

百万会员推荐关系优化实战
source link: https://my.oschina.net/jijunjian/blog/4816167
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近,一朋友整天因为CPU 99%搞得茶饭不思,夜不能寐,找到我”诉苦“。听完成,心中一阵窃喜:是时候展现真正的实力了(其实是练手的机会来了)。半推半就应承了下来。

01 分析问题
几分钟了解下来,大概情况如下:会员可以推荐其他用户注册,会员有一个属性--活跃度,用户观看视频,签到等等行为时,这个属性会动态变化,其中有个需求是统计所有下级活跃度。会员模型如下,模型比较简单,使用使用sqlserver 2016。

了解需求后,再来看看占cpu高的查询。其中占cpu 时间最多的就是下面这条sql,查询某个用户所有下级的活跃度之和。这条语句使用递归查询,那是比较耗时的,另外如果层级太多还有如下错误:语句被终止。完成执行语句前已用完最大递归 100。
1 WITH T 2 AS( 3 SELECt DataID, avtivenewss FROM User WHERE DataID = 4167 4 UNION ALL 5 SELECT u.DataID, u.avtivenewss 6 FROM User U INNER JOIN T ON U.parentUserid=T.DataID 7 ) 8 SELECT sum(avtivenewss) FROM T
当前用户1W+。
02 失败的尝试:前缀法
几乎没思考,就想到了一个方法:前缀法。一个用户的所有后代使用同一个前缀。增加一个字段 paths,以用户编号为基础,格式为:/1/2/3/,用户注册时使用记录上级的paths + 上级id 生成自己的paths, 增加paths的索引,这样更具此字段就可以查询我的所有下级了,再写个脚步初始化。非常简单,三下五除二就解决了。上线效果非常明显。

但是好景真短,没两天cpu 又高了。一查,好多查询都没有走索引,明明字段已经加了索引。一看数据,原来是索引长度限制问题。用户居然有好几十个层级,且还在不断增加,长度超过索引最大长度后,索引失效。
当前用户10W+。
04 大胆猜测,小心尝试
会员关系是一棵树,不管怎么遍历,效率都有限。如果把树拉平,用户与所有后代都建立一个关系,性能会怎么样呢。为了避免再次打脸,悄悄的开始了尝试。增加模型tree。
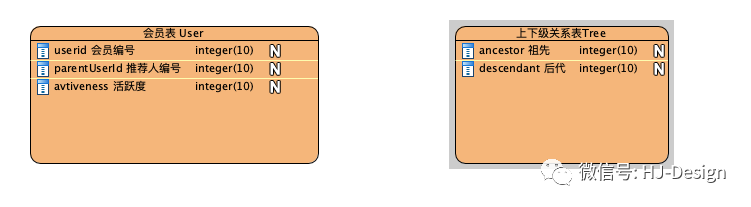
这需要在用户注册时,添加与所有祖祖辈辈的关系。比如 4167用户注册,需要一次添加14条关系记录。而查询用户的所有子子孙孙时,也会非常方便。
编写脚本初始化数据,增加切换开关,战战兢兢的上线了。经过一个高峰,cpu居然都在10%以下,完全没有压力嘛,终于可以亮出脸来了。这是典型的空间换时间。但是高兴之余,心中闪过一个念头--这个表的膨胀速度有点快,它会有极限么。不过,马上被另一个念头压制了:小网站能有多大量!
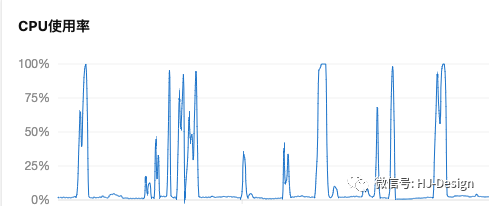
有个什么定律来着:凡事只要有可能出错,那就一定会出错。果不其然,10天后同样的问题再次发生。cpu几乎爆满。只能不停重启,最后干脆下掉了这个统计功能,为此还被怼了一顿。此时关系表总数为10亿。
当前用户100W+。
05 终级方案:分表
其实对于分表这样的事儿,一直都有想过,就是没干过,另外也一直以为是sum()引起的cpu问题。后来咨询了公司做交易的同学,传说他们每天处理2kw的订单,基本思路也是根据用户id分了2048张表。反正也没辙了,撸起袖子搞起来吧。分析了tree 表只有两个查询场景,查用户所有后代及查用户所有祖先。分别以ancestor ,descendant 分256 张表。用户注册时,把关系分别写到个分表中。
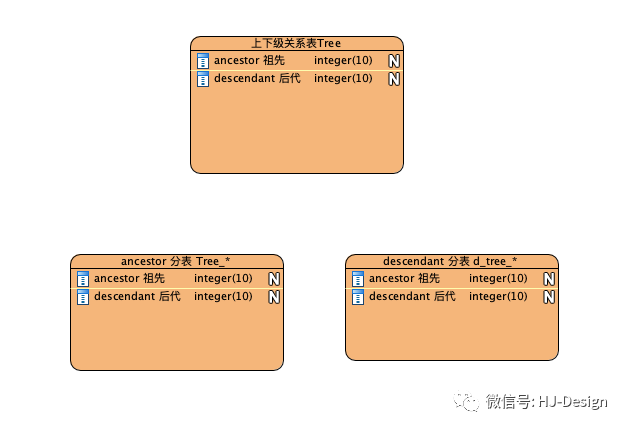
编写脚本初始化两个纬度的分表数据,再次战战兢兢的上线了。经过数个高峰,效果比预期好太多了。彻底告别了cpu告警。
经历了几次失败,早以没了高兴劲儿,心中有个疑问,如果是sum引起的cpu跑满的话,现在sum并没有减少,但是cpu为啥清闲了呢?这背后一定有原因的。
06 刨根问底
带着上面的疑问,对比了一些监控数据,发现了一个可疑的地方,磁盘请求减少了数百次。那么磁盘与cpu有什么样的关系呢?
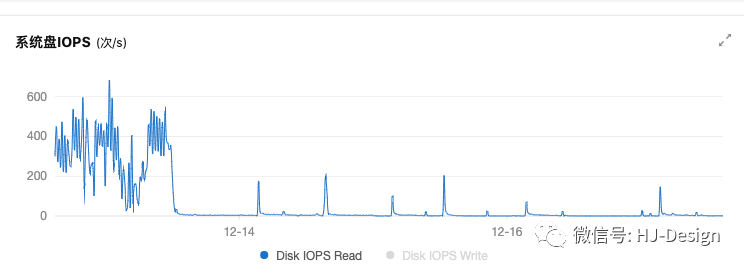
查询相关资料后,得出一个猜测:
未分表前,每次查询所有后代(祖先时)时,因为数据在磁盘上非常分散,page cache 命中率低,磁盘预读失效,所以一次查询要进行很多次磁盘随机读,大量的io操作,cpu就要进行大量的上下文切换,从而导致cpu跑满。
分表后,每次查询所有后代(祖先时)时,每次都在特定的分表中查询,数据在磁盘上非常紧凑,磁盘预读发挥最大性能,page cache 命中率高,io次数据大量减少,cpu上下文切换次数减少,没了压力,cpu自然清闲了。
最后打个广告:哈啰出行,base 杭州, java 我们的部门有大量HC, 欢迎私聊哈。微信:jijunjian
I have a dream to be a good programmer。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK