

一次资源泄露问题排查纪录
source link: https://club.perfma.com/article/2022515
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一次资源泄露问题排查纪录
前不久技术学院负责人让我帮助维护下⼤讲堂、积分管理等⼏个系统。这些系统功能都已经很稳定,也不会再有新的功能开发,但是⼤讲堂系统自上线后,每过⼀段时间就会出错,导致学员⽆法报名课程,希望我帮助解决下。这种累积下来的问题解决起来⽐较难,但是对能⼒提升帮助很大,我欣然接受了,所以就有了这次“艰苦”的问题排查和解决之旅。
本人未参加过大讲堂和积分系统的开发,解决问题⾸先要最⼤化的了解系统背景、问题发⽣时的系统表现等信息。技术学院的同事和我说,负责系统的开发⼈员已经换过⼏波了,现在基本已经找不到了解系统的开发⼈员了,但是也反馈了以下信息:
1、系统是16年公司应届⽣培训时做的项⽬。
2、其他系统运⾏良好,就是⼤讲堂系统偶尔会报错,导致学员⽆法报名,重启下就好了,果然是“重启⼤法”好啊。
3、系统出错的频率不⾼,但是貌似很有规律,⼤半个⽉左右出现⼀次。
根据以上描述,特别是出错后“重启⼤法”特别有效,出错频率基本固定,通过这两点基本上可以断定是资源泄露导致的问题。既然确定是资源泄露问题,对于 Java 应⽤来说排查⽅向也就确定为以下2个⽅向:
1、对象泄露
2、线程泄露
3. 处理过程
前文提过本人并未参与项目开发,所以整个排查大部分是通过 linux 和 jvm 的⼀些命令行辅助功能来进行的,下面是整个排查过程:
1、 首先通过 jps 确定 Java 应用的进程 id
sudo -u tomcat jps -lv | grep qtscore

2、 排查内存泄露
通过持续观察 GC 日志文件 /home/q/www/qtscore/log/gc.log 文件,发现 GC 执行频率正常,特别是 Full GC 执行也并不频繁,虽然内存使用量在持续增长,但是并不明显。
为了确认业务代码是否存在泄漏,通过 jmap 查看了堆内对象分布情况,切记此命令会导致进程暂停,如果是 qps 高或者响应时间要求高的应用慎用:
sudo -u tomcat jmap –F -histo 11035
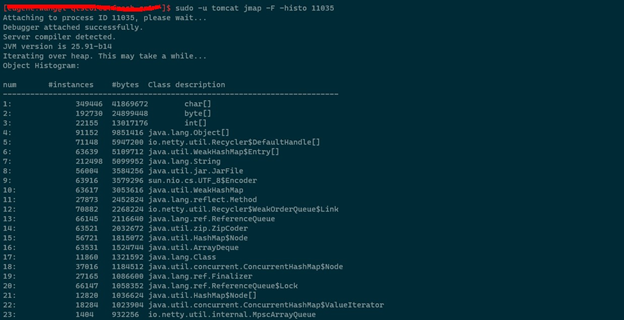
存泄露的可能性。
3、 排查线程泄露
top -H -p 11035
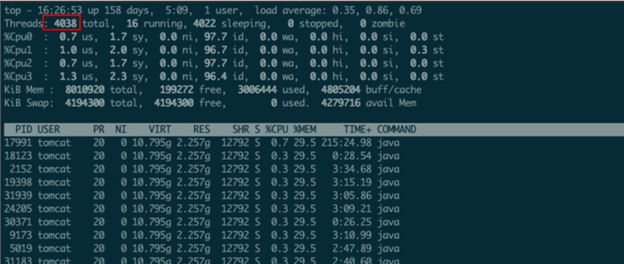
通过结果可以看出线程已经高达4038,应用中dubbo线程池默认配置是200个线程,tomcat线程池配置也是200个线程,所以这个线程数明显不合理。参照另外一个同等应用,其线程数未超过500,所以可以初步判断系统存在线程泄露,下⼀步只能查看线程栈信息了:
sudo -u tomcat jstack -l 11035 > /tmp/qtscore_stack.log
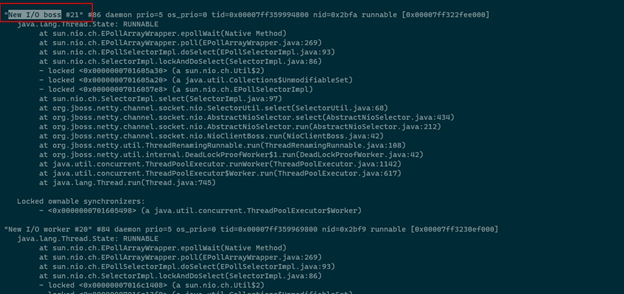
系统中存在100多个“New I/O boss"线程,这个应该是 netty 线程池的 boss 线程,到这里基本上可以确认是线程池泄露引起的问题了,但是究竟是哪段代码引起的,线程栈中并无业务相关代码,只是 netty 线程池的代码,所以无法判断出引起问题的代码源头,只能先看看系统日志中是否有价值的信息了,发现系统日志中频繁报以下错误:
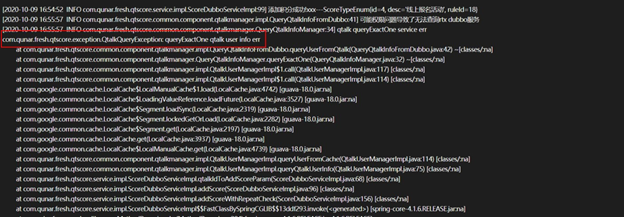
找到对应的源代码进行查看,发现这是⼀个 dubbo 服务接口,而 dubbo 底层用的就是 netty,种种迹象表明问题应该就出在这里。仔细分析代码后,发现这个 dubbo 接口抛出的异常 QtalkQueryException,居然没有通过 api 暴露给调用方,也就是说调用方是无法正确反序列化这个异常的。初步推测可能就是这个原因导致 dubbo 未能正确处理线程池,导致线程池泄露了。将 QtalkQueryException 改为抛出 IllegalStateException 异常,发布上线,满怀期待地等着问题被完美解决。过了一个星期后,通过 top 命令查看进程的线程数,发现线程数又飙升到1千1百多了,看来问题还是没有解决,只能再排查了,但是基本上可以确定是线程泄露问题,而且是 netty 引起的,可是线程栈中 netty 的 worker 线程栈中没有任何业务相关的代码,应该是代码间接用到了 netty 线程池,但是一时没有了头绪。只有找同事咨询一下了,和几个同事讨论后,大家都认为最有可能用到线程池的就是异步请求,特别是一些HTTP客户端,根据这个思路对代码进行排查后,发现系统中有如下代码:

这个 com.ning.http.client.AsyncHttpClient 底层用到了 netty 线程池,这个用法存在明显错误,AsyncHttpClient 实例应该重用,而不应该每次使用时都创建一个。修改代码后重新发布上线,一周后再统计应用线程数,发现线程数稳定在350个左右,确认问题得到了解决。但是故事还没有结束,个人觉得既然应用报错,日志应该有所体现才对,难道是被其他异常淹没了?所以重新排查了出错日期的日志,果然发现了以下错误信息:
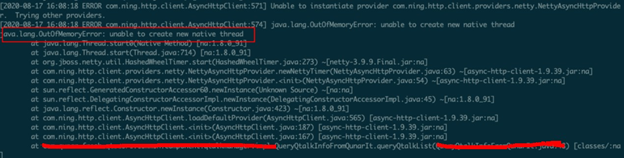
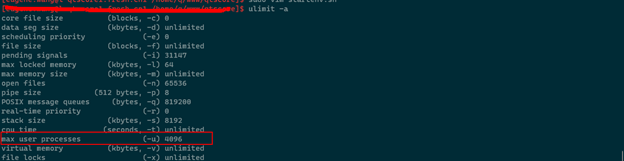
通过系统命令 ulimit –a 发现系统最大用户线程数是4096,所以问题是创建的线程超过了系统最大用户线程数限制。
回顾这次问题排查经历,其实这个问题排查起来并不难,最初的排查方向也是对的,但是整个过程还是花费了很长时间。回顾整个过程,总结出以下经验和教训:
-
大规模使用的基础组件(例如:Dubbo)不容易有问题,即使有问题也会被及时修复,所以还是要多分析自己编写的代码。
-
排查问题首先要仔细分析系统日志,报错的地方⼀般也就是引起问题的源头,遵循和重视这个原则,通常可以大大提高排查问题的效率。
本文来自:Qunar技术沙龙,作者:王彦军
Recommend
-
105
记一次latency问题排查:谈Go的公平调度的缺陷2017-11-19我们有一个对延迟很敏感的模块,这个模块需要访问网络中的另一台机器去取一个时间戳。实现一次分布式事务,需要执行这个操作两次,如果这里拿时间戳慢了,整个事务的延迟就会上升...
-
59
前言 上周五,一同事在开发时遇到了一个问题,叫我帮忙看下.在描述这个同事遇到问题之前,我先简单做一些知识的铺垫,否则不好描述.这里面涉及到的知识点有 Spring的事务传播机制 、 数据库的...
-
42
背景 近期,闲鱼核心应用出现了一个比较难解决的问题。在该应用集群中,会随机偶现一两个实例,其JVM运行在一个挂起的状态,深入分析stack文件发现,此时jvm中有大量的...
-
25
Java小能手21小时前故障案发缘起 网关上线一周以来,运行一直稳定,从未出现CPU飙高的情况。发生故障的当天,CPU开始缓慢上升,但是上升的过程并不是...
-
13
最近遇到应用频繁的响应缓慢,无法正常访问。帮忙一起定位原因,最后定位到的问题说起来真的是很小的细节问题,但是就是这些小细节导致了服务不稳定,真是细节决定成败。这里尝试着来分享下,希望对大家有所帮助。 问题 1:占着茅坑不拉屎遇到...
-
9
上半年,我们将 Redis集群 从旧机房迁移到了服务所在的新机房,迁移过程碰到了一些常见的方法,也遇到一些Key丢失的问题,因此写文章来记录和总结下。 想要平稳顺利的迁移,那么做好准备哦那个工作很重要。最重要的工作就是准备
-
10
K8S 问题排查:cgroup 内存泄露问题 2020-10-22...
-
7
记一次线上问题排查与解决 发表于...
-
7
一次诡异的内存泄露排查过程,背后原因令人深思 ...
-
4
Go应用服务疑似内存泄露问题排查 2023-02-04 约 1767 字 预计阅读 4 分钟 次阅读
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK