

An Interval Type Implies Function Extensionality
source link: https://homotopytypetheory.org/2011/04/04/an-interval-type-implies-function-extensionality/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
An Interval Type Implies Function Extensionality
One of the most important spaces in homotopy theory is the interval (be it the topological interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
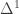
With this in mind, it is natural to define an “interval type” to be inductively generated by two elements and a path between them. The usual sort of inductive types do not allow constructors to specify elements of the path-type of the inductive type, rather than elements of the type itself, but we can envision extending the notion of inductive type to allow this. (Of course, there will be semantical and computational issues to deal with.) I think this idea is due to Peter Lumsdaine.
In general, this sort of “higher inductive type” should allow us to build “cell complexes”, including spheres of all dimensions. But right now I just want to describe the interval type I. It comes with three “constructors” zero:I, one:I, and segment: zero 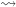

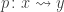
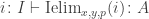
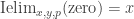
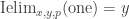
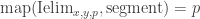
Peter Lumsdaine has “implemented” the interval type in Coq, by asserting I, zero, one, segment, and Ielim as axioms. (See the “Experimental” directory of Andrej’s Github, or Peter’s Github for an older version.) Of course we can’t add new definitional equalities to Coq, but we can assert propositional versions of the computation rules
However, if the above rules are actually definitional, then I claim that the interval type (together with the usual eta rule) implies function extensionality. The idea is quite simple: suppose we have a homotopy 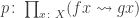
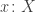

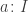
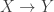
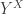
I’ve “implemented” this in Coq, insofar as is possible. The following code uses “admit” to solve two goals that ought to be automatic if the computation rules for the interval held definitionally. (It requires both the base library and Interval.v to be loaded.)
Theorem eta_implies_fe : eta_rule_statement ->
function_extensionality_statement.
Proof.
intros etarule A B f g H.
set (mate := fun (i:Interval) x => interval_path' (H x) i).
path_via (mate zero).
path_via (eta f).
unfold eta, mate.
(* This would be automatic if [interval_path_zero'] were
a definitional equality (computation rule). *)
admit.
path_via (mate one).
exact (map mate segment).
path_via (eta g).
unfold mate, eta.
(* Ditto for [interval_path_one']. *)
admit.
Defined.
53 Responses to An Interval Type Implies Function Extensionality
-
Dan Licata says:
Nice observation, and explanation of it!
A couple of reactions:(1) If you had a quotient type mechanism, then ‘I’ could be defined as a discrete 2-element set (e.g. booleans) quotiented by the complete relation. I can imagine a “higher-dimensional inductive type” being a nice syntax for simultaneously introducing a set and quotienting it, though. On the other hand, then you don’t have a name for the unquotiented set, which you might sometimes want.
(2) Another thing to check (maybe you have already?) is whether you get the right computation rule for the proof of functional extensionality itself. (Now that I think about it, has anyone checked this for the proofs that univalence implies functional extensionality?) That is, you want that the action on paths of functional extensionality computes using the provided natural transformation. In Agda notation, here’s what you’d want to prove:
postulate ext : {A B : Set} {f g : A -> B} -> ((x : A) -> Id (f x) (g x)) -> Id f g compute : {A B : Set} {f g : A -> B} -> (funpath : (x : A) -> Id (f x) (g x)) -> {x y : A} (argpath : Id x y) -> Id (resp2 (\ x y -> x y) (ext funpath) argpath) (trans (funpath x) (resp g argpath))By naturality, the RHS of the equation could be written as the other side of the naturality square (f(argpath) ; funpath y) instead of what I have here (funpath x ; g(argpath)).
-
Mike Shulman says:
(1) Indeed! I also have that hope for a good quotient type mechanism. Conversely, some quotients can be constructed using higher inductive types, but it’s not clear to me that they all can be.
(2) Firstly, isn’t there a simpler way to say the computation rule, without introducing argpath? A path from f to g automatically induces a path from f(x) to g(x) for any x, and we can just ask those paths to be equivalent to the ones we started with. Naturality in x of the equivalence should then imply the statement you gave.
Now as to whether we can prove it from an interval type, perhaps. But actually, I believe Voevodsky has shown that the weak form of function extensionality (the dependent product of contractible types is contractible) implies the strong form (the map from
to
is an equivalence). The “naive” form
that I proved above (or at least its dependent version, which is just as easy to prove from an interval object) implies the weak form, and the strong form in turn implies the computation rule.
-
Dan Licata says:
By the way, here’s an Agda version. First, we define
I : Set zero : I one : I I-rec : {C : Set} -> (fzero fone : C) -> (pres : fzero ≃ fone) -> I -> C seg : zero ≃ one compβseg : {C : Set} -> (fzero fone : C) -> (pres : fzero ≃ fone) -> resp (I-rec fzero fone pres) seg ≃ presThese are defines so that the beta-reduction rules for I-rec on zero and one hold definitionally.
Then the proof is easy:
module Ext (A B : Set) (f g : A -> B) (α : (x : A) -> f x ≃ g x) where lemma1 : (A -> I -> B) lemma1 = (λ x → I-rec (f x) (g x) (α x)) lemma2 : (I -> A -> B) lemma2 = flip lemma1 ext : f ≃ g ext = resp lemma2 segYour restatement of my question about the computation rule is
compute : (x : A) -> resp (\ f -> f x) ext ≃ (α x)
and it’s not immediately obvious to me how to prove it using a direct calculation or anything like that, though what you’re saying sounds like it would work.
-
Mike Shulman says:
Very nice! But my Agda-fu is not quite up to understanding how that works. Firstly, to get your code to compile I had to add lines like
I = {!!} zero = {!!}and so on; otherwise Agda complains about a missing definition. Was that the right thing to do?
Secondly, how exactly are you forcing the beta-reduction rules for zero and one to hold definitionally? Given what you’ve written, I would expect Agda to complain that
map (I-rec fzero fone pres) seg ⟿ pres
is not well-typed.
-
Dan Licata says:
ooops, should have been clearer. That was an excerpt. The prelude that makes it work is
module Interval where private data I' : Set where Zero : I' One : I' I : Set I = I' zero : I zero = Zero one : I one = One I-rec : {C : Set} -> (fzero fone : C) -> (pres : fzero ≃ fone) -> I -> C I-rec fz fo _ Zero = fz I-rec fz fo _ One = fo postulate seg : zero ≃ one compβseg : {C : Set} -> (fzero fone : C) -> (pres : fzero ≃ fone) -> resp (I-rec fzero fone pres) seg ≃ pres open Interval flip : {A B C : Set} -> (A -> B -> C) -> (B -> A -> C) flip f = \ x y -> f y xThe text in the previous comment was the interface that the module Interval satisfies (though this interface is unfortunately not a formal thing in the language, unlike, say, in Standard ML). The idea here is to *privately* define a datatype—i.e. not export it from the module—so that clients of the module cannot use the datatype constructors directly. Instead, they have to use I-rec, which ensures that any function is well-defined on the quotient. However, I-rec itself is defined by pattern-matching, and this definitional behavior *is* exported, so you get the computation rules. The postulate of ‘seg’ would be bad if we screwed up the interface, but because everything the client can do from the outside respects equivalence, it should be safe. Overall, it’s basically a little hack to approximate quotients on the cheap.
-
Mike Shulman says:
I see, thanks. That’s a clever hack, but a bit disappointing; I was hoping for a minute that Agda had some syntax for postulating new definitional equalities. In particular, your hack won’t work to make the beta-rule for “seg” also hold definitionally, will it? It’s convenient, then, that we only need definitional equality for zero and one to get FE.
-
-
-
-
Steve Awodey says:
I like it!
Michael Warren and I worked on adding an “interval type”
to dependent type theory without identity types, the idea being that one can then *construct* the identity types by exponentials:
. A semantics based on this idea has the benefit that it automatically solves all the coherence problems (not just the pullback stability of path-objects, but also Beck-Chevalley for J-terms). We axiomatized such an interval as, essentially, a cogroupoid with a terminal object of coobjects, plus some additional structure; you can find it in Michael’s thesis.
It works in some categories that have such a thing (e.g. Groupoids), but actually getting such a type into the type theory was where we got stuck: the definition of a cogroupoid requires a pushout to type the comultipication
, and that’s not definable, at least conventionally.
The new idea here is to assume that all the Id-types are already there, and then use them to defnite the interval
then we still get some of the benefits, since the higher-dimensional structure is then effectively representable: we can define mapping cylinders, left-homotopies, maybe even cofibrations.
But can we show (1)?
-
Mike Shulman says:
If (1) is just an equivalence of types, then I expect it to be easy and not interesting, since both types should be equivalent to X (I being contractible). The interesting thing about
is its dependency on
, but I don’t see immediately how
can be made similarly dependent.
-
Steve Awodey says:
Of course, (1) is to be understood over
The indexing of
, which give
, whence
.
-
Mike Shulman says:
Of course that gives you a map from
-
Steve Awodey says:
in the models we consider it follows from
-
Mike Shulman says:
Well, yes, but the question in my mind is what we can do in the type theory, not just in the models.
-
Steve Awodey says:
right — that was my question: can we show (1) (over
-
Mike Shulman says:
Okay — so my point was, I guess, that the problem isn’t so much showing (1) (over
-
Steve Awodey says:
since we are assuming Id-types we can for example just set:
.
-
Mike Shulman says:
Okay, but that isn’t really using anything about the interval; it’s just factoring the map
as an acyclic cofibration followed by a fibration. You could replace
.
-
Steve Awodey says:
yes, I agree – if we use the assumed Id-types, we just get fibrant replacements, which is not really saying enough. But without using them there’s no evident way to get a new dependent type over
-
Mike Shulman says:
Yes, that’s true. So maybe an interval can’t really replace built-in Id-types in type theory?
-
Steve Awodey says:
apparently not without a further device to introduce dependency — but as I first said, this was an idea that didn’t work (although it worked fine as a basis for semantics). However — and this was my point — now that we have an idea how to define an interval in the presence of Id-types, perhaps one can at least relate
-
Mike Shulman says:
Ah, I see. I think I misunderstood you at first, sorry.
-
-
-
-
-
-
-
Mike Shulman says:
I don’t see immediately how to define mapping cylinders given just an interval, since we don’t have pushouts. But Peter Lumsdaine also pointed out to me that mapping cylinders can be defined directly as higher inductive types: the mapping cylinder of
is inductively generated by a map
, a map
, and a homotopy
. If you’re more careful, you can construct Mf as indexed over Y, and thereby factor f as a cofibration (= constructor inclusion of an inductive type) followed by a trivial fibration (= display map with contractible fibers). Peter claims that the two factorization systems obtained in this way are actually a model structure (minus the existence of limits and colimits), but I haven’t thought it through myself.
-
Steve Awodey says:
I can see how the constructor inclusions into inductive types could be candidates for generating cofibrations, but having a whole model structure (of course without finite (co)limits) on the category of contexts would certainly be remarkable. Peter, is this really so?
-
-
-
Eric Finster says:
The analogous fact that we could define the circle as essentially BZ (a point with one loop, which then by composition and inversion of paths is just Z, regarded as a one object groupoid) and then get an almost trivial type theoretic definition of the integers by looping it once is maybe the coolest thing I’ve come across in a while, and makes me anxious to see some of this stuff in action.
In analogy with your mapping cylinder, can we do general homotopy pushouts this way as well? Are these the kinds of quotient types you’re referring to, Mike?
It seems like the naive extension would simply allow the target of a type constructor to be any higher identity type, whose “base” was the type being defined. I’d be curious to hear from type theorists if this naive kind of extension is either too weak, or somehow riddled with all kinds of subtleties that I’m not thinking of.
Am I right in saying that the problem with systems like Agda and Coq for this idea is that they don’t treat identity types as first class citizens, but rather leave the user to implement them, like dependent sums? It seems like the system would have to already know about identity types to see that the target of such a higher order constructor was legitimate.
-
Mike Shulman says:
I think the best answer I can give to some of your questions is to point to this blog post which I’ve just written.
(-:Am I right in saying that the problem with systems like Agda and Coq for this idea is that they don’t treat identity types as first class citizens, but rather leave the user to implement them…?
I’m not sure I would say that that’s the problem, but it’s certainly a problem! It’s certainly true that in order for Coq or Agda to support HITs as we’re currently thinking about them, identity types would have to be given a somehow privileged status. (It would be nice if the idea of a HIT could be generalized in some way so as to not require such a privileged status for identity types, but I haven’t yet thought of a way to do that.)
…get an almost trivial type theoretic definition of the integers…
I share your enthusiasm for defining
as a HIT! But I don’t think
is a very good definition of the integers. For instance, it’s kind of hard to define things like multiplication in that way. I think it’s better to define the integers in the usual type-theoretic way as an ordinary inductive type (e.g. containing “positive” and “negative” copies of the natural numbers), and then prove that
. (I’ve actually managed to do that recently, although my code is a bit hairy at the moment, so I want to clean it up before posting it.)
-
-
Pingback: Running Circles Around (In) Your Proof Assistant; or, Quotients that Compute | Homotopy Type Theory
-
Pingback: Higher Inductive Types: a tour of the menagerie | Homotopy Type Theory
-
Bas Spitters says:
Should we expect any relation between the interval type and the interval definable inside type theory? As I understand we have access to quotients, it is indeed possible to really have an internal type [0,1] instead of a setoid.
-
Mike Shulman says:
I think it depends on exactly what sort of “quotients” you have, but in general, yes, I think the interval type should be equivalent to a quotient of Bool by the maximal equivalence relation. (Of course, both are contractible as types, but if the quotient also has a definitional computation rule then it should behave similarly, e.g. for the proof of function extensionality.)
-
-
Bas Spitters says:
I meant: Should we expect a relation between the (homotopic) interval type definable using HIT and the [0,1] as defined inside type theory by Cauchy sequence modulo an equivalence relation.
-
Mike Shulman says:
Oh. Well, I think homotopy types should really be thought of as
-groupoids, not as topological spaces. Any topological space has a fundamental
For instance, probably if we did that correctly, starting from a topological circle (such as by identifying 0 and 1 in [0,1]), we would obtain something equivalent to the HIT circle. And if we did it to [0,1] we would obtain something equivalent to the HIT interval — but in that case both types would be contractible, so the equivalence wouldn’t be very interesting. The only interest in the HIT interval comes from its having two endpoints with definitional computation rules. But I guess depending on how we constructed the quotient set [0,1] and its “fundamental homotopy type”, it might also have that property.
-
Urs Schreiber says:
Here is a belated comment on the above conversation about the two roles of the interval, once as a “geometric 0-type”, once as a “discrete (-2)-type”, or of the circle, once as a “geometric 0-type”, once as a “discrete 1-type”.
These different roles of geometric spaces in homotopy theory, and the transition between them, is what the axioms of “homotopy cohesion” are all about. I have written out some comments about this here:
http://ncatlab.org/nlab/show/cohesive+homotopy+type+theory#GeometricSpacesAndTheirHomotopyTypes
-
-
Peter LeFanu Lumsdaine says:
More directly, though, if we simply mean the usual type [0,1] in the Cauchy reals, then it won’t be equivalent to the interval, since in it, for instance, the points 0 and 1 are provably unequal, whereas the type Interval is provably contractible. Similarly for the abstract “Circle” type vs. the type of points of the “real number” circle.
On the other hand, there should be lots of senses in which the fundamental groupoid of the real circle is Circle. As Mike says, if we had a strong-but-careful enough internal quotient construction, then any space should have a “fundamental type”. Even without that, if one can repeat enough of the construction of the fundamental groupoid, then one should be able to prove that the fundamental groupoid of the real circle is equivalent, as an internal groupoid, to the suspension of ℤ, and hence to Circle considered as an internal groupoid?
To what extent is the algebraic topology of the Cauchy-reals circle understood, by the way? I thought I’d seen a paper at some point constructivising the standard proof, but now I can’t find it, so maybe I was misremembering?
-
Bas Spitters says:
Dear Peter,
There is constructive (and computational!!) algebraic topology in the Kenzo system. In Kenzo spaces are already represented as chain complexes.
Some issues with internal (constructive) homotopy are explained in Erik’s paper which I mentioned above.
The main countermodel to the fan-theorem is recursive mathematics/the effective topos, where one can use the “codes” of a function. In a way, function extensionality tells us that this is not allowed.
I am not sure how this relates to Jaap van Oosten’s homotopy for the effective topos.
-
-
Mike Shulman says:
Bas has asked me to post the following reply for him:
Developing homotopy theory in type theory is not so easy; see
From
intuitionistic to formal topology: some remarks on the foundations of
homotopy theory.Basically, what is missing is the fan theorem/Heine Borel.
This axiom is missing from standard type theory, but I am not sure
about type theory with an interval type. Hence my question. -
Mike Shulman says:
I certainly agree that if you want to construct “fundamental homotopy types” predicatively, then you have to be careful about what sort of thing you take as the input, and there’s a lot of stuff remaining to be done there. Formal topologies do seem likely to be the way to go. I doubt that HITs will make type theory any “less predicative” by themselves, or have any noticeable effect on the theory of sets (0-types) and anything built out of them (like formal topologies).
-
Bas says:
I think the issue is more constructivity than predicativity here.
On the one hand, I came to a similar conclusion about no new theory of “sets”. On the other hand, the interval type makes the interval “representable”, hence we may expect some new theory, but I have not understood whether this can actually be made to work.
-
-
-
Thierry Coquand says:
One can think of the two definitional equalities of Ielim as new computation rules, but they do not seem to give a complete system of computation rules.
One problem is that by adding the new constructorszero : I one : I
segment : Id zero oneone can create, using the J operator over identity type over I, closed non canonical terms (I give two examples below of type N and I respectively).
Let us first fix the notations for the usual elimination rules over the Identity type. If we have C(u,v,p) for u v : I and p : Id u v andd : forall u : I, C(u,u,refl u)
then J d u v p : C(u,v,p) with the computation rule
J d u u (refl u) = d u : C(u,u,refl u)
The question is how to reduce
J d zero one segment
in general.
Here are two examples:(1) if we take C(u,v,p) = N constant family of natural numbers and d u = 0 : N, we get a closed term
J d zero one segment
of type N, which does not seem to be convertible to a canonical natural number with the two definitional equalities of the interval type (which suggests that these are not enough?) What should this term be equal to? What is the semantics of this term in the Kan simplicial set model?
(2) if we take C(u,v,p) = I and d u = u : I, we get a closed term
J d zero one segment
of type I. What is the semantics of this term in the Kan simplicial set model?
In general, is there a natural way to reduce the term
J d zero one segment?
-
Mike Shulman says:
In both of your examples, the type family C is constant, and it is provable that eliminating an identity type into a constant type family doesn’t change the value up to propositional equality (i.e. a path). Therefore, in the first example,
J d zero one segmentis provably related by a path to0 : N, while in the second it is provably related by a path tozero. Assuming sound semantics in the standard model, therefore, these will be their interpretations, up to homotopy. Since N is literally discrete in the standard model, the interpretation of the first term will literally be 0. The second case is less interesting, since the interval is contractible, any two of its points are related by a path (both provably and in the standard model).Of course, this is different from the question of actually reducing them definitionally.
-
Steve Awodey says:
The question, though, is about definitional equality: what do the new terms reduce to. It’s clear that, like all “doppelgängers”, they are propositionally equally to terms that do reduce. But I think we have to come to terms (no pun intended!) with the fact that, when we introduce new types with primitive paths, these will produce (undesirable?) doppelgängers — i.e. propositionally equivalent copies — into other types. Indeed, there will be *lots* of such new terms, because the trick can be repeated ad nauseam. Is this a problem? A bug? A feature? Is there a neat way to kill off these “ghosts”, if that’s what we want to do?
-
Mike Shulman says:
Sure, I agree. But Thierry also asked “what is the semantics of this term in the Kan complex model”, so I was saying that if we know what the terms are equal to are propositionally, then that essentially determines them in the model (or literally, in the case where the type is discrete).
I’m not overly bothered by the presence of doppelgängers; from a homotopy-theoretic standpoint, it’s not a big deal whether you have lots of extra points that are all equivalent to the points you care about. But maybe there are reasons that they are a problem, other than aesthetic ones?
-
Steve Awodey says:
At Luminy, Andre’ Joyal stressed the practical importance of distinguishing between making a useful language for homotopy, and preserving desirable computational aspects of the language. While they are both important, these goals may well differ — and if they do, we may need to fork the development in order to do justice to each. Perhaps this is a such a case?
-
Mike Shulman says:
“Preserving desirable computational aspects” doesn’t sound to me like an end in itself, but rather like something that one would try to do while achieving some other goal. If it’s not possible to perserve desirable computational aspects while providing a useful language for homotopy, then what would be the objectives of a fork which preserves the desirable computational aspects but is not useful for homotopy? That is, what would such a direction be useful for?
-
Steve Awodey says:
for example (perhaps apt, perhaps not): faced with the prospect of adding HITs in a way that seems homotopically natural but computationally questionable, we could go ahead and throw the computational side overboard, or search for a computationally kosher approach that’s perhaps less natural homotopically — or do both, but separately. The point is not to compromise either aspect through being unclear about what the goal is.
-
Mike Shulman says:
Oh, I think maybe I see — there might be a version of HITs which is computationally good and homotopically meaningful, but maybe not as convenient for doing homotopy theory as a different one which is less computationally good? Yes, I agree, we should be open to that possibility.
-
-
Mike Shulman says:
That came out sounding maybe a little more biased than I intended. Of course the type theorists are interested in this stuff because they want to do things with type theory, not because they started out wanting to provide something useful for homotopy theory. I didn’t mean to suggest that I think such a direction wouldn’t be useful, just that I, personally, don’t quite understand what it would be for and how it would be used.
So far, my intuition for where the type-theorists are coming from has been that (some) of their types are “really” homotopy types, and we are only just now realizing that and starting to make use of it. But if the “homotopy type theory” that the type theorists want is not the one that matches homotopy theory, then I’m not sure how to think about it.
By the way, univalence has the same problems, right? It produces paths that “don’t compute” definitionally.
-
Steve Awodey says:
“By the way, univalence has the same problems, right? It produces paths that “don’t compute” definitionally.”
yes, this is a glaring example that cries out for a resolution.
-
Dan Licata says:
Bob and I sketched some of the CS applications in this grant proposal. We’re also working on these computational aspects (as are others).
I think the only “danger” of these more computational presentations, from a homotopy point of view, is that they ask for various equations to hold as equalities, rather than homotopies. And maybe these equations aren’t true (on the nose) in models that you’re interested in? For example, are there models where the type-directed beta reduction rules for ‘subst’ (like ‘subst (_.nat) P’ being the constant function) don’t hold strictly? Are there models where neither of the unit laws for transitivity of paths holds as an equation?
-
Mike Shulman says:
There are certainly things one would like, intuitively, to be models, which aren’t strict in that way. The obvious examples is paths in topological spaces: the composite of a path with a constant path is not exactly the same path, only homotopic to it. In that case, one can find an “equivalent” model using Moore paths for which the unit laws do hold strictly. So the general question is one of coherence: given a natural weak structure, how strict can it be made and remain equivalent?
We know that in general, the answer is not “completely strict” (this is the point of weak n-categories vs strict ones). So I don’t know exactly which laws you want to have hold strictly, but we can’t take all possible laws to be strict.
-
-
-
-
-
Thierry Coquand says:
Thanks for the answer. I should then try to reformulate the question. Does it make sense to ask what is the interpretation of the term
J d zero one segment
in the category of simplicial sets?
-
Mike Shulman says:
I have not digested Voevodsky’s construction of a model in simplicial sets, but I do understand better the construction that works for any well-behaved weak factorization system, as described by Garner and van den Berg. In that context, the weak factorization system is required to be “algebraic” or at least “cloven”, meaning that “being a fibration” or “being a cofibration” is structure on a map, rather than just a property. We additionally have to choose particular factorizations to model the identity types, along with particular structures of cofibration and fibration on the factors. Finally, in order to interpret the interval type, we have to choose not only a type to call “Interval”, but two points of that type to call “zero” and “one” and a point of its path space to call “segment”.
I think that the answer to your question will depend on all of these choices, and there is no canonical answer to all of them simultaneously. (This further supports the argument that the higher structure in an HIT, at least, should only satisfy its computation laws up to homotopy.) For instance, looking at Richard and Benno’s construction, it looks to me as though a point of their “path space” PX of a simplicial-set or topological-space X consists of *three* points x,y,z and paths x ~~> y and y ~~> z. All the factorization structure is then canonical — but if the “interval” is the obvious one, say
to call “segment”: is it (0,0,1) or (0,1,1)? There is no canonical choice, and the interpretation of a term will depend on which choice we make. I think probably if we chose segment=(0,0,1), then
J d zero one segmentwould evaluate to 0, while if we chose segment=(0,1,1), it would evaluate to 1.In a different construction of a model, perhaps the path-space
-
Steve Awodey says:
the issue is more general than the interval, and I don’t think univalence really matters.
whenever we add a new type with non-trivial cells of identity type, we can use those new cells to make copies of completely unrelated existing terms — “doppelgänger” — by id-elim. These don’t reduce to the originals, but maybe they should.
but Thierry’s second example is different: for any type A whatsoever, there is a “generic” id-elim into A as a constant family over Id_A, resulting in a closed term of type Id_A –> A. What is it? The theory is underdetermined.
-
Mike Shulman says:
Yes, that seems right, although the term is of course determined up to homotopy; it’s the projection to either the source or the target of a path (the two choices being, of course, homotopic via the path itself). The answer I gave for the semantics of this term in homotopical models, I think, applies to any type A just as well as to the interval.
-
-
-
Guillaume Brunerie says:
A reformulation of the problem is this :
I agree that it is provable that in the first example,J d zero one segmentis related by a path to0 : N. But in order to prove that, you have to prove first the more general result thatJ d u v pis related by a path to0for everyu, v : I,p : Id u v(by induction onp), and then take the special caseu = zero,v = one,p = segment.
It seems that we *must* do it this way (because we have to do an induction on the pathp), which means that we don’t have cut elimination, which is bad from a computational point of view.
-
-
Leave a Reply Cancel reply
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK