

Homotopy Type Theory should eat itself (but so far, it’s too big to swallow)
source link: https://homotopytypetheory.org/2014/03/03/hott-should-eat-itself/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Homotopy Type Theory should eat itself (but so far, it’s too big to swallow)
The title of this post is an homage to a well-known paper by James Chapman called Type theory should eat itself. I also considered titling the post How I spent my Christmas vacation trying to construct semisimplicial types in a way that I should have known in advance wasn’t going to work.
As both titles suggest, this post is not an announcement of a result or a success. Instead, my goal is to pose a problem and explain why I think it is interesting and difficult, including a bit about my own failed efforts to solve it. I should warn you that my feeling that this problem is hard is just that: a feeling, based on a few weeks of experimentation in Agda and some vague category-theorist’s intuition which I may or may not be able to effectively convey. In fact, in some ways this post will be more of a success if I fail to convince you that the problem is hard, because then you’ll be motivated to go try and solve it. It’s entirely possible that I’ve missed something or my intuition is wrong, and I’ll be ecstatic if someone else succeeds where I gave up.
Recently on the mailing list, I proposed the following problem: show, in HoTT, that the 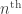
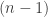
data Expr where Var : nat -> Expr U : Expr Pi : Expr -> Expr -> Expr Lam : Expr -> Expr -> Expr App : Expr -> Expr -> Expr
(This is for a type theory with one universe, with variables as de Brujin indices; don’t worry about the details.) The problem is then to define what it means for such an expression to be well-typed (that should be the easy part) and construct an interpretation function which sends each well-typed raw expression to an actual type (in this case, one living in the second universe).
Why would you want to do that?
This is what Dan Licata asked when I proposed the above problem. In particular, he was asking why you would want to use raw untyped syntax as the input.
What else could you do? Well, recently type theorists have come up with various more highly structured representations of type theory in type theory, which generally “re-use the ambient type-checker” rather than requiring you to implement your own. Chapman’s above-mentioned paper is one of these: he defines contexts, types, and terms by a joint inductive-inductive definition, ensuring that only well-typed things exist — i.e. if something typechecks in the ambient type theory in which the inductive-inductive definition is made, then it is automatically well-typed in the object theory as well. The definitions start out something like this:
data Context where Empty : Context _,_ : (G : Context) -> Ty G -> Context data Ty : Context -> Type where U : (G : Context) -> Ty G Pi : (G : Context) (t : Ty G) -> Ty (G , t) -> Ty G El : (G : Context) -> Tm G U -> Ty G data Tm : (G : Context) -> Ty G -> Type where ...
In other words, a context is either empty or the extension of an existing context by a type in that context; while a type is either the universe, a dependent product over a type in some context of a type in the extended context, or the type of elements of some term belonging to the universe. (I’m using Type for a universe in the ambient theory, and Ty for the dependent type (in the ambient theory) of types (in the object theory) over contexts. It’s not really as confusing as it sounds.)
This is an “inductive-inductive definition”, meaning that (for example) the type family Ty is dependent on the type Context, while both are being defined at the same time mutually-inductively. Coq doesn’t understand such definitions, but Agda does. (What I’ve written above isn’t quite valid Agda syntax; I simplified it for clarity.)
The advantage of something like this is that if you try to write something nonsensical, like App U (Lam (Var 100) U), then the ambient type checker (e.g. Agda) will reject it — whereas such gibberish is a perfectly good inhabitant of the type Expr above, that has to be rejected later by an typechecker you write. So why not use a representation like this?
I have several answers to this question; let’s start with the most philosophical one. I argue that if homotopy type theory is to be taken seriously as a foundation for all of mathematics, then in particular, it must be able to serve as its own metatheory. Traditional set theory, for instance, is perfectly capable of serving as its own metatheory: one can define the set of well-formed first-order formulas in an appropriate language, and prove in ZF that (for instance) any set-theoretic Grothendieck universe is a model of all the axioms of ZF. One can also construct “nonstandard” models such as forcing extensions (i.e. sheaf toposes). The same must be true of homotopy type theory; if it is to be a foundation for all of mathematics, it must be able to accomplish something analogous. (From a CS point of view, the corresponding point is that any general-purpose programming language must be able to implement its own compiler or interpreter.)
Now I would argue that to be completely satisfactory, this “serving as its own metatheory” must go all the way back to raw syntax. Why? Well, whether we like it or not, what we write on paper when we do mathematics (and what we type into a proof assistant as well) does not consist of elements of a highly structured inductive-inductive system: it is a string of raw symbols. (It’s actually even “more raw” than Expr is, but I’m happy to regard parsing and lexing as solved problems in any language.) The process of type-checking is part of mathematics, and so an adequate metatheory ought to be able to handle it.
I have other, more pragmatic, reasons to care about solving this problem. One of them is that we need a better handle on how to construct “nonstandard” models of HoTT, and being able to construct a “standard” model internally might give us a leg up in that direction. Also, again if HoTT is to be a foundation for all of mathematics, then it must be able to construct its own nonstandard models as well. However, none of that is what originally started me thinking about this problem.
Semisimplicial types
The problem of defining semisimplicial types, and more generally of defining and working with coherent structures built out of infinitely many types, is also one of the most important open problems in the field. It’s particularly tantalizing because it’s easy to write down what the type of n-truncated semisimplicial types should be for any particular value of n. Here are the first few:


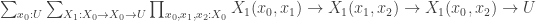
In fact, as Peter Lumsdaine has pointed out, it’s so easy that a computer can do it. I believe he even wrote a Haskell program that would spit out the Coq syntax for the type of n-truncated semisimplicial types for any n you like. But if we can do this, then with only a little extra effort (to prove termination) we should be able to write that same program inside type theory, producing an element of Expr. Therefore, if we could solve the problem I’m proposing, we ought to be able to solve the problem of semisimplicial types as well! Surely that’s reason enough to be interested in it.
What’s the big deal
So why is this problem hard? On the surface, it may seem like it should be completely straightforward. For instance, we could define predicates for validity of contexts, types-in-context, and terms-of-types-in-context, either inductively or recursively:
IsCxt : List Expr -> Type IsTy : List Expr -> Expr -> Type IsTm : List Expr -> Expr -> Expr -> Type
and then define our mutually recursive interpretation functions with a hypothesis of validity:
icxt : (G : List Expr) (JG : IsCxt G) -> Type1 ity : (G : List Expr) (JG : IsCxt G) (T : Expr) (JT : IsTy G T) -> (icxt G JG -> Type1) itm : ...
However, this is not as easy as it sounds, because of substitution. For instance, when is Var 0 a valid term, and what is its type? We are using de Brujin indices, which means that Var 0 denotes the last variable in the context. This variable of course has a type assigned to it by the context, which must be a valid type T in the context of all the preceding variables. The type of Var 0 must be this “same” type T, but now in the whole context (including the last variable of type T). With de Brujin indices, this means that the type of Var 0 is not literally T, but a “substitution” of it in which all the indices of variables have been incremented by one.
Therefore, our definitions of validity must refer to some notion of substitution. (This is true whether or not you use de Brujin indices; consider e.g. the type of App.) Substitution could either be an operation defined recursively on Expr, or represented by an extra constructor of Expr (“explicit substitutions”). But in either case, when we come to define the interpretation of Var 0 or App, we’ll need to know how the interpretation functions behave on substitutions: they ought to take them to actual composition with functions between the (ambient) types that interpret the (object) contexts.
Okay, fine, you may say (and I did): let’s just prove this as part of the mutual recursive definition of the interpretation functions. But I found that when I tried to do this, I needed to know that the interpretation functions also took composites of substitutions to composites of maps between types. At this point I stopped, because I recognized the signs of the sort of infinite regress that stymies many other approaches to semisimplicial types: in order to prove coherence at the 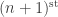
Why I should have known it wouldn’t work
When we build models of type theory in a set-theoretic metatheory, we do it by showing that from the syntax we can construct a certain algebraic structure which is initial, and that from our desired semantics we can construct another structure of the same type; the unique map out of the initial object is then the interpretation. I think it’s fair to say that morally, the attempted internal interpretation I described above is doing something similar inside type theory: we haven’t made the universal property explicit, but our ability to define a certain collection of functions by mutual recursion amounts to more or less the same thing.
Now in set theory, the algebraic structure we use is strict and set-level. In particular, it is fully coherent, because all coherence properties we might want hold on the nose, and so any higher axiom we might impose on those coherences also holds on the nose, etc. The syntactic structure is automatically strict and set-level by definition, but the semantics are not: the fact that they can be presented that way (e.g. an 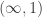
In type theory, it is no longer reasonable to expect to be able to present the desired semantics by a strict set-level structure. For instance, in general the universe need not admit any surjection from a set. However, the structure built out of syntax is still strict and set-level. Thus, in order to define an interpretation, we need a different sort of “coherence”. An inductive definition of the syntax allows us to sidestep the questions of what exactly this coherence might say and of what exactly the universal property is, by telling us directly what functions we can define by recursion. However, because the syntactic structure is in particular fully coherent (because it is set-level and strict), we shouldn’t expect to be able to define an interpretation except into another structure that is also fully coherent.
Now the ambient universe certainly is fully coherent. However, without already having something like semisimplicial types at our disposal, we don’t know how to express that fact. And therefore, we should expect to have a hard time doing anything which needs to use its full coherence — such as defining an interpretation of raw syntax.
I realize that this explanation is very hand-wavy and may not be convincing. If you aren’t convinced, please try to prove me wrong! I would be very happy if you succeed. But first allow me to bend your ear a little more with my failures. (-:
Structured syntax as a bridge
Rather than trying to go directly from raw syntax to the universe, we might try to use one of the structured inductive-inductive kinds of syntax I mentioned above as a stopping point halfway. This requires us to delve into the “…” I placed in the definition of the family Tm, which turns out to be surprisingly subtle, for the same reason as above.
Specifically, the constructors of Tm such as Var and App must involve a notion of substitution, and as before there are two obvious choices. We could make substitution an operation, in which case it must be defined inductive-recursively with the types Context, Ty, and Tm. Or we could make explicit substitutions a constructor of Ty and Tm, which keeps the definition merely inductive-inductive (though it requires adding a new type Sub of substitutions alongside Context, Ty, and Tm). Chapman’s paper that I already mentioned does the latter, while Danielsson did something closer to the former in a paper called A Formalisation of a Dependently Typed Language as an Inductive-Recursive Family (he actually only made substitution an operation on types, keeping it as a constructor for terms).
Dan Licata pointed me to a sneaky third option due to Conor McBride in a paper called Outrageous but Meaningful Coincidences, in which the syntax is essentially defined inductive-recursively together with its standard interpretation. This allows the object-language substitution to coincide with the actual notion of substitution in the ambient type theory.
As far as I can see, however, none of these can bridge the full gap from raw syntax to the universe. I admit that I haven’t tried McBride’s version; however, it seems so close to the universe itself that I would expect to have the same sort of problems as before. But it could be that something magical will happen, so it would be great if someone would try it. (It won’t be me, at least not in the near future; I’ve already used up more free time than I actually had in messing around with this stuff and in writing this blog post.)
I also didn’t manage to completely define an inductive-recursive version of type theory that does away with explicit substitutions entirely. As Danielsson notes in his paper, this is quite tricky because you have to prove various properties of the substitition operations as part of the inductive-recursive definition. In fact, I found myself wanting to include an encode-decode proof for the whole system as part of the inductive-recursive definition, in order to show that all the types were in fact sets! I didn’t complete the definition, but it may very well be possible to do. But the reason I gave up is that I decided it would almost certainly suffer from the same problem as the raw syntax: it would be set-level and strict, and so interpreting from it into the universe would require us to know and express the full coherence of the universe. (Also, I’m still wary of induction-recursion; I don’t think we know whether it is consistent with univalence.)
I think that what happens with Chapman’s inductive-inductive theory is most interesting and instructive. The situation here seems to depend on what you decide to do about judgmental equality. Chapman includes separate families for it in the inductive-inductive definition, i.e. in addition to Context, Ty, Tm, and Sub we have
data TyEq : (G : Context) -> Ty G -> Ty G -> Type data TmEq : (G : Context) (T : Ty G) -> Tm G T -> Tm G T -> Type
and perhaps one for context equality too. (Chapman actually uses a “heterogeneous” version, which has some advantages, I guess, but is harder to make sense of homotopically.) These families have a lot of constructors, representing all the usual judgmental equalities of type theory, and also things like symmetry, transitivity, and reflexivity, and that all the constructors of the other types respect judgmental equality. Finally, we have to include new constructors of Tm (at least) which “coerce” a term belonging to one type into a term belonging to a judgmentally equal one.
This definition has a setoidy feel to it, and so a homotopy type theorist may naturally think to try replacing it with a higher inductive-inductive definition, where instead of introducing new type families for judgmental equality, we re-use the (propositional) equality of the ambient theory. Now the previous constructors of TyEq and TmEq become path-constructors of Ty and Tm. Moreover, we can omit a lot of them completely, since actual equality is automatically reflexive, symmetric, and transitive, and respected by all operations. Similarly, we don’t need new constructors for coercion: it’s just transport.
Obviously the second option is attractive to me. I particularly like that it matches exactly what the Book says about judgmental equality in the introduction to Chapter 1: it’s the equality of the metatheory. However, the first (setoidy) has the advantage of existing in Agda already without postulates and thus being executable. But I think both have the same underlying problem.
For the HIIT approach, the problem is summed up by the question: are the types Context, Ty, and Tm h-sets? If we just blindly add path-constructors for every standard judgmental equality, the answer is surely not. Consider, for instance, the functoriality of explicit substitutions, which must be ensured by a constructor of judgmental equality. If the types in question were naturally h-sets, then this functoriality would be fully coherent, but there’s no reason this should be true without adding infinitely many higher-dimensional path-constructors to ensure it. (We can formulate the same question in the setoidy approach either by adding more and more “iterated” judgmental equality families, or by adding “higher coercion” constructors to the existing ones.)
On the other hand, we could add truncation constructors to force the types to be sets. (In the setoidy approach, we could do this by asserting that coercions along any two parallel equalities are equal.) This is more like what we do in the set-theoretic approach to semantics: the category of contexts is built out of syntax quotiented by the mere relation of judgmental equality. This would in particular make them fully coherent — but at what cost?
Consider what happens when we come to define an interpretation into the universe of the ambient theory. Most of it is straightforward: we use the induction principle of the inductive-inductive definition to define mutually recursive functions
icxt : Context -> Type1 ity : (G : Context) -> Ty G -> (icxt G -> Type1) itm : (G : Context) (T : Ty G) -> Tm G T -> ((x : icxt G) -> ity G T x)
In particular, by the recursion principle for higher inductive types, the clauses of these definitions corresponding to the path-constructors giving the judgmental equalities of the object theory must interpret them as propositional equalities in the ambient theory. (With the setoidy approach, we would define separate mutually recursive functions on TyEq and TmEq that do this interpretation.) However, if we included truncation constructors, then we’re sunk, because the universe is not a set. In set-theoretic semantics, we can get away with truncation by using a strictification theorem saying that the desired target universe can be presented by a set-level structure (e.g. a model category), but inside HoTT this is not true.
If we leave off the truncation constructors, then we’re basically okay: we do get an interpretation into the universe! (There’s an issue with domain and codomain projections for equality of Pis in the setoidy approach, but I think it can be dealt with and it’s not relevant to the point I’m making here.) Now, however, the problem is on the other side, with the interpretation of raw syntax into the structured version. When we write raw syntax on paper, we don’t ever indicate which judgmental equality we are coercing along. So although this isn’t by any means a proof, it seems (and my own experiments bear this out) that we’re going to get stuck either way.
Of course, I am aware that Vladimir has proposed a type theory in which judgmental equalities are indicated explicitly. But I have yet to be convinced that this is practical, especially if one admits the possibility of distinct parallel judgmental equalities. I strongly suspect that in practice, we constantly identify terms that are “actually” coercions along different-looking judgmental equalities. My evidence for this comes from my attempts to interpret raw syntax into inductive-inductive syntax, and also from something else I tried (in fact, the first thing I tried): defining directly the inductive-inductive syntax for semisimplicial types without going through raw syntax. In both cases I found myself needing higher and higher coherences for functoriality.
Of course, if we already knew how to solve the problem of infinite objects (such as, for instance, by having a useful theory of semisimplicial types), then we might be able to actually put all the higher coherences into the inductive-inductive definition. I would hope that we could then prove that the types involved were h-sets, and then use that to interpret the raw syntax.
So in conclusion, my current impression is that solving this problem is about equally hard as solving the problem of infinite objects. But I would love to be proven wrong by a solution to the problem of interpreting raw syntax!
Postscript: which equalities can be made judgmental?
Recall that the interpretation functions of inductive-inductive syntax map judgmental equality of the object theory to propositional equality of the ambient theory. In particular, any equality which holds propositionally in the ambient theory can be made to hold judgmentally in the object theory, by simply adding a path-constructor for it, with an appropriate clause in the interpretation function mapping that constructor to its ambient propositional version.
This may seem to suggest that the answer to the question of “what propositional equalities can be made judgmental” is “all of them!” However, remember that in order to interpret raw syntax, we probably need the inductive-inductive syntax to consist of h-sets, and throwing in new path-constructors has a way of destroying such properties. So the answer is really, “anything which holds propositionally, and can be proven to be fully coherent with all the other judgmental equalities”.
The relationship of this answer to the one provided by traditional set-theoretic semantics is, roughly, the same as the relationship between the two kinds of coherence theorem in category theory: one which says “all diagrams (of a certain form) commute”, and one which says “every weak structure is equivalent to a strict one”. In set-theoretic semantics, where judgmental equality is interpreted by on-the-nose equality in a strict structure (such as a contextual category), in order to add new judgmental equalities we need to prove a coherence theorem of the second sort, showing that they can be modeled strictly. But in the native HoTT semantics that I’m hoping will exist, we can add new judgmental equalities by proving a coherence theorem of the first sort. Category-theoretic experience suggests that the first sort of coherence theorem is more general and useful; for instance, there are contexts in which “all diagrams commute” in an appropriate sense, but not every weak structure is equivalent to a strict one.
Finally, I think this gives a very satisfactory answer to the philosophical question of “what is judgmental equality?”. The judgmental equalities are just a subclass of the (propositional) equalities which we’ve chosen, by convention, not to notate when we transport/coerce across them. But in order for this to be consistent, we need to know that no real information is lost by this omission; and this is the requisite coherence theorem.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK