

Is epidemiology useful?
source link: https://blog.plan99.net/is-epidemiology-useful-a4ec54e59569
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Is epidemiology useful?
A closer look at the field informing current events
There’s a famous saying about simulations of the real world: “all models are wrong, but some are useful”. A critical question to ask right now is whether epidemiological models are wrong but useful, or just wrong.
Are epidemiological models useful?
It’s up to governments to decide what advice to follow. Nothing in this analysis should be taken as a suggestion to ignore their recommendations or laws. Don’t start ignoring the local rules because you read this blog post.
Imperial College London’s modelling of SARS-CoV-2 spread is what triggered the UK’s switch to full lockdown mode, and reinforced or also triggered it in many other countries. Given the dire consequences of shutting down the planet it deserves a level of scrutiny no scientific work has ever been subjected to before. That’s now slowly starting to happen.
In this article I’ll look primarily at the history of epidemiology and methodological problems found within. If you’re interested in problems that are really COVID-19 specific, I recommend “Coronavirus disease 2019: the harms of exaggerated information and non-evidence-based measures” by Dr John Ioannidis, accepted by the European Journal of Clinical Investigation.
Citations will be provided for all claims.
Summary
- Imperial College London (ICL) is described as being the best in the world at epidemiological modelling.
- Despite this they have a history of major misses that don’t seem to be admitted. Their recommendations have led to disastrous over-reaction by governments in the past.
- Although presented as scientists they engage in unscientific practices e.g. making unfalsifiable statements, lack of peer review, refusing to show their code, using vague terms instead of statistical confidence bounds.
- They have predicted disease outbreaks to be orders of magnitude more serious than they really were.
- It’s unclear what the field of epidemiology learned from these mistakes, if anything.
- They are using data for their models that is known to not be statistically meaningful.
- Sniping has broken out amongst epidemiologists at different universities, many of whom are contradicting each other in public, and in very major ways.
Whilst most of this article will focus on the track record of Imperial the problem is really a wider one than that — Imperial’s report is being listened to because of the ‘brand’ of academia and academic science more generally. Oxford have produced their own paper which is no better and if anything even worse. “We’re guided by the science” is the motto of governments everywhere because they assume the science is correct, or at least, better than nothing. If that assumption is false it’s a huge problem.
Who are the ICL modelling team?
“the Imperial people are the some of the best infectious disease modellers on the planet”
— Paul Hunter at the University of East Anglia, UK (New Scientist)“led by a prominent epidemiologist, Neil Ferguson, Imperial is treated as a sort of gold standard … American officials said the report, which projected up to 2.2 million deaths in the United States from such a spread, also influenced the White House …. “A lot of it is not what they say, but who says it,” said Devi Sridhar, director of the global health governance program at Edinburgh University. “Neil Ferguson has a huge amount of influence.””
— New York Times“The Imperial College study has been done by a highly competent team of modellers”
— John Ioannidis (Departments of Medicine, of Epidemiology and Population Health, of Biomedical Data Science, and of Statistics, Stanford)
So they’re a pretty big deal. If they’re the best epidemiologists in the world it seems we might judge the field of epidemiology by their performance.
It’s worth noting at this point that epidemiology isn’t the same thing as medicine. Prof Ferguson did his PhD in theoretical physics. Modellers can be computer programmers who specialise in applied mathematics, not doctors in the hospital sense. This isn’t meant as a knock: applied mathematics is a highly valuable field of course but as we’ll see later, a key criticism of epidemiology is the way it in which it elevates abstract mathematical calculations above the experience of people with on-the-ground medical experience.
Unscientific practices
The scientific method needs several things to work right.
Peer review. “Impact of non-pharmaceutical interventions (NPIs) to reduce COVID19 mortality and healthcare demand” is dated 16th March 2020 and was released to the press immediately, simultaneous with the sudden change of government strategy it caused. Although many papers on COVID-19 have been put through peer review, in this case it seems it was skipped.
It’s possible peer review would have rejected the paper; certainly a lot of their peers have problems with it.
Reproducibility. The analysis can’t be replicated for multiple reasons. Amongst other problems the actual model itself isn’t available anywhere because the code is of such low quality only Prof Ferguson’s team understands it:
He doesn’t plan to ever release the original code, only a version rewritten by Microsoft:
In maths class children who don’t show their working get a fail grade, doubly so if they submit work done by others. In epidemiology it’s no big deal.
This is an exceptionally critical problem. I cannot emphasise this enough. Academia is in the middle of the replication crisis (that’s the real name). Entire fields are having their credibility shredded because nobody can replicate ‘discoveries’ that were widely accepted for decades.
In the time since Imperial released their study other non-epidemiologists managed to build models that are not only publicly documented and with available source, but which are fully interactive and can be run by anyone in a browser. “My code is too complex to understand without personal training” is not an acceptable thing for publicly funded researchers to say, especially not when that code is now over a decade old. Imperial had all the time in the world to make their results reproducible and of acceptable quality, yet never did.
The analysis can’t be replicated for other reasons: it relies on private correspondence for key data (“personal communication” is listed as a source twice), makes vague reference to “the NHS providing increasing certainty around the limits of hospital surge capacity” but doesn’t say where this certainty was published — especially curious given that the analysis shows capacity as constant for a year but the NHS is building 3 new emergency hospitals, the first of which is one of the largest hospitals in the world. Where did this completely flat line at 8 ICU beds per 100,000 come from?
Non-reproducible work is being slowly stamped out in other fields like psychology: it needs to be unacceptable here too. Especially now!
Falsifiable predictions. Scientists make testable predictions.
Prof Ferguson has a habit of making “heads I win, tails I win” type predictions. To be fair, in his paper various estimates were provided for death tolls given various combinations of reproduction values (R0), levels of lockdown and trigger values. Those are fairly precise and in hindsight we could measure how far away reality is from them. For instance with an R0 of 2.2 and with lockdown triggered at a rate of 300 ICU cases per week, they predict 26,000 deaths. Some people have claimed he later revised his prediction downward from over 500,000 deaths: that claim isn’t true.
But there is a slightly more subtle problem. Later he did change what he was predicting to be “20,000 deaths and could be much lower”. If deaths are much higher, he can argue his recommendations weren’t followed closely enough (and as those recommendations are virtually impossible to implement fully, who can argue). If deaths are around 20,000, he can say “our analysis correctly predicted the outcome”. If deaths are much lower, he can say “deaths were within our predictions”.
This sort of problem has cropped up before. When asked to model the outbreak of bovine spongiform encephalopathy (a.k.a. mad cow disease) he predicted human death toll of between 50 and 150,000.
When queried about the vagueness of this prediction the response was “Yes, the range is wide, but it didn’t actually lead to any change in government policy” (Daily Telegraph). That answer is a non-sequitur, but shows a deep concern with whether epidemiological advice steers outcomes.
A second critical change was the claim that “probably 2/3rds of those people would have died anyway”. The notion of excess mortality appears nowhere in the original report; most likely Imperial found out the Italian data they used reported deaths with infection and not deaths because of infection at the same time as everyone else. It would presumably change the conclusions fundamentally, indeed, it muddies the very concept of “number of deaths”.
In case you think I’m picking on Imperial, the recent Oxford epidemiology paper on COVID-19 says “… the proportion of the UK population that has already been infected could be anywhere between 0.71% and 56% (95% credible intervals…)”.
These sorts of ranges on predictions really mean epidemiology has nothing useful to contribute. However, they aren’t saying that in plain English.
Appearance of neutrality. Trust in science falls when people believe scientists are pushing political agendas. This largely explains why, as the FT reports, “Economists among least trusted professionals in UK”. It’s also a common concern floated by climatology skeptics.
An easy way to avoid this problem is for scientists to simply publish what they’ve found and leave discussion of policy changes to politicians who are — unlike academics — directly accountable to those who policy affects.
Epidemiologists don’t seem to do this. So far in every case I’ve examined epidemiologists recommend extremely specific social/agricultural policies, and some papers spend about half their word count directly addressing policymakers.
Foot and mouth disease
Let’s take a look at how some of these problems can lead to disaster.
Epidemiological modelling is a relatively young field. Its first test-drive in the UK came with an epidemic in 2001 of foot-and-mouth disease (FMD) amongst pigs and sheep. The result was so catastrophic it has been the subject of many papers. Whilst this event is now 20 years old, I’ll also look at a second prediction from about 5 years ago to demonstrate that not much has changed.
“The model driven policy of FMD control resulted in tragedy. Vast numbers of animals were slaughtered without reason. Untold human and animal suffering was the result — not to mention the financial consequences”
— Dr Paul Kitching, author of “Use and abuse of mathematical models”
Here are a few of the papers I read on the topic this weekend, but there are many more. It’s obvious the events were highly traumatic and highly studied as a result. As you can guess from the titles, the authors were very critical of what happened:

The government’s “FMD Science Group” consisted of a range of disciplines but epidemiologists were by all accounts dominant. Modellers came from four different universities, but fairly quickly the Imperial model became the primary model used (from the paper “Media, metaphors, modelling”).
Their programs predicted a severe epidemic. They argued it could only be averted by an instant and extreme policy: the so-called ‘contiguous cull’. Any susceptible animal living within 3km of any farm that had an infected animal was to be killed immediately, even if it was healthy.
“This new policy, which proved to be controversial, was justified by mathematical modellers …
This replaced the existing policy, which required a veterinary risk assessment.
Over 1,200,000 animals on 3,369 premises were slaughtered as part of the contiguous cull” — Mansley et al
Virtually all the killed animals were uninfected:
“serosurveillance of 115 flocks sampled during the cull found only one flock of sheep with any seropositive animals (nine positives from 56 sheep)
Was it justified? Mansley et al say:
“Post-epidemic analysis has provided further support for … the lack of impact of the contiguous culling policy”
“the novel 48-h contiguous cull policy — driven by mathematical models — was implemented when the epidemic was already in decline.
There was an accidental control group. Cumbrian authorities didn’t have the resources to implement the contiguous cull everywhere:
Furthermore, the contiguous cull was not implemented in north Cumbria, yet the epidemic curve for Cumbria mirrors the curve for the rest of Great Britain in 2001 (Figs 2 & 3) and also the 1967/1968 epidemic curve.”
Ultimately, the models neither correctly predicted the course and duration of the epidemic nor the effectiveness of the traditional control measures put in place nor the novel ones proposed (61). Thus, they failed the acid tests of refutedness, testedness and usefulness (41).
They failed the acid test of usefulness.
Why did they go wrong?
The models’ veterinary assumptions … represented a different (wholly theoretical) virus, perhaps best dubbed the ‘Armageddon virus’, given its ability to infect whole herds at once and be excreted several days in advance of clinical manifestation, maximally and indefinitely, unless the animals were killed.
Along with bad assumptions the model was fundamentally concerned with geographical spread between farms, but the data used about farms was of very low quality, having been originally collected for management of CAP subsidies:
“Yes, but you know, the people who curate the database of farms really don’t care where they are. You know, why they’ve got that information in they probably don’t know. They’ve got an address of the person they write to, that’s the only real spatial location they need and the fact that the geographical co-ordinates place the farm in the middle of the North Sea you know, so what”
— Interview E7, Christley et al
As Kitching et al. put it:
‘The UK experience provides a salutary warning of how models can be abused in the interest of scientific opportunism’”
Although Mansley et al is the most comprehensive, there are lots of papers making similar points.
Lessons learned, or not
In the wake of this event ICL produced the following chart:

The chief scientific advisor at the time gave this testimony:
“And what I would like you to do is to look at the very impressive figures; if you compare Figure [1], which is the predictions that were made, the curves A, B, C, with [the epidemic data — blue dots], which is how the epidemic developed, I think you have got to agree that that was not bad agreement, the prediction was not too bad.”
— Prof David King at a Parliamentary Enquiry
As far as the epidemiologists were concerned, it was a great success. What conclusion did the government ultimately reach? We know because some years later another outbreak occurred:
“Many lessons were learned from the experiences of the UK 2001 FMD epidemic that were tested all too soon when FMD again struck the UK, in 2007.” — Mansley et al
The lesson learned was to ignore epidemiology:
“Not least among these was the policy of employing the traditional, well established methods of FMD control and eradication and not using novel procedures, based on non-validated mathematical models.”
What happened?
“This strategy proved to be correct and the virus was relatively quickly eradicated”
— Mansley et al
The failure of epidemiology in this event was absolute: the only consumers of their product are politicians and civil servants. Those people chose not to use models in the next outbreak.
A key question is what the field learned from this. And that’s where it gets very troubling indeed. From The Telegraph:
Professor Ferguson said of his modelling for FMD: “A number of factors going into deciding policy, of which science — particularly modelling — is only one. It is ludicrous to say now that our model changed government policy. A number of factors did.”
The highlighted statement is problematic because it’s both very strong and just doesn’t match anything else written about the outbreak. It’s clear from every document on the FMD epidemic that epidemiological modelling was the primary driver of government policy. How can the professor claim it’s ludicrous to believe ICL’s work determined government policy when so many authors writing papers about that time believed otherwise?
From “Media, metaphors and modelling”:
As the modelling undertaken at Imperial College became the prime source for political decision-making, the press focused mainly on the models produced there, not the models produced by the Edinburgh and Cambridge teams.
From “Destructive tension: mathematics vs experience”:
The models that supported the contiguous culling policy were severely flawed.
As of today the ICL team still believe they were basically correct about the FMD epidemic:
“We were doing modelling in real time as the other groups were in 2001 — certainly the models weren’t 100% right, certainly with limited data and limited time to do the work. But I think the broad conclusions reached were still valid.”
Zika: another miss
You might remember the 2015 Zika outbreak in Latin America, a terrifying virus that caused babies of infected women to be born with shrunken heads and serious brain damage. Imperial modelled the epidemic and said in a July 2016 paper:
“We expect the current epidemic to be largely over in 3 years, with seasonal oscillations in incidence caused by variation in mosquito populations and transmissibility”
And here’s what happened. It didn’t take 3 years with seasonal returns. It was gone within one.
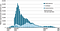
Zika is eradicated from the USA. Globally there have been so few cases since 2017 that Wikipedia’s page about the virus doesn’t even bother with any news about it after that (the last update is about two cases in Angola).
Whilst the disease still circulates in Latin America, the worst affected region making up 60% of all reports (Brazil) sees an average of about 365 cases per week, of which only about 30 are laboratory confirmed — too low to see on the graph above. If the predicted seasonal oscillations exist at all they are lost in the noise.
The analysis was also unable to explain the behaviour up to that point:
“Currently, we cannot assess whether Asia is at risk of a major Zika epidemic — or why the scale of transmission in Latin America has been so much greater than anything previously seen”
About half the paper was devoted to the section, “What should policy-makers do” but no concrete recommendations were made beyond recommending women avoid getting pregnant. The paper does admit:
“Advising against pregnancy has been criticized for being infeasible for many women — especially long term”
No kidding.
Conclusions
Similar problems seem to crop up repeatedly in epidemiological analysis:
- Models are based on input data of extremely low quality. This is acknowledged briefly but doesn’t stop anyone making predictions even though it should.
- Statistical uncertainty often isn’t formally analysed. Vague adjectives like “largely”, “broadly”, “probably”, “substantially”, “typically” are used instead.
- Modellers are highly involved in policy-making and clearly perceive that as one of their primary purposes. Advice to political leaders can make up half or more of supposedly scientific papers.
- Predictions routinely have bounds so enormous they are rendered useless.
- Modellers don’t seem to have made any obvious methodological changes in response to prior prediction failures
Should epidemiologists be treated with the nearly god-like respect they currently command? I’ve got nothing against any of the people or institutions discussed in this article, and in principle I don’t see why epidemics shouldn’t be simulatable. But it could be prudent to hold off talking to journalists and politicians until the field has had a string of undeniable successes, and the outcomes have become seen as routine. Clearly we’re not there yet.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK