

How I used Lambda and EFS for massively parallel processing
source link: https://read.acloud.guru/how-i-used-lambda-and-efs-for-massively-parallel-compute-96575bc85157
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
How I used Lambda and EFS for massively parallel processing


Back in October of 2019 (in what seems like another lifetime), Nicki Stone and I presented a talk at Serverlessconf 2019 on solving BIG problems in a Serverless way.
We demonstrated a serverless video encoder that would convert video files from one format to another by splitting the source file into hundreds of smaller files (let’s call them segments), converting these segments in parallel, and then merging them together to produce a new video in a new format or resolution. All of this would be done using Lambda. Without a single server. Quickly.
Our intention with this project wasn’t to compete with solutions like AWS Elemental MediaConvert or Elastic Transcoder. Instead it was to demonstrate how you could take a complex problem and solve it with Lambda by applying principles like MapReduce and parallelization. And, golly, it works.
Calling our project a Serverless Transcoder is so bland and generic. Do you have a better name? Please suggest it in the comments or tweet at me.
Also, I’ll be talking about this in a presentation at the Aussie & New Zealand AWS Serverless Community Day on the 26th of June and the AWS Community Day on the 6th of July. Join me. The tickets are free :)
The original implementation
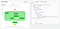
Here’s what the original architecture looked like when we demoed our transcoder:

Our results were pretty decent. This, unoptimised, proof-of-concept transcoder could beat a (boring) large t2 instance (someone rightfully suggested that we should have chosen a c4 instead) and my own 3.5GHz/16GB RAM 2017 MacBook Pro in a number of tests we ran.

It seems crazy that it would take 4320 seconds to convert an 1GB MKV file while only taking 185 seconds with Lambda. However, it makes sense when you realise that ffmpeg would convert the file sequentially on an EC2 while in our system most of the work would happen in parallel.
It should be noted that our proof of concept was and remains unoptimized. I will be releasing the source on Github when the next chapter of this book comes out in preview. If you are interested in helping out, let me know or watch this space.
Challenges with the first version of the transcoder
Nothing is ever easy in this world and there were a few pain points that we had to work through.
Maintaining State
I realised early on that we needed a way to maintain state across the system. We needed to know which segments were created, processed, and merged. We decided to use DynamoDB which was a good choice. In fact, as our first step in the Analyse Video function, we’d precompute metadata for all segments and store them in DynamoDB.
Then we’d track if the appropriate segments were created or merged, ticking off progress in Dynamo. This allowed the engine to know which segments were available, and which needed to be merged next. We also set a TTL on all records so that they would be deleted after a couple of hours (no one likes a database full of old, transient, records).
Managing the workflow
The implementation we presented at Serverlessconf 2019 used SNS and the Fan-Out pattern for most of the work. We’d fan out messages to n² Lambda functions to run the split/encode procedure and similarly we’d fan out messages to Lambdas when the time came to merge segments.
A question we got at the conference was, “why didn’t you use Step Functions together with its Dynamic Parallelism feature”. The Dynamic Parallelism feature was added to Step Functions about a month before Serverlessconf and I hadn’t looked at it in any kind of depth. This feature is actually perfect for the Serverless Transcoder as it allows you to reliably fan-out messages to multiple destinations.
I have now reimplemented our transcoder using Step Functions and it is better than the old SNS approach.
Don’t get me wrong though, there are improvements that I’d make to Step Functions today, like a more robust ability to re-run a failed portion of the workflow. However, on balance, I prefer Step Functions than spawning hundreds of Lambda’s using SNS.
For one, it’s easy to see what’s happening with the system. I can quickly find if a segment has failed to process; I can see and traverse all inputs and outputs. The visibility that I have is worth the price of the effort alone (the dollar cost of Step Functions is another discussion). If you are building a fan-out system, or a Serverless MapReduce, I recommend using Step Functions and Dynamic Parallelism providing you have looked at the costs.
Temporary Files
Our Serverless encoder creates a ton of small files that it processes and merges together. This figurative ton of files needs to be stored somewhere. Our original implementation uses S3. This means that the source file is stored in S3, and all segments are created and stored on S3.
Any time the engine needs to write or read a segment (which is a lot), Lambda has to access S3. It does work and it’s a fine approach but it was a little fiddly to get working especially as I wanted to stream out to S3 rather than save to temporary storage in Lambda (which is only 512MB) and then upload to S3 as two separate steps.
I did think that it would be nice if we had EFS available in Lambda. The Elastic File System can grow and shrink as needed, and it appears like a regular disk so the implementation would be a touch easier (less S3 streaming!).
Enter EFS
Excitingly, the news of EFS support for Lambda was shared with me by folks at AWS and I was lucky enough to get beta access to it (thank you Sushant and Rebecca).
I’ve now implemented the Serverless Transcoder to use EFS as well as S3.Once the source code is available, you’ll be able to choose which storage method to use. I’ll also be doing a bunch of benchmarks and cost estimates. I made a joke at Serverlessconf that I’d ask Corey Quinn to help me calculate the cost of running this transcoder, so maybe I’ll have to call in a favor, Corey ;).
Before we look at EFS in more detail, I want to show you what the Serverless Transcoder architecture looks like now:
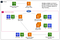
Step by Step with Lambda and EFS
Let me be honest with you, I’ve never really had to use EFS before. I was initially a little disappointed that I’d have to create a VPC and stick all my functions in it, in order to use it. That might be a deal breaker for you and make you want to stick with S3. However, Lambda and VPCs are friends now and the old cold-start issue… is no longer an issue.
As I was using EFS support while in beta there were a few limitations that have now been addressed (e.g. I could only deploy to us-east-1). Overall, it was easy to get up and running with EFS. But, I will say more about performance once I‘ve done more testing. If you are not too familiar with EFS, check out Danilo’s announcement blog; he writes about performance, cost, and security in detail.
By the way, most of what you read next is a manual way of configuring EFS for Lambda. I had to do it this way because, well, it was the main and easiest way of doing during the beta. CloudFormation and SAM now support EFS for Lambda. I am sure Serverless Framework support is coming soon too. Infrastructure as Code is what we should all be using and I encourage you to use IaC everywhere you can.
- I made sure that I was using North Virginia (us-east-1) first.
- Next, I created a new VPC and a bunch of subnets for different Availability Zones. If you have never created a VPC or struggle with subnets check out this course on A Cloud Guru that teaches you everything you need to know.
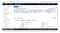
3. Then I opened the EFS console and clicked “Create file system”.
4. From the VPC dropdown I selected my VPC, kept the default settings and clicked “Next”.
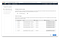
5. On the next screen I kept the throughput mode on Bursting (you need to watch the BurstCreditBalance metric though). Danillo writes that if the BurstCreditBalance metric goes to zero “you should enable provisioned throughput mode for the file system, from 1 to 1024 MiB/s”. Provisioned throughput can be expensive so be careful.
Then, I clicked “Next Step”.
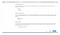
6. On this screen I configured an access point. I decided to use /data but you can use whatever you want (I was told not to use / during the beta). I set the User Id, Group Id, Owner User Id, and Owner Group Id to 1000 and Permissions to 777, and clicked “Next”.
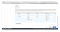
7. Finally, I reviewed my configuration and with a smile on my face clicked “Create File System”.

8. EFS can take a little bit of time to prepare so give it a few moments.
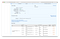
9. While waiting for EFS to create, I ran a brand new deployment of the Serverless Transcoder to us-east-1. I use Serverless Framework so the deployment process was a simple sls deploy (obviously, I hope that you are using CI/CD and not deploying from your workstation).
One thing that I had adjusted in the serverless.yml file were the permissions for my Lambda functions. I added a VPC configuration section to the top-level provider object.

10. Once the Serverless Transcoder was neatly deployed, came the time to connect EFS to Lambda.
I opened the first Lambda function in the Lambda console and scrolled to the File system card.
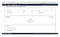
11. I clicked “Add file System”, selected the EFS file system, selected the available Access Point, and then typed in “/mnt/data” in the Local mount path. Having done that I clicked “Save”.
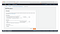
12. Now I could see the EFS file system information, as well as some cool things like the Access point ARN.
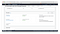
That was it. I was done with the configuration and now had the ability to read and write from “/mnt/data” with my Lambda function.
How the Serverless Transcoder reads and writes EFS
The Serverless Transcoder uses a library called fluent ffmpeg to make ffmpeg easier to use from nodejs. The save() method starts ffmpeg processing and saves the output to a file which in our case is provided by savePath/saveFile variables.
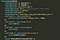
The transcoder also creates temporary directories for storing files which are later deleted after all processing is done.


For all intents and purposes, EFS looks and feels like a local disk in Lambda. Performance and cost considerations aside (and those are very important), having EFS support opens up new possibilities with Lambda. Someone jokingly said that there will be people building databases on Lambda and EFS, although as Ben Kehoe would probably say — that sounds like a terrible idea.
The most useful VPC feature
Your Lambda functions are now in a VPC which means that you must correctly configure Security Groups and NAT Gateways if you want your functions to talk to other AWS services or external endpoints.
But, what’s better than messing around with Security Groups and NAT Gateways? You guessed it — VPC Endpoints! If you need to use services like S3, or DynamoDB, or Step Functions (we are using all of them) then VPC Endpoints can really make your life easy. You can configure them in an instant and not have to worry about changing function code or configuration. Everything continues to work as before.
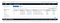
Serverless Transcoder uses S3, DynamoDB, and Step Functions so I created the three VPC Endpoints, and we were up and running.
Was it worth it?
Was it worth implementing EFS support for the Serverless Transcoder? My unsatisfying answer is that it is too early to tell, and that I need to do more testing.
- EFS made the implementation of the Serverless Transcoder simpler and more succinct.
- However, the price and performance of EFS on Lambda is still something that needs to be looked at. S3 is likely to be cheaper whichever way you cut it.
- And, as Ben Kehoe said to me, if you replace S3 with EFS you lose some of the nice cloud-native features of S3 like the ability to view and change contents via the API or the console, the eventing/notification system, and S3 access logs.
EFS creates an opportunity for more applications, and services to run on Lambda than ever before. But, as the old saying goes, you should use the right drill for the right nail. Simply replacing S3 with EFS, just because you can, may not be the right decision. I suspect that for my particular implementation S3 will still be cheaper to run (but I will follow up on this once I have run my tests). Nevertheless, for you and your application it might be different. So, calculate your costs, figure out your throughput needs, and make the right choice.
Hear me say things
Working on this Serverless Transcoder has been exciting. I have certainly learned a lot in the process. On the 26th of June and on the 6th of July I’ll be giving a couple of talks at two incredible (online) community events (I may be slightly biased as I am helping to organise them too).
I hope that you join me and ask questions. If you are keen to learn the things that I’ve described check out our Serverless content on A Cloud Guru, and please never hesitate to reach out and ask me.
Also, if you are an ffmpeg wizard please contact me. I have questions and you have answers. If you can help me, I will be forever obliged.
Finally, let me know what you’d like to see next. Are you interested in EFS performance and cost from the Lambda perspective, or are you interested in Step Functions, or something else? Let me know in the comments below.
And some thanks
Thank you to Sushant Bhatia and Rebecca Marshburn for getting me early access to EFS on Lambda; my co-authors Yan Cui and Ajay Nair, and (again) Sushant Bhatia, Alicia Cheah, and Ben Kehoe who read this piece and gave great feedback.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK