决方案。我会定期整理放到文章中。
最后,请记住以下要点:
- 问清楚需求再设计,不要一开始就设计一个巨牛的系统;
- 不要做关键词大师,给面试官抛出一堆你自己都不太理解的”专业名词“;
- 不要试图设计一个最牛的系统,要设计一个够用的系统;
- 先设计一个能基本工作的系统,然后再逐步进行优化;
- 系统设计没有标准答案,单纯背答案毫无意义,分析过程比结果更重要;
- 要培养自己通过权衡利弊来设计系统的能力,要把自己的知识储备在分析问题的过程中进行展示。
文章最后,夹带一点私货:
欢迎加入南京第三极区块链科技有限公司,简历请投递至:[email protected]
本文的版权归作者 罗远航 所有,采用 Attribution-NonCommercial 3.0 License。任何人可以进行转载、分享,但不可在未经允许的情况下用于商业用途;转载请注明出处。感谢配合!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK