

在 Kubernetes 中优雅下线微服务应用
source link: https://fredal.xin/graceful-k8s-shutdown
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在去年写过一篇关于微服务优雅上下线的文章,比较笼统的将了一下微服务保证优雅上下线的一些方式。但随着应用的逐渐 k8s 化,原有的微服务下线会存在一些问题。
下线信号钩子
之前针对优雅下线使用的还是通过信号响应的方式。一个是 docker 以及 k8s 中下线信号 SIGTERM,由于这个信号会被 JVM 处理,所以我们写了一份下线逻辑在其 shutdownHook 里。另一个是我们自定义的信号 SIGUSR2,这个本身就是保留给用户自定义的,通过 SignalHandler,也写了一份下线逻辑注册到了应用内。
这里就出现了一些问题,一方面是代码上的问题:
- 不同系统对信号的支持不同,代码上没有考虑对跑在 windows 上机器的兼容
- 在钩子函数里的下线逻辑中存在抛出 Exception 的可能性,导致一些意想不到的问题
还有一部分是钩子函数本身的局限性: - 信号可能被其他二方包或者业务代码占用了
- 应用可能卡死了,处理不了钩子函数或者需要很久时间
- 不适合做一些更精细的操作,例如循环验证确认等。这部分逻辑天生就应该放在外部而不是应用内部。
这里我们打算使用下线函数以替换下线信号钩子,从而避免其存在的一些缺点。
那么使用下线函数的最主要的问题是,这个函数应该写在哪,是应该放在应用上?还是一个第三方的 adminController 上?还是应用的各自的 sidecar proxy 上?考虑到目前的实际现状,我们目前暂时把下线接口定在应用内 sdk 上:
- 应用下线接口在很早的 sdk 版本就提供了,普及度很高。这是不重新优化原来 shutdownHook 逻辑最主要的原因。
- 目前 k8s 化大概不到一半,还有大部分是 kvm 机器,不是 k8s 在没有 pod 的加持下搞 sidecar container,运维上就会有较高的成本。
- 不做在第三方 adminController 的原因,一个是下线接口已经存在了,另一个是在应用内会更容易进行 bean 的销毁,而不仅仅是从注册中心反注册。
函数提供方确定了,函数调用方其实不用过多思考。在目前 kvm 机器部署方式下,调用方由 cicd 系统担任。而在我们重点关注的 k8s 方式下,k8s 本身提供了 preStop 的扩展点,目前提供了'HTTPGET'与'EXEC'两种模式来进行 pod 退出逻辑的扩展。使用方式如下:
spec:
contaienrs:
- name: soa-test
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","/preStop.sh"]
这样我们将下线逻辑都写在 preStop.sh 中即可,preStop.sh 中直接调用应用的下线接口即可。
除此之外我们还做了一个二次确认的操作,考虑到调用应用下线接口也不能保证实例就从注册中心反注册了(例如与信号钩子同样的问题,接口也卡死了),我们通过调用第三方 adminController 的接口,去注册中心验证一下实例是否真正下线,如果实例还在,那么表示应用的下线接口可能出现了些幺蛾子,直接通过 adminController 去从注册中心摘除实例。
k8s 的动态 pod ip
在目前 k8s 与微服务框架结合的情况来看,我们微服务应用的服务注册还是基于 ip 的,也就是说在注册中心上我们看到的是服务的 pod ip。关于服务间通信的问题,我们使用了 nodeport 打通了同 k8s 集群下 pod 间的网络,使用 node 配置路由的方式打通了外部节点与 pod 间的网络。
那么这种基于 pod ip 的方式对于微服务上下线又有什么影响。我们知道 pod ip 都是动态的,每次重启后 ip 都会变化。这对于基础的服务注册与发现并没有什么影响,通过注册中心的通知机制可以做到动态变更。但是对于微服务的服务配置来说,就会出现问题了。我们这里讲的服务配置指对单个实例的配置,例如实例的权重等等。目前我们对于实例配置的生命周期是完全独立于实例自身的。也就是说,你在微服务 ops 平台上对实例所做的配置重启之后仍然保留。那么我们对于实例的区分是基于 ip 的,而 pod 实例的 ip 确是动态的。于是,可以预想的是,随着应用 pod 的不断重启,导致残留的无用实例配置越来越多,注册中心做消息通知时推送的消息变得很大,应用内对于这些消息的存储对象也变得很大,最坏甚至可能导致应用 crush 或者大范围的网络问题。
解决这个问题最简单的方式是在微服务下线的时候,判断一下如果是 k8s 网段的 ip,则清除对 pod 所做的实例配置,这段逻辑同样通过调用接口完成。至于重启后恢复之前的实例配置,在目前我们无状态的应用部署模式,以及基于 pod ip 的微服务&k8s 情况下暂时无法做到。
那么问题又来了,清除实例配置的这个接口应该放在哪呢?仍然考虑到不对业务应用做入侵(升级微服务 sdk),我们把清除实例的配置还是放在了 adminController,与实例下线的二次确认一块儿。
目前的下线方案
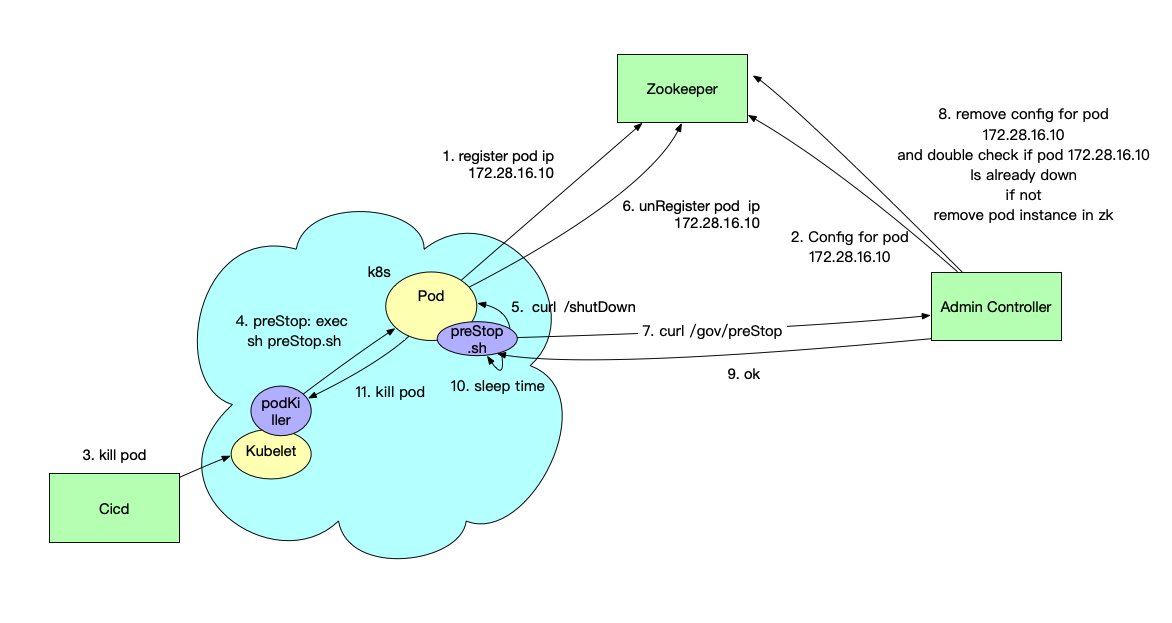
目前在 k8s 中微服务的整体下线逻辑如上图所示,一眼看去就有很多不合理的地方, shutDown 和 preStop 接口放在两个地方,需要调用两次实在有点蠢,并且放接口在集中式的 adminController 上可能会引起性能问题等。虽然我为这个找了许多借口,例如实例上的下线接口方便应用内 bean 销毁,preStop 接口放在 adminController 上符合了二次确认的语义,并能避免应用内本身接口的卡死。但其实更多是因为考虑到不需要业务应用做改动(升级微服务 sdk),这是我们目前首要考虑的。整体来说,综合考虑目前的 k8s 化进度、k8s 中服务注册的方式、目前业务应用微服务 sdk 的离散程度以及对业务应用的侵入性,这可能是比较现实的一套方案了。
在第 10 步额外进行了一定时间的 sleep,是为了处理那些正卡在网络传输途中的请求,这里我们默认 sleep 的时间就是微服务默认的接口超时时间。
理想的下线方案
目前下线方案的很多不合理以及妥协之处,主要还是囿于 k8s 化的进度。当应用全部都用 k8s 部署之后,配合 sidecar container,我们理想的下线方案会变成下面这样:
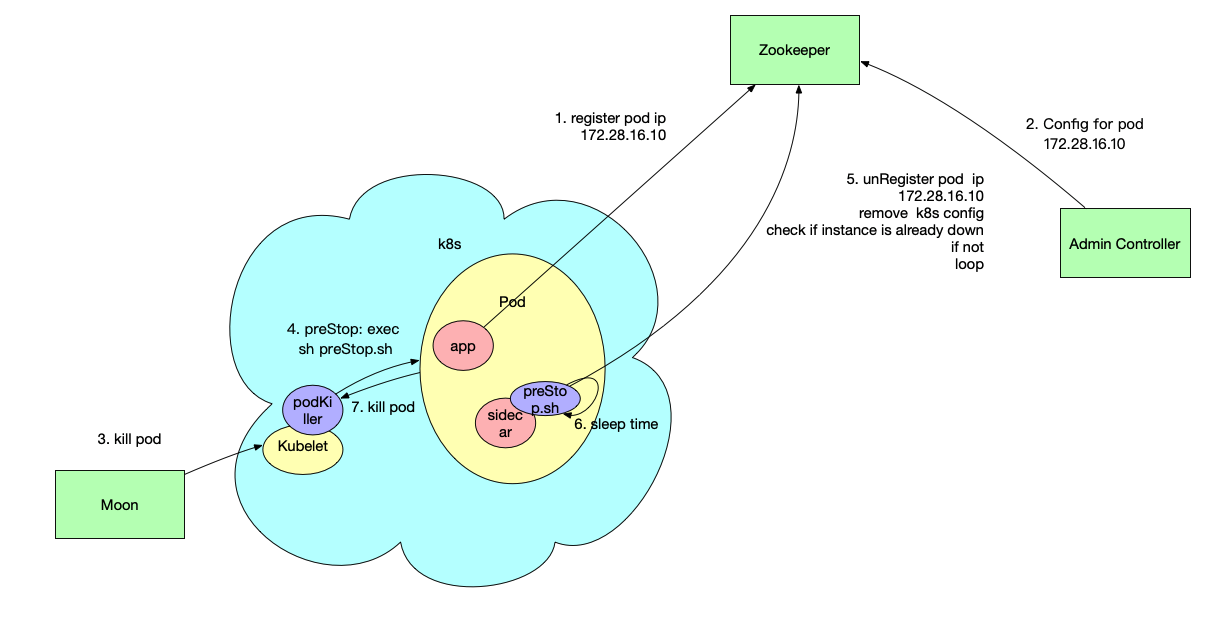
可以看到基本上微服务下线已经和 adminController 没什么关系了,所有的下线逻辑通过 k8s 的 preStop 通知到与应用 app containter 同 pod 的 sidecar container 进行执行,同时完成配置清除与二次确认等操作。这种方案避免了之后可能出现的性能隐患。并且。所有关于下线的逻辑都写在了一个接口里面,更加简洁。最重要的是,这种方案仍然可以避免对业务应用产生入侵,毕竟大家都不太愿意升级 sdk。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK