

Managing State in Angular Applications
source link: https://blog.nrwl.io/managing-state-in-angular-applications-22b75ef5625f
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Managing State in Angular Applications

Victor Savkin is a co-founder of Nrwl. We help companies develop like Google since 2016. We provide consulting, engineering and tools.
Managing state is a hard problem. We need to coordinate multiple backends, web workers, and UI components, all of which update the state concurrently. Patterns like Redux make some of this coordination explicit, but they don’t solve the problem completely. It is much broader.
What should we store in memory and what in the URL? What about the local UI state? How do we synchronize the persistent state, the URL, and the state on the server? All these questions have to be answered when designing the state management of our applications.
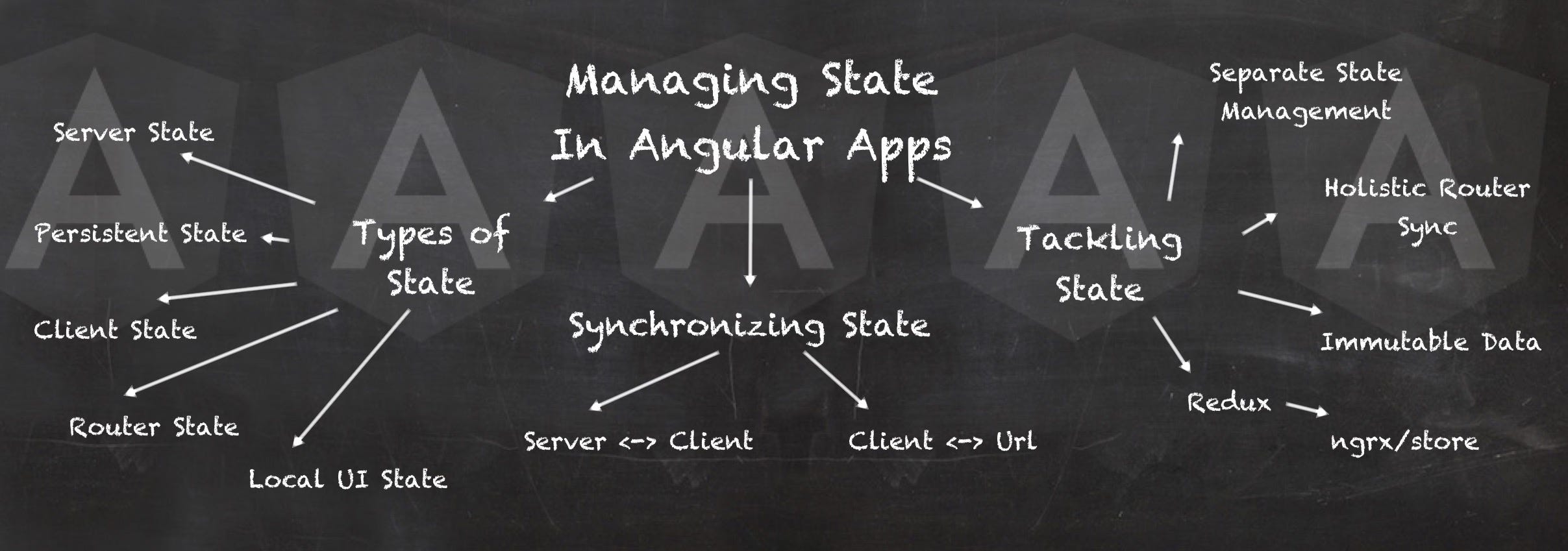
In this article I will cover six types of state, the typical mistakes we make managing them in Angular applications, and the patterns we should use instead.
Types of State
A typical web application has the following six types of state:
- Server state
- Persistent state
- The URL and router state
- Client state
- Transient client state
- Local UI state
Let’s examine them in detail.
The server state is stored, unsurprisingly, on the server and is provided via, for example, a REST endpoint. The persistent state is a subset of the server state stored on the client, in memory. Naively, we can treat the persistent state as a cache of the server state. In real applications though this doesn’t work as we often want to apply optimistic updates to provide a better user experience.
The client state is not stored on the server. A good example is the filters used to create a list of items displayed to the user. The items themselves are stored in some database on the server, but the values of the filters are not.
Recommendation: It’s a good practice to reflect both the persistent and client state in the URL.
Applications often have state that is stored on the client, but is not represented in the URL. For instance, YouTube remembers where I stopped the video. So next time I start watching it, it will resume the video from that moment. Since this information is not stored in the URL, if I pass a link to someone else, they will start watching from the beginning. This is transient client state.
Finally, individual components can have local state governing small aspects of their behavior. Should a zippy be expanded? What should be the color of a button? This is local UI state.
Recommendation: When identifying the type of state, ask yourself the following questions: Can it be shared? What is its lifetime.
State Synchronization
The persistent state and the server state store the same information. So do the client state and the URL. Because of this we have to synchronize them. And the choice of the synchronization strategy is one of the most important decisions we make when designing the state management of our applications.
Can we make some of this synchronization synchronous? What has to be asynchronous? Or using the distributed systems terminology: should we use strict or eventual consistency?
These, among others, are the questions we are going to explore in this article.
Example
Let’s start with an example of what seems to be a reasonably built system. This is an application that shows a list of talks that the user can filter, watch, and rate.
The application has two main routes: one that displays a list of talks, and the other one showing detailed information about each talk.
This is a rough sketch of this application’s architecture.
This is the application’s model.
And these are the two main components.
Both the components do not do any actual work themselves, and instead delegate to Backend and WatchService.
Any time the filters change, Backend will refetch the array of talks. So when the user navigates to an individual talk, Backend will have the needed information in memory.
The implementation of WatchService is very simple.
Source Code
You can find the source code of the application here.
Types of State
Let’s see what manages each type of state.
- Backend manages the persistent state (the talks) and the client state (the filters).
- The router manages the URL and the router state.
- WatchService manages the transient client state (watched talks).
- The individual components manage the local UI state.
Problems
At a first sight, the implementation looks reasonable: the application logic is handled in the services, the methods are small, and the code looks well-written. But if we look deeper, we will find a lot of problems.
Syncing Persistent and Server State
First, when loading a talk’s details, we call Backend.findTalk, which reads the data from the in-memory collection. This works when the user starts with the list view and then navigates around. If the user, however, initially loads the talk details URL, the collection will be empty, and the application will fail. We can workaround it by checking if the collection has the right talk, and if it does not, fetching the information about that talk from the server.
Second, the rate method optimistically updates the passed-in talk object to get a better user experience. The problem is that it doesn’t handle errors: if the server fails to update the talk, the client will show incorrect information. Let’s fix it by resetting the rating to null.
After these changes, the persistent state and the server state are synced properly.
Syncing URL and Client State
We can also see that changing the filters doesn’t update the URL. We can fix it by manually syncing the two.
Technically this works (the URL and the client state are in sync), but this solution is problematic.
- We call Backend.refetch twice. A filter change runs refetch. But it also causes a navigation that will eventually result in another refetch.
- We synchronize the router and Backend asynchronously. This means that the router cannot reliability get any information from Backend. Similarly, Backend cannot reliability get anything from the router or the URL — it just may not be there.
- We do not handle the case when a router guard blocks navigation. We would update the client state regardless, as if the navigation succeeded.
- Our solution is ad-hoc. We managed to synchronize the router and Backend for this particular route. If we added a new one, we would have to duplicate the logic.
- Finally, our model is mutable. This means that we can update it without updating the URL. This is a common source of errors.
Mistakes
This is a tiny application, and we found so many problems with it. Why was it so hard? What mistakes did we make?
- We did not separate the state management from the computation and services. Backend talks to the server, and also manages state. Same goes for WatchService.
- We did not clearly define the synchronization strategy of the persistent state and the server. Even after our changes, the solution seems ad-hoc and not holistic.
- We did not clearly define the synchronization strategy of the client state and the URL. Since there are no guards and refetch is idempotent, our fix worked, but it is not a sustainable solution.
- Our model is mutable, which makes ensuring any sort of guarantees difficult.
Refactoring 1: Separating State Management

The biggest problem, and the one we will tackle first, is separating the state management from the rest of the application. Managing state is excruciatingly hard, so lumping it together with “talking to the server”, “watching video”, or doing any complex computation will only make our lives unnecessarily difficult. Let’s fix it by introducing a Redux-like state management into our application.
Rule 1: Separate services/computation from state management
Introducing Redux
I won’t introduce Redux in this article as there is a lot of information about it online already. Check out the following posts for more information:
We shall start with defining all the actions our application can perform:
Then the state.
And, finally, the reducer.
This reducer function is the only place where we manipulate non-local state. Both Backend and WatchService became stateless.
Handling Optimistic Updates
Previously, we had an ad-hoc strategy for handling optimistic updates. We can do better than that.
Let’s introduce a separate action called UNRATE, to handle the case when the server rejects and update.
This is a significant change. It ensures that we process actions in order without interleaving them.
Rule 2: Optimistic updates require separate actions to deal with errors
Immutable Data
Finally, we changed our model to be immutable. This has a lot of positive consequences, some of which I will talk about later.
Rule 3: Use immutable data for persistent and client state
Updated Components
This refactoring simplified our components. Now they only query the state and dispatch actions.
Analysis
- State management and computation/services are separated. The reducer is the only place where we manipulate non-local state. Talking to the server and watching videos are handled by stateless services.
- We no longer use mutable objects for persistent and client state.
- We have a new strategy for syncing the persistent state with the server. We use ‘UNRATE’ to handle errors. This allows us to process actions in order.
To make it clear our goal was not to use Redux. It is easy to use Redux and still mix computation and state management, not handle errors and optimistic updates, or use mutable state. Redux enables us to fix all of these, but it is not a panacea and not the only way to do it.
Rule 4: Redux should the means of achieving a goal, not the goal
Also note that we didn’t touch any local UI state during this refactoring. Because the local UI state is almost never your problem. Components can have mutable properties that no one else can touch — that’s not what we should focus our attention on.
Using GraphQL and Apollo
Even after this refactoring, we still manually manage the client-server synchronization, and, as a result, we can make mistakes. We can forget to handle errors or invalidate the cache.
GraphQL and Apollo solve this problem in a more holistic way but require a larger infrastructure investment on the server. They can also work in combination with Redux, as shown here (https://github.com/Hongbo-Miao/apollo-chat).
If you can justify the investment, I’d highly recommend you to check out Apollo.
Source Code
You can find the source code of the application after this refactoring here.
Refactoring 2: Router and Store

Remaining Problems
Our design still has some problems.
- If the router needs some information from Backend, it cannot reliably get it.
- if Backend needs something from the router or the URL, it cannot reliably get it.
- If a router guard rejects navigation, the client state would be updated as if the navigation succeeded.
- The reducer cannot stop the navigation.
- The synchronization is ad-hoc. If we add a new route, we will have to reimplement the synchronization code there as well.
Router as the Source of Truth
One way to fix it is to build a generic library synchronizing the store with the router. It won’t solve all of the problems, but at least the synchronization won’t be ad-hoc. Another way is to make navigation part of updating the store. And finally we can make updating the store part of navigation. Which one should we pick?
Rule 5: Always treat Router as the source of truth
Since the user can always interact with the URL directly, we should treat the router as the source of truth and the initiator of actions. In other words, the router should invoke the reducer, not the other way around.
In this arrangement, the router parses the URL and creates a router state snapshot. It then invokes the reducer with the snapshot, and only after the reducer is done it proceeds with the navigation.
Implementing this pattern isn’t difficult. RouterConnectedToStoreModule does exactly that (see here).
RouterConnectedToStoreModule will set up the router in such a way that right after the URL gets parsed and the future router state gets created, the router will dispatch the ROUTER_NAVIGATION action
As you can see, the reducer can return an observable, in which case the router will wait until this observable completes. If the reducer throws an exception, the router will cancel the navigation.
With this we no longer need the Filter action. Instead, we trigger router navigations that will result in right actions.
Analysis
This refactoring tied the client state to the URL. The router navigation invokes the reducer, and then once the reducer is done, the navigation proceeds using the new state.
This is what we get as a result.
- The reducer can reliably use the new URL and the new router state in its calculations.
- Router guards and resolvers can use the new state created by the reducer, again reliably.
- The reducer can stop the navigation.
- Nothing updates concurrently. We always know where every piece of data is available.
- The solution is also holistic: it is done once. We don’t need to worry about syncing the two states when introducing new routes.
In other words, we solved all the problems listed above.
Source Code
You can find the source code of the application after this refactoring here.
Using @ngrx/store
I deliberately haven’t used any existing Redux libraries for building this application. I implemented my own store and connected it to the router (all together it is fewer than a hundred lines of code).
I did it to show that careful thinking is what is really important, and not using the latest version of any library.
Having said that, I think @ngrx/store is a great Redux implementation for Angular, and you should use it unless you have a reason not to. If you are using it, check out https://github.com/vsavkin/router-store, which implements the router-store connector for @ngrx/store. The library should become part of the ngrx soon.
Summary
We started with a simple application. Its implementation look reasonable: the functions were small, the code looked well-written. But when we examined it closer, we noticed a lot of problems. Many of which are not easy to notice if you don’t have a trained eye. We fixed some of them, but many still remained, and the solution was not holistic.
The application had these issues because we did not think through its state management strategy. Everything was ad-hoc. And when dealing with concurrent distributed systems, ad-hoc solutions quickly break down.
We embarked on refactoring the application. We switched to using a Redux-like store and immutable data. This wasn’t our goal. Rather this was the means of achieving some of our goals. To solve the rest of the problems, we implemented a strategy connecting the reducer and its store to the router.
And we discovered a few useful rules on the way.
The main takeaway is you should be deliberate about how you manage state. It is a hard problem, and hence it requires careful thinking. Do not trust anyone saying they have “one simple pattern/library” fixing it — that’s never the case.
Decide on the types of state, how to manage them, and how to make sure the state is consistent. Be intentional about your design.
Victor Savkin is a co-founder of Nrwl. We help companies develop like Google since 2016. We provide consulting, engineering and tools.
If you liked this, click the 👏 below so other people will see this here on Medium. Follow @victorsavkin to read more about monorepos, Nx, Angular, and React.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK