《面向应用开发者的系统指南》CPU篇之软中断
本文是《面向应用开发者的系统指南》文档其中的一篇,完整的目录见《面向应用开发者的系统指南》导论。
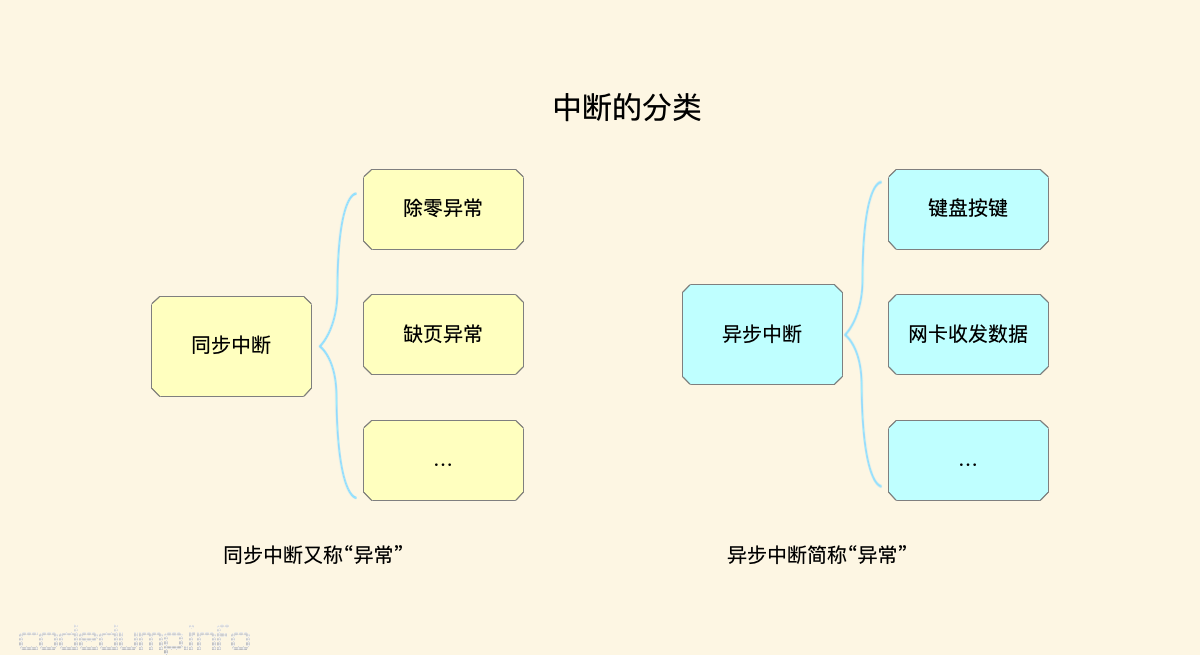
中断(interrupt)通常被定义为一个事件,该事件改变处理器执行的指令顺序。中断分为同步和异步两种:
- 同步中断在指令执行时由CPU控制单元产生,之所以称为同步,是因为只有在一条指令终止执行后CPU才发生中断。
- 异步中断是由其他硬件设备依照CPU时钟信号随机产生的。
在Intel的处理器手册中,将同步中断称为“异常(exception)”,异步中断称为“中断”。
异常通常由程序的错误产生,或者是由内核必须处理的异常条件产生的。比如程序中有除零异常,比如进程运行过程中产生的“缺页异常(pagefault)”等,都属于异常。
而中断是由定时器和I/O设备产生的,比如用户的一次按键、网卡收到数据,都会产生中断。
处理器一旦收到中断,就必须打断当前的执行,转而去执行中断处理函数。中断处理函数,本身有一些缺陷:
- 不能在进程上下文中执行,因此不能阻塞。
- 中断处理程序会打断程序执行,为了避免这个打断的流程停止时间过长,所以应该执行的越短越好。
因为以上的原因,Linux内核将中断的处理分为了上下两部分,其中上半部就是前面提到的中断处理函数,这部分能够最快的响应中断,并且做一些中断后必须要做的事情,而一些可以在中断处理函数后继续执行的操作,则可以放在下半部中。
以网卡接收到数据来举例,网卡通过中断告诉内核有数据可以接收,此时内核就会到网卡的中断处理程序中执行一些网卡硬件的必要设置,而对应的下半部就是处理网卡收到的数据,因为处理网卡数据没有必要在中断处理函数里面马上执行。
两者的主要区别在于:中断不能被相同类型的中断打断,而下半部依然可以被中断打断;中断对于时间非常敏感,而下半部基本上都是一些可以延迟的工作。由于二者的这种区别,所以对于一个工作是放在上半部还是放在下半部去执行,可以参考下面4条:
- 如果一个任务对时间非常敏感,将其放在中断处理程序中执行。
- 如果一个任务和硬件相关,将其放在中断处理程序中执行。
- 如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行。
- 其他所有任务,考虑放在下半部去执行。
有写内核任务需要延后执行,因此才有的下半部,进而实现了三种实现下半部的方法。这就是本文要讨论的软中断、tasklet和工作队列。
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet(请读者在遇到的时候根据上下文推断是否包含tasklet)。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断(即单个cpu上软中断不能嵌套执行),只能被硬件中断打断(上半部)。
可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构。
软中断由系统在启动的时候注册到内核中,由一个全局数组来维护软中断:
struct softirq_action
void (*action)(struct softirq_action *);
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
可以看到,本质上结构体softirq_action存储的是函数指针而已,软中断有以下类型:
HI_SOFTIRQ=0, // 处理高优先级的tasklet
TIMER_SOFTIRQ, // 定时器的下半部
NET_TX_SOFTIRQ, // 网卡发送数据包
NET_RX_SOFTIRQ, // 网卡接收数据包
BLOCK_SOFTIRQ, // BLOCK装置
IRQ_POLL_SOFTIRQ,
TASKLET_SOFTIRQ, // 处理常规的tasklet
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ,
NR_SOFTIRQS
系统提供了open_softirq函数用于各个需要使用到软中断的系统注册对应的软中断处理函数。
void open_softirq(int nr, void (*action)(struct softirq_action *))
softirq_vec[nr].action = action;
同时,还提供了softirq_to_name数组,用于把软中断的索引映射到对应的软中断名称:
const char * const softirq_to_name[NR_SOFTIRQS] = {
"HI", "TIMER", "NET_TX", "NET_RX", "BLOCK", "IRQ_POLL",
"TASKLET", "SCHED", "HRTIMER", "RCU"
在Linux下面,可以通过查看/proc/softirqs文件知道当前系统软中断的情况:
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 276180 286764 2509097 254357
TIMER: 1550133 1285854 1440533 1812909
NET_TX: 102895 16 15 57
NET_RX: 155 178 115 1619192
BLOCK: 1713 15048 251826 1082
IRQ_POLL: 0 0 0 0
TASKLET: 9 63 6 2830
SCHED: 1484942 1207449 1310735 1724911
HRTIMER: 0 0 0 0
RCU: 690954 685825 787447 878963
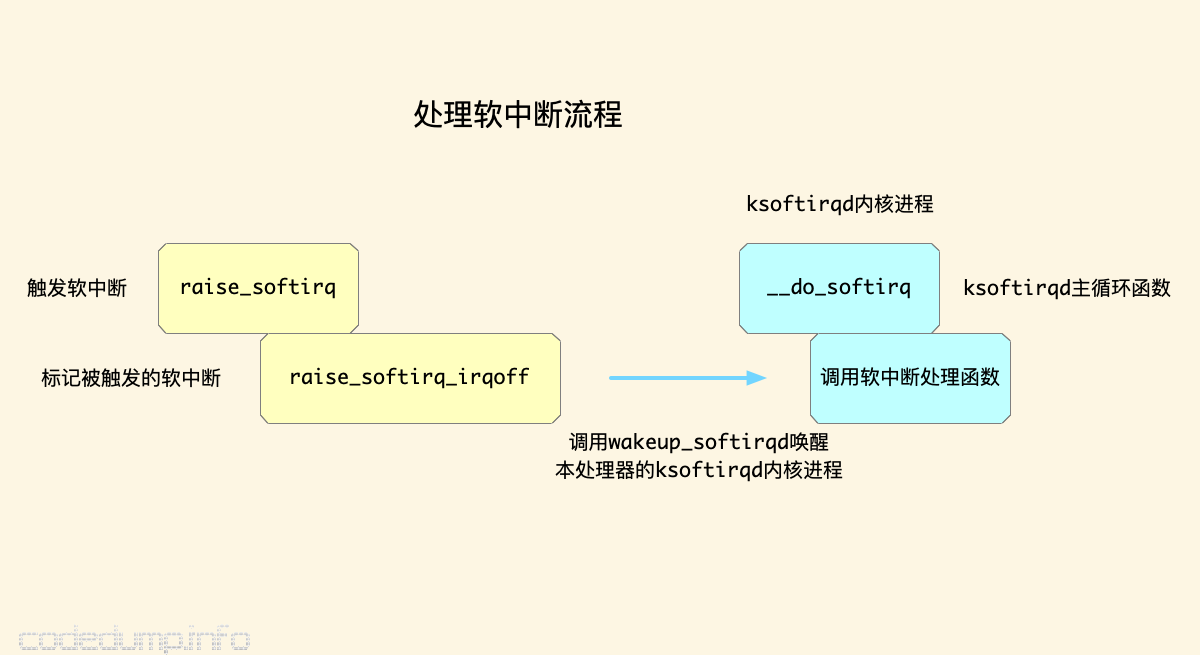
触发软中断
触发软中断的入口函数是raise_softirq:
void raise_softirq(unsigned int nr)
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
首先,由于调用软中断处理函数必须禁用中断,所以local_irq_save宏将保存在eflags寄存器中的IF标志,同时禁用本地处理器的中断。对应的,local_irq_restore宏将保存下来的flags标志位恢复回去,同时打开本地处理器的中断。
接着看raise_softirq_irqoff函数:
inline void raise_softirq_irqoff(unsigned int nr)
__raise_softirq_irqoff(nr);
if (!in_interrupt())
wakeup_softirqd();
首先,调用__raise_softirq_irqoff将本地处理器的中__softirq_pending变量对应nr这个软中断的位置为1,表示该类型的软中断被触发了。
然后,通过in_interrupt函数来判断处理器当前是否在处理中断状态,如果没有则调用wakeup_softirqd函数唤醒本处理器的ksoftirqd内核进程:
static void wakeup_softirqd(void)
struct task_struct *tsk = __this_cpu_read(ksoftirqd);
if (tsk && tsk->state != TASK_RUNNING)
wake_up_process(tsk);
在Linux系统中,每个CPU都会运行一个ksoftirqd内核进程,专门由这个进程来处理本CPU的软中断。ksoftirqd内核进程的主要流程在函数__do_softirq中完成,其核心是一个循环,用来检测当前有哪些未处理的软中断,调用其注册的处理函数来处理软中断:
asmlinkage __visible void __softirq_entry __do_softirq(void)
// ...
while ((softirq_bit = ffs(pending))) {
trace_softirq_entry(vec_nr); // 记录开始处理软中断的trace event
h->action(h); // 调用注册的软中断处理函数
trace_softirq_exit(vec_nr); // 记录结束处理软中断的trace event
总结来说,要触发一个软中断只需要以下几步:
- 保存IF标志,禁用中断。
- 将这个软中断对应的位置为1。
- 通知本CPU的ksoftirqd内核进程,有软中断需要处理。
- 恢复IF标志,开启中断。
可以看到,有了软中断机制,内核在禁用中断的状态中实际上并没有耗费太多时间,仅仅修改了一个标记然后唤醒ksoftirqd内核进程就可以返回了。
tasklet
软中断有以下问题:
- 只能在系统启动时注册,另外数量和类型不能动态变更。
- 因为每个处理器上都有一个
ksoftirqd内核进程,可能同时在处理同一种类型的软中断,软中断必须实现为可重入函数,导致开发上的复杂度提高。如果某种应用并不需要在多个CPU上并行执行,那么软中断是没有必要的。
因此基于软中断之上又实现tasklet,这是最常见的实现延迟中断处理的机制。它具有以下特性:
- 一种类型的tasklet只能运行在一个CPU上,不能并行而只能串行执行。
- 多个不同类型的tasklet可以并行在多个CPU上。
- 软中断是静态,只能支持有限的几种软中断类型,一旦内核编译好之后就不能改变;而tasklet灵活很多,可以通过添加内核模块的方式在运行时修改。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
首先来看初始化,对应的是softirq_init函数:
void __init softirq_init(void)
int cpu;
for_each_possible_cpu(cpu) {
per_cpu(tasklet_vec, cpu).tail =
&per_cpu(tasklet_vec, cpu).head;
per_cpu(tasklet_hi_vec, cpu).tail =
&per_cpu(tasklet_hi_vec, cpu).head;
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
可以看到,tasklet各有一个基于TASKLET_SOFTIRQ和HI_SOFTIRQ两个类型软中断的tasklet,这两个类型分别对应低优先级和高优先级的tasklet,变量tasklet_vec和tasklet_hi_vec的定义如下:
struct tasklet_head {
struct tasklet_struct *head;
struct tasklet_struct **tail;
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
这两个变量分别定义了两个存储tasklet_struct结构体的链表。结构体tasklet_struct定义如下:
struct tasklet_struct
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
其中包含了五个成员变量,分别是:
- struct tasklet_struct *next:链表中下一个成员的指针。
- unsigned long state:tasklet的状态。
- atomic_t count:原子变量,表示这个tasklet当前是否活跃。
- void (*func)(unsigned long):处理这个tasklet的回调函数。
- unsigned long data:回调函数参数。
触发tasklet
内核通过函数tasklet_schedule触发一个tasklet被执行:
static inline void tasklet_schedule(struct tasklet_struct *t)
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
首先,使用test_and_set_bit函数判断t->state中的TASKLET_STATE_SCHED是否被置为1,如果没有则调用函数__tasklet_schedule调度tasklet来执行:
// kernel/softirq.c
void __tasklet_schedule(struct tasklet_struct *t)
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
该函数首先和前面软中断的处理一样,保存IF标志位同时禁用中断,然后修改tasklet_vec链表将新增的tasklet添加到链表尾部,调用raise_softirq_irqoff触发TASKLET_SOFTIRQ类型的软中断执行,最后恢复IF标志位同时启用中断。
在函数softirq_init中,两类用于处理tasklet的处理函数分别是:
open_softirq(TASKLET_SOFTIRQ, tasklet_action);
open_softirq(HI_SOFTIRQ, tasklet_hi_action);
接着看函数tasklet_action的实现,其核心就是从前面的链表中依次取出tasklet_struct结构体数据调用其处理函数:
// kernel/softirq.c
static __latent_entropy void tasklet_action(struct softirq_action *a)
struct tasklet_struct *list;
while (list) {
struct tasklet_struct *t = list;
t->func(t->data);
该函数的工作流程是:
- 调用local_irq_disable禁用本地CPU的中断。
- 从tasklet_vec链表头取出头元素list。
- 调用local_irq_enable启用本地CPU的中断。
- 接着,就是遍历整个tasklet_vec链表,依次处理这些tasklet了。每次取出一个tasklet的时候,也是像前面一样应用本地CPU的中断,取出之后再开启中断。
workqueue
workqueue是另外一种延迟处理中断的机制。与tasklet相比,两者有以下的区别:
- workqueue函数运行在内核进程上下文中(context of kernel process),而tasklet运行在中断上下文中。
- tasklet都在它最初被触发的CPU中执行,而workqueue则没有这个限制。
- 如果处理函数执行过程中需要睡眠和阻塞,那就必须使用工作队列了。软中断运行在中断上下文中,因此不能阻塞和睡眠,而tasklet使用软中断实现,所以也不能阻塞和睡眠。
内核使用结构体worker_pool来管理所有CPU上面的worker,在这里仅列举其中的一部分成员:
// kernel/workqueue.c
struct worker_pool {
spinlock_t lock; /* the pool lock */
int cpu; /* I: the associated cpu */
int node; /* I: the associated node ID */
int id; /* I: pool ID */
unsigned int flags; /* X: flags */
unsigned long watchdog_ts; /* L: watchdog timestamp */
struct list_head worklist; /* L: list of pending works */
int nr_workers; /* L: total number of workers */
worker_pool中管理的每个worker如下定义:
// kernel/workqueue_internal.h
struct worker {
/* on idle list while idle, on busy hash table while busy */
union {
struct list_head entry; /* L: while idle */
struct hlist_node hentry; /* L: while busy */
struct work_struct *current_work; /* L: work being processed */
work_func_t current_func; /* L: current_work's fn */
struct pool_workqueue *current_pwq; /* L: current_work's pwq */
bool desc_valid; /* ->desc is valid */
struct list_head scheduled; /* L: scheduled works */
每个CPU上运行的kworker进程:
$ ps aux | grep kworker
root 4 0.0 0.0 0 0 ? I< 1月30 0:00 [kworker/0:0H]
root 18 0.0 0.0 0 0 ? I< 1月30 0:00 [kworker/1:0H]
root 24 0.0 0.0 0 0 ? I< 1月30 0:00 [kworker/2:0H]
添加任务到workqueue
内核提供函数queue_work将任务放入workqueue中:
// include/linux/workqueue.h
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
接着看函数queue_work_on:
// kernel/workqueue.c
bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
bool ret = false;
unsigned long flags;
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_work(cpu, wq, work);
ret = true;
local_irq_restore(flags);
return ret;
它做的事情很简单,同样也是前后禁用、启用中断,在判断WORK_STRUCT_PENDING_BIT被置为1失败之后,调用__queue_work将任务放入workqueue:
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
// ....
if (req_cpu == WORK_CPU_UNBOUND)
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
if (!(wq->flags & WQ_UNBOUND))
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
// ...
insert_work(pwq, work, worklist, work_flags);
// ...
这里裁剪掉无关的代码,来看核心的部分:
- 首先,如果work加入时未指定要运行的CPU,通过wq_select_unbound_cpu进行选择,默认使用当前CPU。如果该CPU不在wq_unbound_cpumask (全局 cpumask)内,则从wq_unbound_cpumask中通过round robin方式选择。
- 对于 bound workqueue ,取出当前 per CPU变量中的pool_workqueue 。对于unbound workqueue,取出当前CPU 所在node对应的pool_workqueue。
在kwork内核进程内部,最终会在函数process_one_work中处理work:
// kernel/workqueue.c
static void process_one_work(struct worker *worker, struct work_struct *work)
// ...
trace_workqueue_execute_start(work); // 记录开始处理work的trace event
worker->current_func(work); // 调用work的处理函数
trace_workqueue_execute_end(work); // 记录结束处理work的trace event
使用systemtap追踪软中断
systemtap上提供了可以跟踪软中断以及工作队列的probe事件,可以在systemtap的tapset\linux\irq.stp中看到相关的定义,比较简单这里就不做解释,这里仅列举网上看到的一个使用这些tapset来追踪软中断事件的例子:
global hard, soft, wq
// 记录硬中断
probe irq_handler.entry {
hard[irq, dev_name]++;
// 每隔一秒打印中断、软中断、工作队列的统计信息
probe timer.s(1) {
println("==irq number:dev_name")
foreach( [irq, dev_name] in hard- limit 5) {
printf("%d,%s->%d\n", irq, kernel_string(dev_name), hard[irq, dev_name]);
println("==softirq cpu:h:vec:action")
foreach( in soft- limit 5) {
printf("%d:%x:%x:%s->%d\n", c, h, vec, symdata(action), soft);
println("==workqueue wq_thread:work_func")
foreach( [wq_thread,work_func] in wq- limit 5) {
printf("%x:%x->%d\n", wq_thread, work_func, wq[wq_thread, work_func]);
println("\n")
delete hard
delete soft
delete wq
// 统计软中断
probe softirq.entry {
soft[cpu(), h,vec,action]++;
// 统计工作队列执行信息
probe workqueue.execute {
wq[wq_thread, work_func]++
probe begin {
println("~")