

[Reading] Xception: Deep Learning with Depthwise Separable Convolutions
source link: https://blog.nex3z.com/2020/09/02/reading-xception-deep-learning-with-depthwise-separable-convolutions/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

[Reading] Xception: Deep Learning with Depthwise Separable Convolutions
Author: nex3z 2020-09-02
Contents [show]
Xception: Deep Learning with Depthwise Separable Convolutions 一文提交于 2016/10,文章受 Inception 启发,使用深度可分离卷积替换了 Inception module,构造了 Xception 网络架构,在 ImageNet 数据集上的性能略优于 Inception V3,在 JFT 数据集上的性能大幅优于 Inception V3。
2. 极限的 Inception 模块
传统的卷积层使用三维的过滤器,包括两个空间维度(宽和高)和通道维度,同时对空间和通道间的相关关系进行映射。而 Inception 模块则尝试将这一过程分解为一系列操作,独立地对空间的相关和通道间的相关分别进行处理。如 Figure 1 所示,Inception 模块首先通过 1×1 卷积处理通道间的相关,然后将输入数据分成 3 到 4 个较小的空间,然后使用如 3×3 或 5×5 的卷积来处理这些小空间中的所有相关关系。Inception 的基础假设是,通道间的相关和空间的相关能够充分解耦,最好不要同时映射。

Figure 1, 2
Figure 2 所示的简化的 Inception 模块移除了池化,可以将此种结构看成是一个大的 1×1 卷积,将其输出分成若干个不重叠的区段,作为后续一系列空间卷积的输入,如 Figure 3 所示。由此引出两个问题:分段的数量和每段的尺寸对性能有什么影响,以及是否可以提出一个更强的假设:通道间和空间的相关可以完全独立地进行映射。由此文章提出了一个极限版本的 Inception 模块,1×1 卷积输出的每个通道都有一个单独的空间卷积进行处理,如 Figure 4 所示。
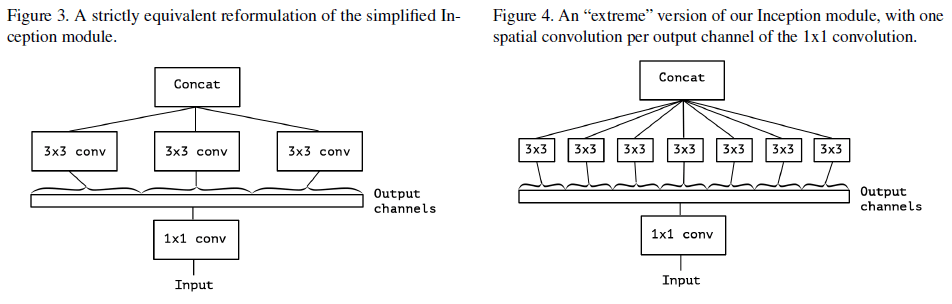
Figure 3, 4
Figure 4 所示的结构和深度可分离卷积相似,二者有两点差异。
- 层的顺序:深度可分离卷积先进行逐通道的空间卷积(depthwise 卷积),然后进行 1×1 卷积(pointwise 卷积),而 Inception 先进行 1×1 卷积。在实际网络中,通常会堆叠使用相同的结构,这两种卷积的顺序是相对的,因此这一顺序差异并不重要。
- 第一个操作后是否使用非线性:深度可分离卷积中通常不使用非线性,而 Inception 在两个操作后都会使用 ReLU。
通过调整分段的数量,可以得到不同的 Inception 模块,构成了一个离散的谱系。一个极限是只有一个分段,即在 1×1 卷积后只使用一个常规卷积;另一个极限是每个通道一个分段,即深度可分离卷积。常规的 Inception 模块位于中间,使用 3 到 4 个分段。文章认为,通过将 Inception 模块替换为深度可分离卷积,即使用深度可分离卷积堆叠,可以提升 Inception 系列网络的性能。
3. 网络架构
文章基于特征图中通道间和空间相关的映射可以完全解耦的假设,提出了一个完全基于深度可分离卷积的网络架构,如 Figure 5 所示。这一假设比 Inception 的假设更强,因此将网络命名为 Xception,表示“Extreme Inception”。网络主要由线性堆叠的深度可分离卷积和残差连接组成,非常简单。
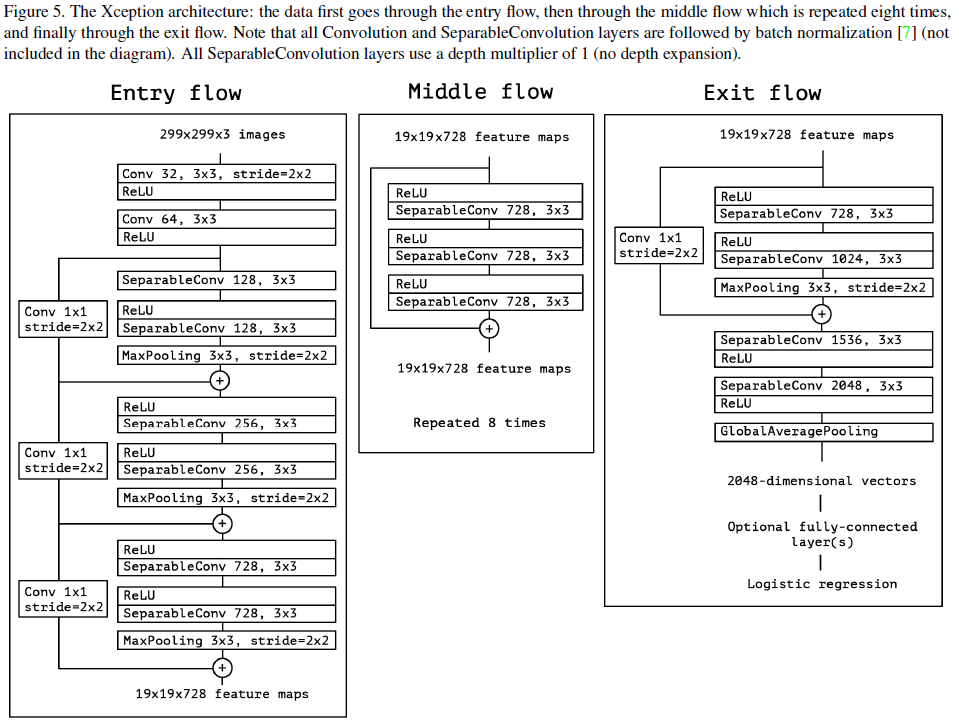
Figure 5
4. 实验结果
文章主要在 ImageNet 和 JFT 数据集上,对 Xception 和 Inception V3 这两个参数数量相近的网络进行了比较。JFT 数据集包含 3.5 亿张图片和 17000 个分类,对应的验证集 FastEval14k 包含 14000 张图片和 6000 个分类(平均每张图片有 36.5 个分类),计算前 100 个预测的 mAP,并使用类别在社交媒体图片中的常见程度进行加权,来评价对社交媒体中常见类别的识别性能。
Xception 和 Inception V3 在 ImageNet 和 JFT 上的性能分别如 Table 1、2 所示,训练过程如 Figure 6、7、8 所示。可见 Xception 在 ImageNet 上的性能略优于 Inception V3,而在 JFT 上较 Inception V3 的性能提升更大。文章认为这是因为 Inception V3 是针对 ImageNet 开发的,因此过拟合于 ImageNet。通过对超参数进行调优,Xception 在 ImageNet 上还可以获得更好的性能。

Table 1, 2
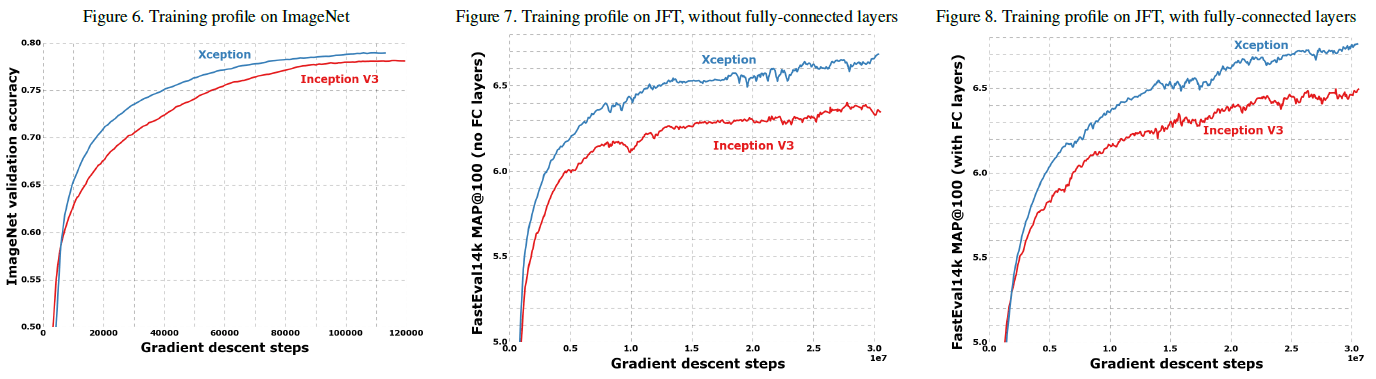
Figure 6, 7, 8
Table 3 比较了 Xception 和 Inception V3 的参数数量和每秒钟训练的步数,可见二者参数数量接近,但 Xception 稍慢。文章认为未来对 depthwise 实现上的优化可以进一步提高 Xception 的速度。
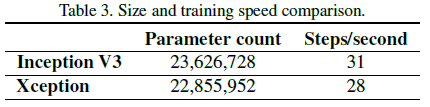
Table 3
为了验证残差连接的影响,文章对比了带残差连接和不带残差连接的 Xception,结果如 Figure 9 所示。可见残差连接对收敛非常重要,可以提升收敛速度和分类性能。同时文章也指出,这一结果只是说明残差连接对特定网络架构非常重要,并不意味着它是必须的。

Figure 9
为了验证 pointwise 卷积后激活函数的影响,文章对比了使用不同激活函数和不使用激活函数的网络的性能,如 Figure 10 所示。可见不使用激活函数可以获得更快的收敛速度和更高的准确率,这一结果与 Inception V3 中的结果相反,文章认为是中间特征的深度,即空间卷积输入的通道数决定了非线性的作用,对于如 Inception 模块这样较深的特征空间,使用非线性是有益的;而对于如深度可分离卷积这样较浅的特征空间,空间卷积的输入只有一个通道,信息较少,使用非线性会带来损害。
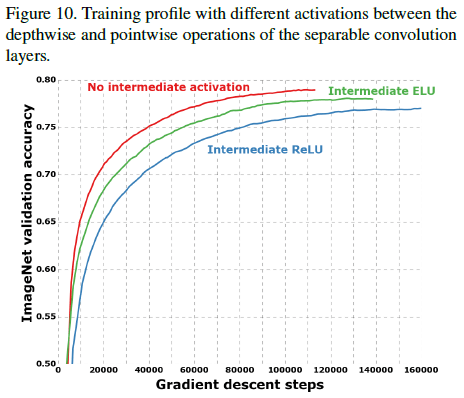
Figure 10
文章指出通过控制对 1×1 卷积输出的分段数量,可以得到一系列结构,标准卷积和深度可分离卷积是分别位于两个极端。通过将 Inception 模块替换为深度可分离卷积,文章给出了 Xception 网络架构。同时文章指出,在这一系列结构中,深度可分离卷积并不一定是最右的,更好的结构可能存在于中间的某个位置,有待进一步研究。
Recommend
-
71
-
45
README.md pytorch-deeplab-xception Update on 2018/11/24. Release newest version code, which fix some previous issues and also add support for n...
-
40
Abstract: Depthwise convolution is becoming increasingly popular in modern efficient ConvNets, but its kernel size is often overlooked. In this paper, we systematically study the impact of different kernel sizes...
-
7
By the end of this blog post, we aim to improve the results of my previous blog post of approximating circular bokeh with a sum of 4 separable...
-
17
Lecture Notes in Deep Learning: Activations, Convolutions, and Pooling — Part 1 Classical Activations
-
8
[Reading] Going Deeper with Convolutions Author: nex3z 2021-03-31 Going Deeper with...
-
5
聊一聊Inception系列(GoogLeNet、Inception、Xception) ...
-
8
这次介绍Depthwise Separable Convolution, 这种卷积层的设计是为了减少参数和计算量, 同时提高准确度或者保持准确度. 其中有几个轻量级模型, 包括MobileNets(v1, v2), Xception, 他们的设计初衷都是为了能够简化模型, 提高模型速度和准确度. 这几个模型都使用到了de...
-
4
A Separable Extension Is Solvable by Radicals Iff It Is SolvableIntroductionPolynomial is of great interest in various fields, such as analysis, geometry and algebra. Given a polynomial, we try to extract as man...
-
6
We have been investigating a recent bug report about fitnlm, the Statistics and Machine Learning Toolbox function for robust fitting of nonlinear models.ContentsQuahogs
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK