

【译文】理解布隆过滤器
source link: https://www.linuxzen.com/understanding-bloom-filter.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
原文:Understanding Bloom filters with Pharo Smalltalk。
本文通过 HTML 转录了 PharoPDS 库及其扩展附带的交互式教程,以探索和理解布隆过滤器。
因此,如果您想在真实的环境中修改这些数据结构,请尝试在 Pharo 镜像中安装这个库,并按照交互式教程并使用提供的自定义工具进行操作。
理解布隆过滤器
布隆过滤器是一个非常节省空间的数据结构,由 Burton Howard Bloom 于 1970 年所提出(Space/Time Trade-offs in Hash Coding with Allowable Errors),布隆过滤器用于测试一个元素是否是集合的成员之一。
常规的哈希搜索通过将一系列值存储在哈希表上,不管是基于链表还是开放寻址(open addressing),随着越来越多的元素添加到哈希表中,定位元素的期望时间都会从初始的常量的 O(1) 退化或增加到线性的 O(N)。
布隆过滤器提供了一个替代的数据结构,可以实现在添加元素或检查元素是否是成员上,不管在空间和时间上都可以保证常量级的性能,并且和已经添加到过滤器中的元素数量是无关的。
为了达到如此高效的表现所需要付出的代价是:布隆过滤器是一个概率性的数据结构。Bloom 他在开创性的论文中解释如下:
新的方法打算比传统相关的方法减少一定量哈希码所需要的空间。通过利用某些应用可以容忍少量的误差来减少空间的使用,特别是那些拥有大量的数据参与无法通过传统的方法保留核心哈希区域的应用。
Donald Knuth 在他著名的 The Art of Computer Programming 中写下了如下对布隆过滤器的描述:
想象一个拥有非常大量的数据且如果搜索没有成功则无需完成任何计算的搜索应用。比如,我们可能想检查一些人的信用评级或者护照编号,如果文档中没有该人的任何记录我们就无需做任何调查。类似地,在计算机排版应用程序中,我们可能有一个简单算法可以正确地连接大多数单词,但该算法会对大约 5W 个异常单词无效; 如果我们在异常文件中找不到该单词,就可以放心的使用该简单算法。
同时 Andrei Broder 和 Michael Mitzenmacher 在著名的布隆过滤器原理(The Bloom Filter Principle(Internet Mathematics Vol. 1, No. 4: 485-509Network Applications ofBloom Filters: A Survey))中提出:
在一个空间宝贵的情况下要使用列表或集合并且可以接受误报,则可以考虑使用布隆过滤器。
真实世界的例子
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章。
- Google Chrome 使用布隆过滤器识别恶意 URL。
- Google BigTable,Apache HBbase 和 Apache Cassandra 使用布隆过滤器减少对不存在的行和列的查找。
- Squid Web 代理使用布隆过滤器处理缓存摘要。
布隆过滤器可以通过舍弃元素的特征来高效的存储大规模集合,比如它仅将通过算法对每一个元素应用哈希函数得到的数字存储到一系列位上进行关联。
事实上,布隆过滤器通过一个长度(m)和不同哈希函数的数量(k)的比特数组(bit arrary)来表示。
该数据结构仅支持两种操作:
- 添加一个元素到集合中来,
- 测试一个元素是否集合的成员。
布隆过滤器的数据结构是一个初始比特位都为 0 的比特数组,代表布隆过滤器为空。
举个例子,考虑如下示例中创建的布隆过滤器表示一个包含 10 个元素的集合并且误报率(FPP, False Positive Probability)为 0.1 (10%)。
一个空的布隆过滤器将通过一个长度为 m=48 (storageSize) 和 4 个哈希函数的比特数组用以支持生产范围在 {1, 2, ..., m} 的值。表示如下:
emptyBloomFilter
<gtExample>
| bloom |
bloom := PDSBloomFilter new: 10 fpp: 0.1.
self assert: bloom size eqauls: 0.
self assert: bloom hashes equals: 4.
self assert: bllom storageSize equals: 48.
^ bloom
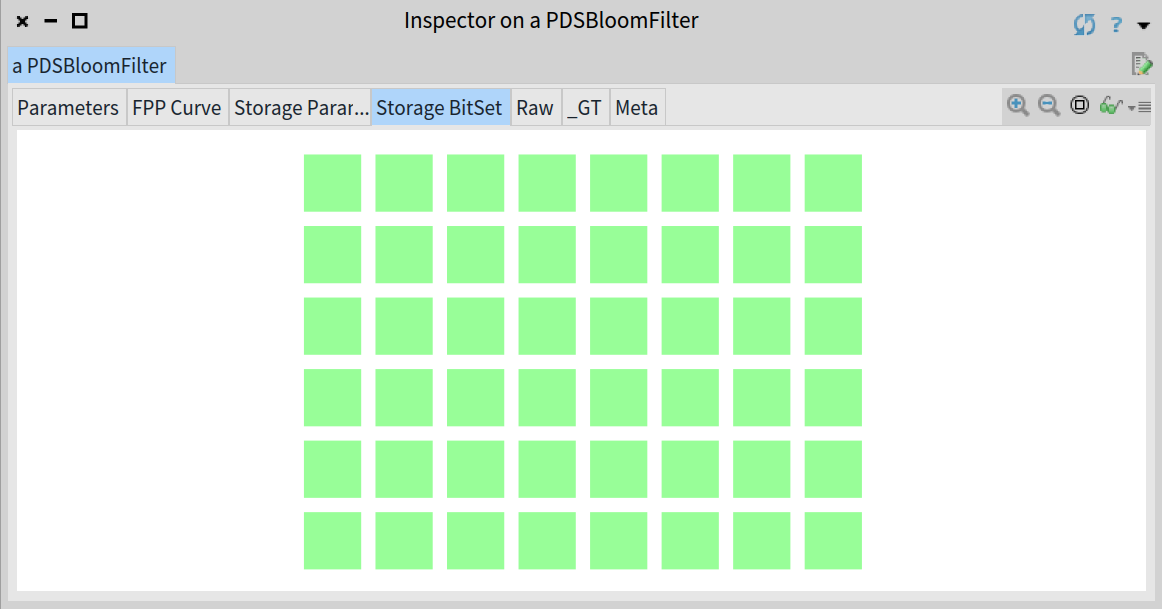
要插入一个元素 x 到布隆过滤器中,需要对元素 x 应用到每一个哈希函数 hi 上并计算它的值为 j=hi(x) ,然后将布隆过滤器中 j 对应的位设置为 1 。
作为一个例子,我们将在上面的过滤器中插入一些城市的名字。让我们通过 'Madrid' 开始:
withMadridBloomFilter
<gtExample>
| bloom |
bloom := self emptyBloomfilter.
bloom add: 'Madrid' asByteArray.
self assert: bloom size equals: 1.
^ bloom
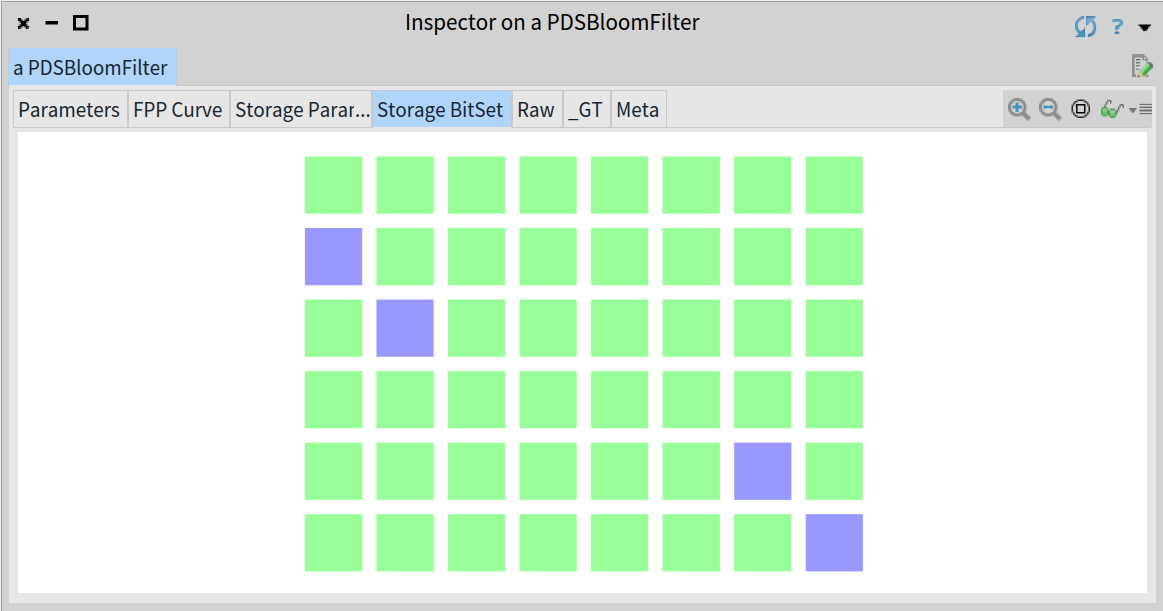
布隆过滤器计算出了 4 个哈希值用以在集合中找到关联 'Madrid' 的比特位。如上图所展示,布隆过滤器设置了 9, 18, 39 和 48 。
不同的元素可能共享一个比特位,比如现在我们添加另一个城市 'Barcelona' 到上面相同的布隆过滤器中:
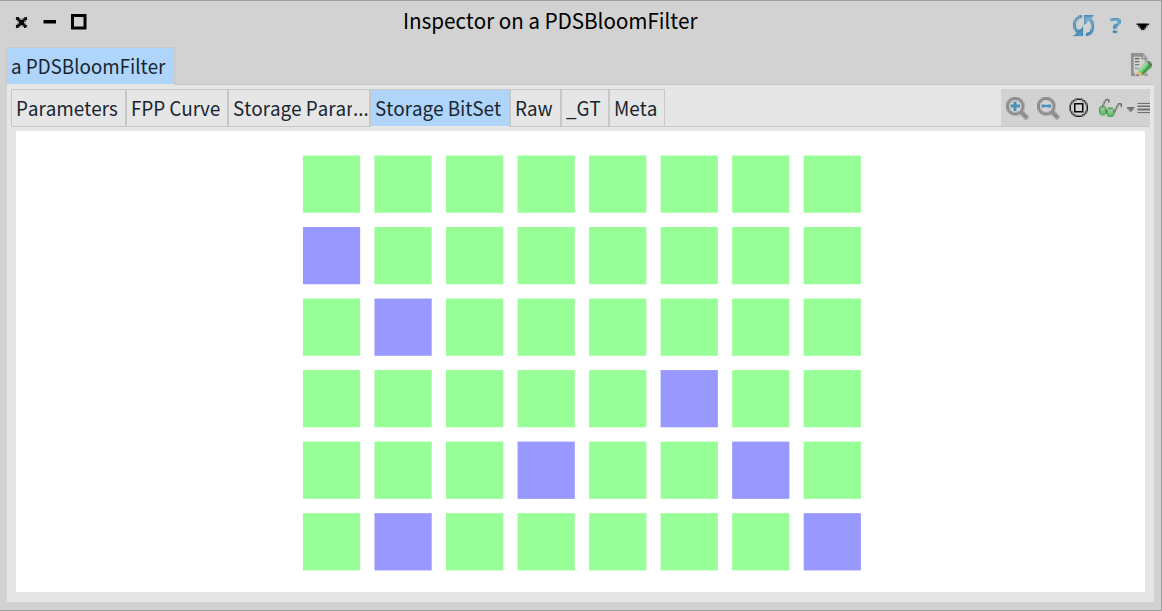
如你所见,在添加 'Barcelona' 到上面布隆过滤器之后只有 30, 36 和 42 所对应的比特位被设置,也就意味着元素 'Madrid' 和 'Barcelona' 共享了一个比特位。
要想测试给定的元素 x 是否在布隆过滤器之中,只需要检查所有的哈希函数 k 计算出的对应的比特位。如果所有位都被设置来,则表示元素 x 可能在布隆过滤器中,否则元素 x 一定不在其中。
元素存在不确定性是由于一些比特位可能是被之前添加的其他不同的元素所设置。
考虑前面的例子,在已经添加了元素 'Madrid' 和 'Barcelona' 的情况下,我们来测试元素 'Barcelona' 是否是该过滤器的成员,布隆过滤器计算出该元素的 4 个哈希值并且检查对应的比特位是否被设置,结果显示字符串 'Barcelona' 可能存在于过滤器之中,然后 contains: 'Barcelona' 返回 true :
withMadridAndBarcelonaCheckBarcelonaBloomFilter
<gtExample>
| bloom |
bloom := self withMadridBloomFilter.
bloom add: 'Barcelona' asByteArray.
self assert: bloom size equals: 2.
self assert: (bloom contains: 'Barcelona' asByteArray).
^ bloom
现在如果我们检查元素 'Berlin' ,布隆过滤器为了找到对应的比特位会通过如下方式计算它的哈希值:
withBerlinBloomFilter
<gtExample>
| bloom |
bloom := self emptyBloomFilter.
bloom add: 'Berlin' asByteArray.
self assert: bloom size equals: 1.
^ bloom
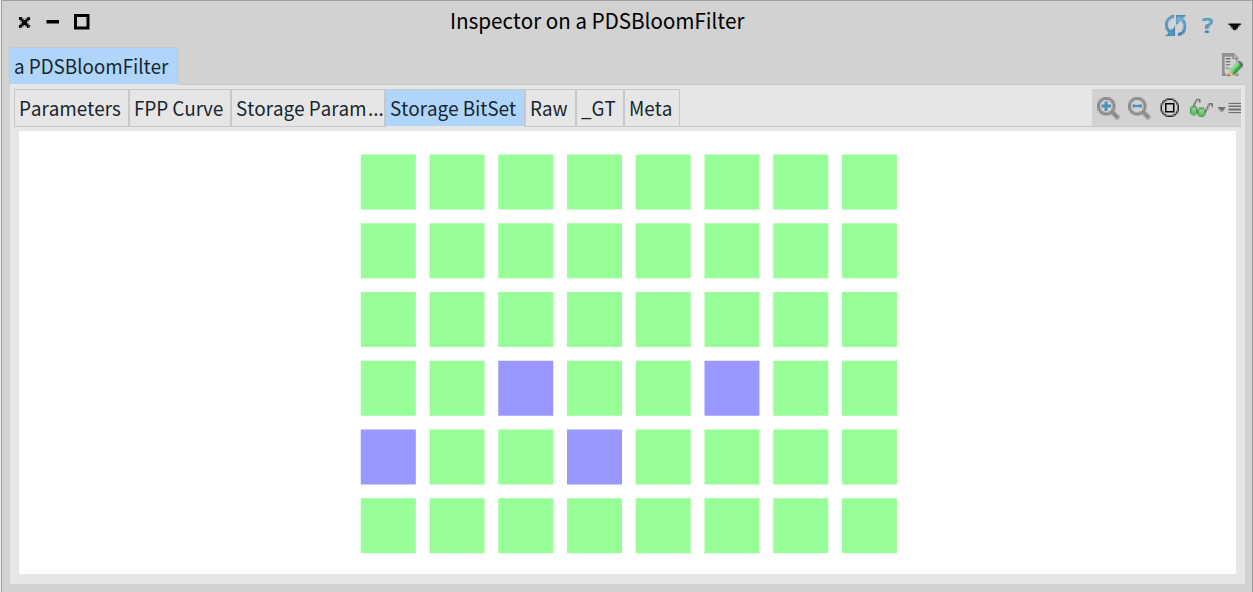
我们看到比特位 27 和 33 没有被设置,所以元素 'Berlin' 一定不存在于布隆过滤器中,所以 contains: 方法返回 false :
withMadridAndBarcelonaCheckBerlinBloomFilter
<gtExample>
| bloom |
bloom := self withMadridBloomFilter.
bloom add: 'Barcelona' asByteArray.
self assert: bloom size equals: 2.
self assert: (bloom contains: 'Berlin' asByteArray) not.
^ bloom
布隆过滤器的结果也可能是错误的。例如,考虑元素 'Roma' 的 4 个哈希值 36 由于碰撞已经在我们的示例过滤器中设置,所以 contains: 方法认为该元素可能已经存在于过滤器中。
withMadridAndBarcelonaCheckRomaBloomFilter
<gtExample>
| bloom |
bloom := self withMadridBloomFilter.
bloom add: 'Barcelona' asByteArray.
self assert: bloom size equals: 2.
self assert: (bloom contains: 'Roma' asByteArray).
^ bloom
就像我们所了解到的,我们并没有添加过该元素到布隆过滤器中,所以这是一个误报的例子。在这个特别的案例中,比特位 36 已经被前面的元素 'Barcelona' 所设置。
如我们前面所展示,布隆过滤器会对一些不是集合中的成员的元素返回 true 。这种情况被成为误报(false positive),产生于哈希碰撞导致的巧合而将不同的元素存储在相同的比特位上。在测试操作中无法得知我们对比的特定的位是否被相同的哈希函数所设置。
幸运的是,布隆过滤器有一个可预测的误报率(FPP):
n是已经添加元素的数量;k哈希的次数;m布隆过滤器的长度(如比特数组的大小)。
极端情况下,当布隆过滤器没有空闲空间时(满),每一次查询都会返回 true 。这也就意味着 m 的选择取决于期望预计添加元素的数量 n ,并且 m 需要远远大于 n 。
实际情况中,布隆过滤器的长度 m 可以根据给定的误报率(FFP)的和期望添加的元素个数 n 的通过如下公式计算:
对于 mn 比率表示每一个元素需要分配的比特位的数量,也就是哈希函数 k 的数量可以调整误报率。通过如下公式来选择最佳的 k 可以减少误报率(FPP):
我们实现的 PDSBloomFilter 建立在指定预计添加元素的数量( n )和误报率( FPP )之上,然后使用上面的公式去计算最优的哈希次数和比特数组的长度。
比如,要处理 10 亿个元素并且保持 2% 左右的误报率我们需要如下布隆过滤器:
oneBillionBloomFilter
<gtExample>
| bloom |
bloom := PDSBloomFilter new: 1000000000 fpp: 0.02.
self assert: bloom size equals: 0.
self assert: bloom hashes equals: 6.
self assert: bloom storageSize equals: 8142363337.
^ bloom
如你所见,最优的哈希次数是 6 并且过滤器的长度是 8.14x109 个比特位,大约占用 1 GB 内存。
如果布隆过滤器返回特定的元素不是成员之一,那么该元素就绝对不在集合之中。
要想从过滤器中删除一个元素需要在比特数组中取消设置相应数量( k )的比特位。不幸的是,由于哈希碰撞导致多个元素会共享比特位导致了一个比特位可能关联了多个元素。
前面计算误报率(FPP)的公式为了容易计算从而假设了哈希函数 k 的随机是均匀分布的。
换句话说,一旦将期望的 n 个元素添加到数据结构中, fpp 在 PDSBloomFilter 初始化时指定的值应该解释为期望的 fpp 的值。
例如,对于一个刚刚创建依然保持为空的布隆过滤器的 fpp 值为 0,如下图所见:
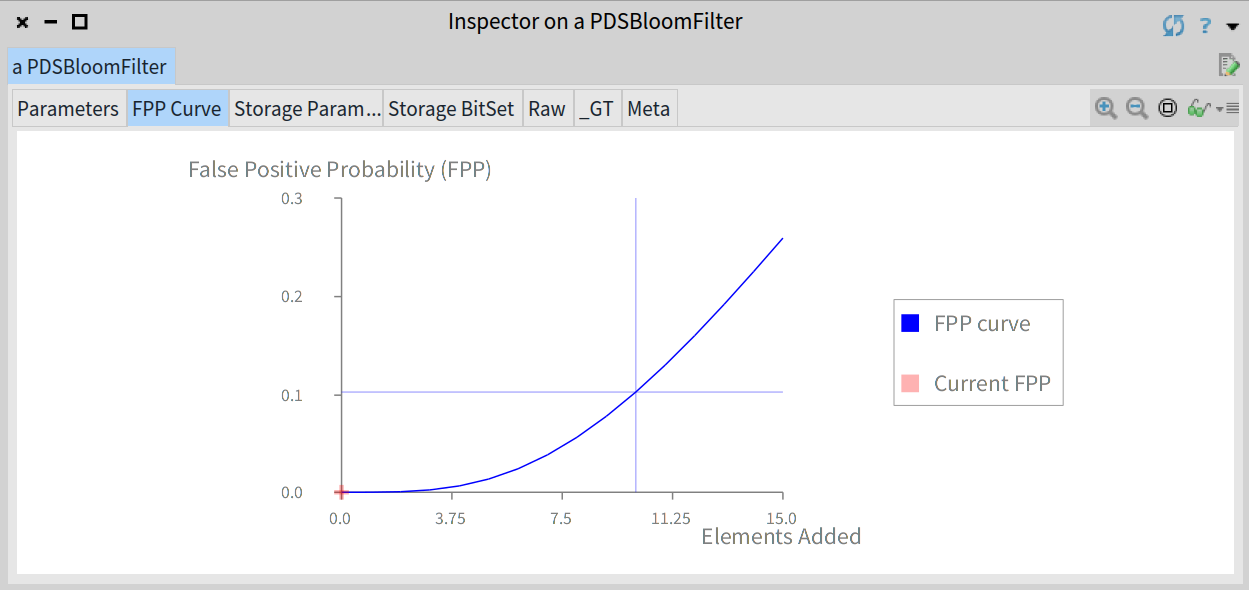
fpp 的值会随着不断的向过滤器中添加元素而增长,并随着布隆过滤器中的元素数量达到期望值而最终达到目标 fpp ,我们通过如下填充布隆过滤器:
fullBloomFilter
<gtExample>
| bloom |
bloom := self emptyBloomFilter.
1 to: bloom targetElements
do: [ :each | bloom add: each asString asByteArray ].
^ bloom
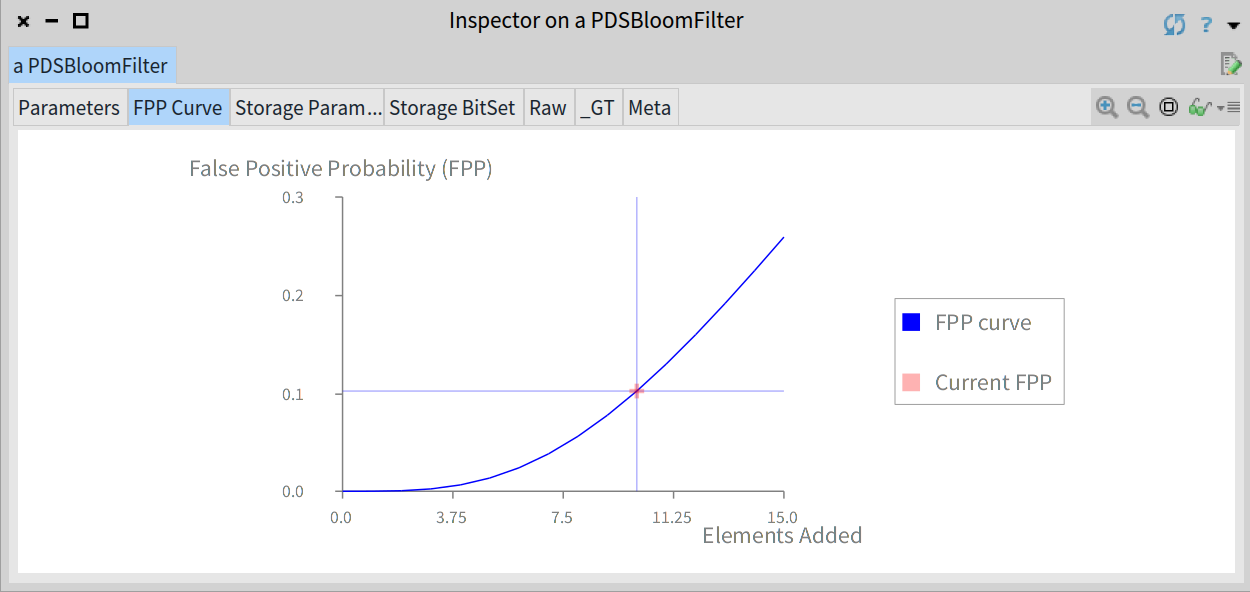
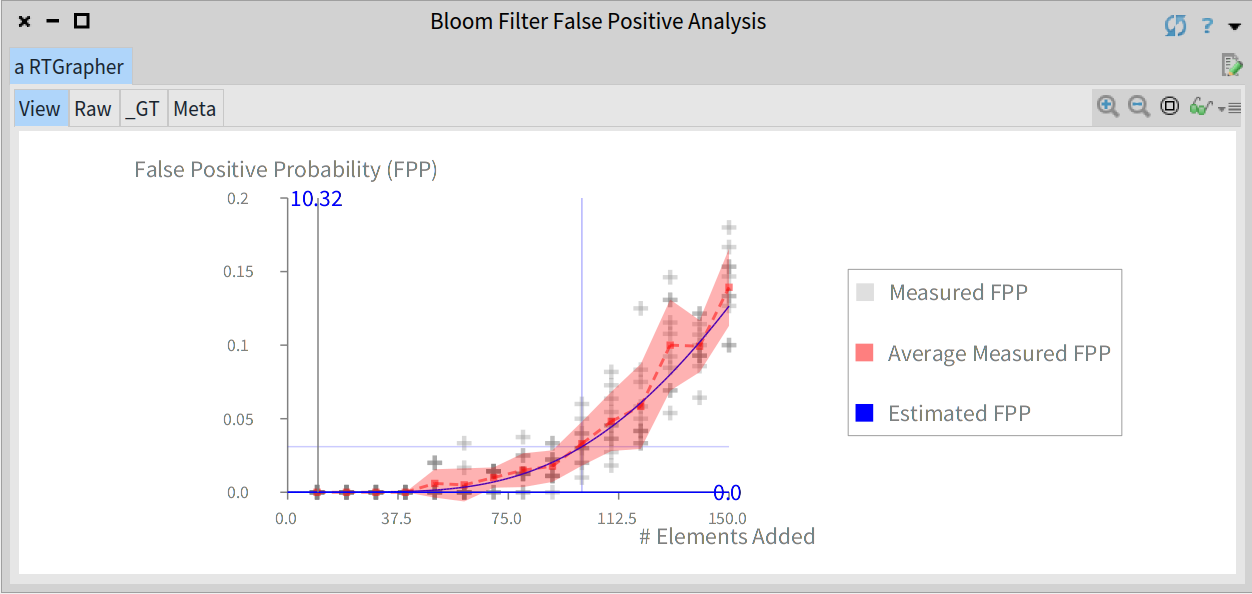
不过,你应该知道上面的 FPP 曲线是一个理论值并且实际观测到的 FPP 将会取决于特定的数据集和所使用的哈希函数。为了实验检查我们的实现的优点,我们进行了如下分析:
- 随机生成一个包含邮件地址的列表并插入到布隆过滤器。
- 随机生成一个包含邮件地址的列表不插入到该过滤器中。
- 统计在该过滤器中搜索缺失地址的误报情况。
我们运行的实验值在该过滤器期望元素个数的 10 到 1.5 倍(步长 10)。对于每种实验的元素数量运行 10 次。该分析通过一个图像展示了该过滤器的如下指标:
- 理论的 FPP 曲线(蓝色)。
- 每次实验测量到的平均 FPP 值(灰色十字)。
- 实际的 FPP 曲线(红色)
- 和标准差(红色阴影)
例如,如下代码运行上面的实验分析并且通过一个图展示一个包含 100 个元素和 3% 的 FPP 的布隆过滤器结果:
PDSBloomFilterAnalysis openFor: (PDSBloomFilter new: 100 fpp: 0.03)
一个布隆过滤器每次操作只需要固定次数的探测( k ),所以在每次插入和查找的处理只需要 O(k) 的时间复杂度,也就是常量级的。
例如,如下代码将基于在前面被填充了 10 个元素的布隆过滤器上执行查找操作来运行一个微型压测并且展示每秒钟运行查找操作的次数:
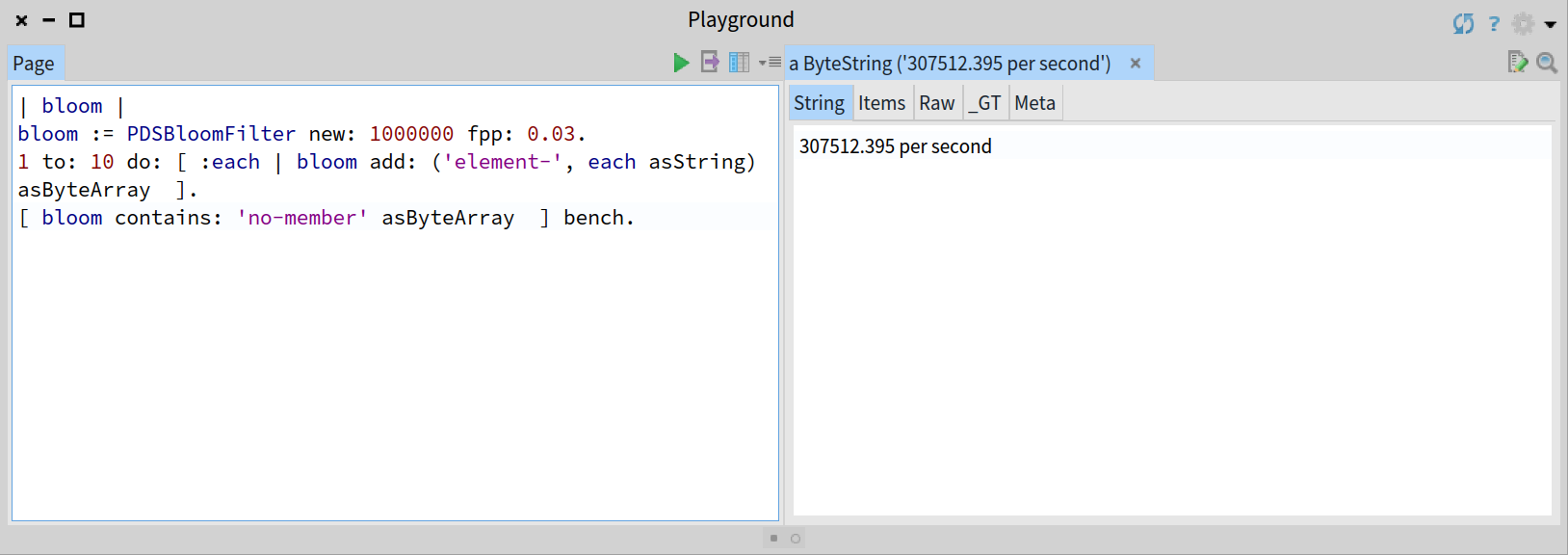
由于时间复杂度是常量级的,那么一个前面添加了 100W 个元素的布隆过滤器的查找结果应该和上面类似:
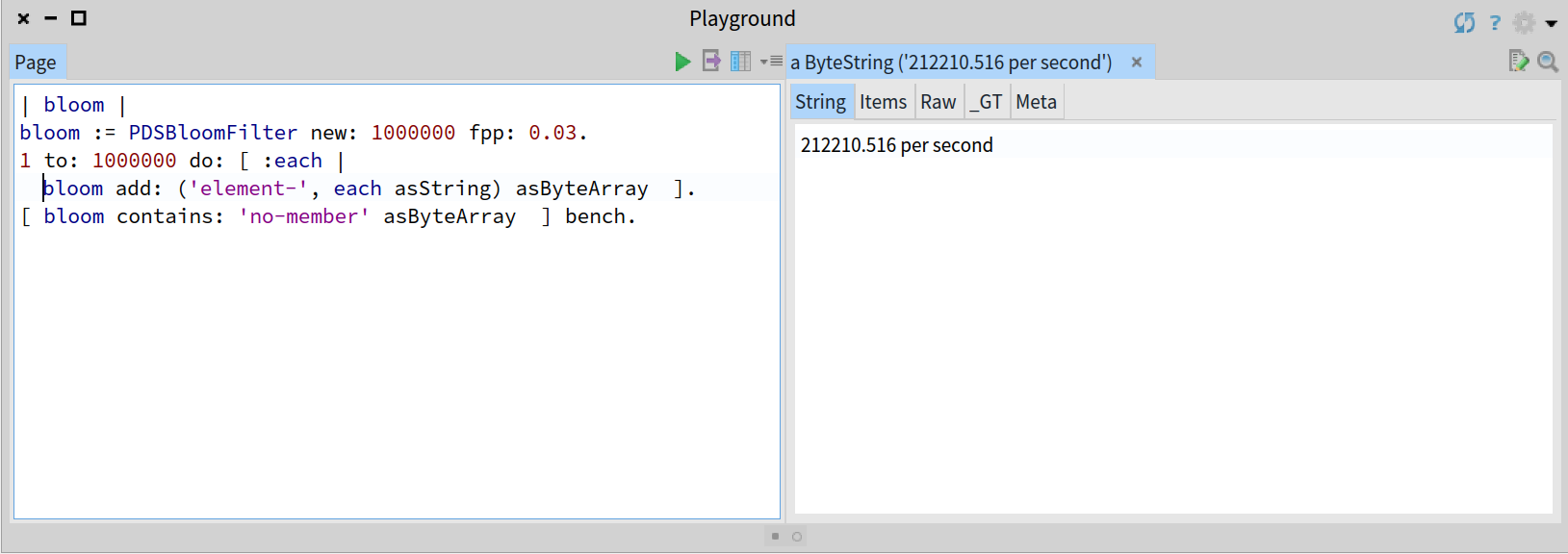
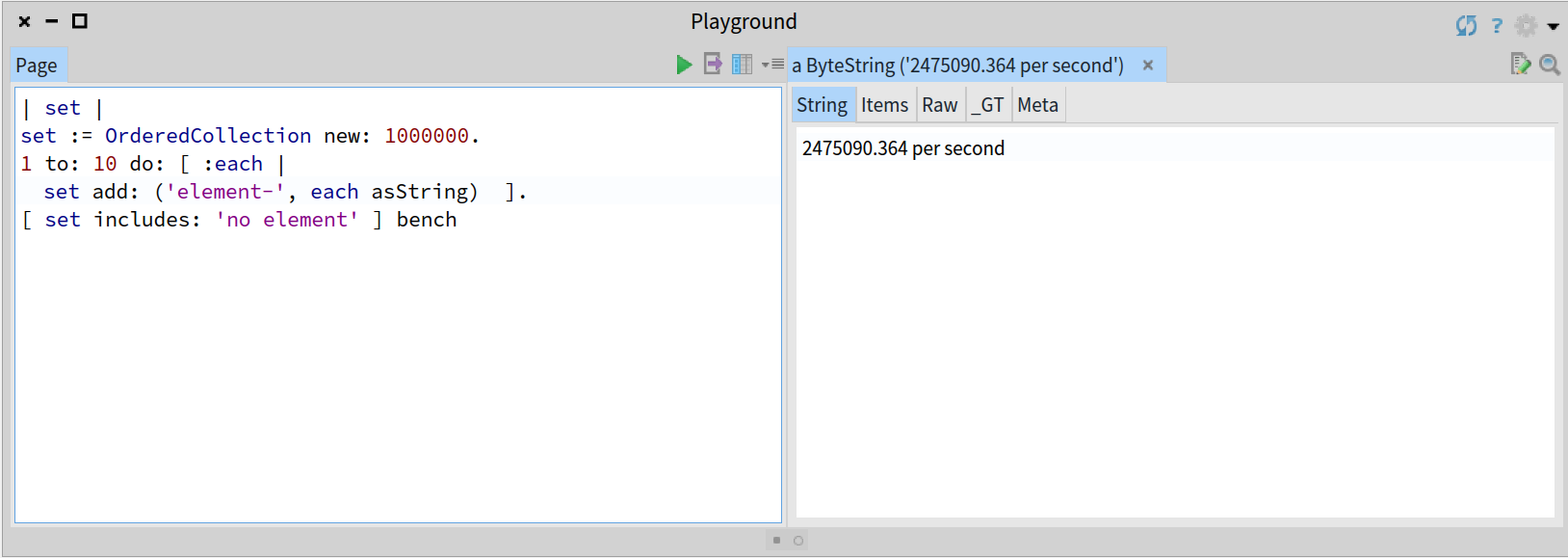
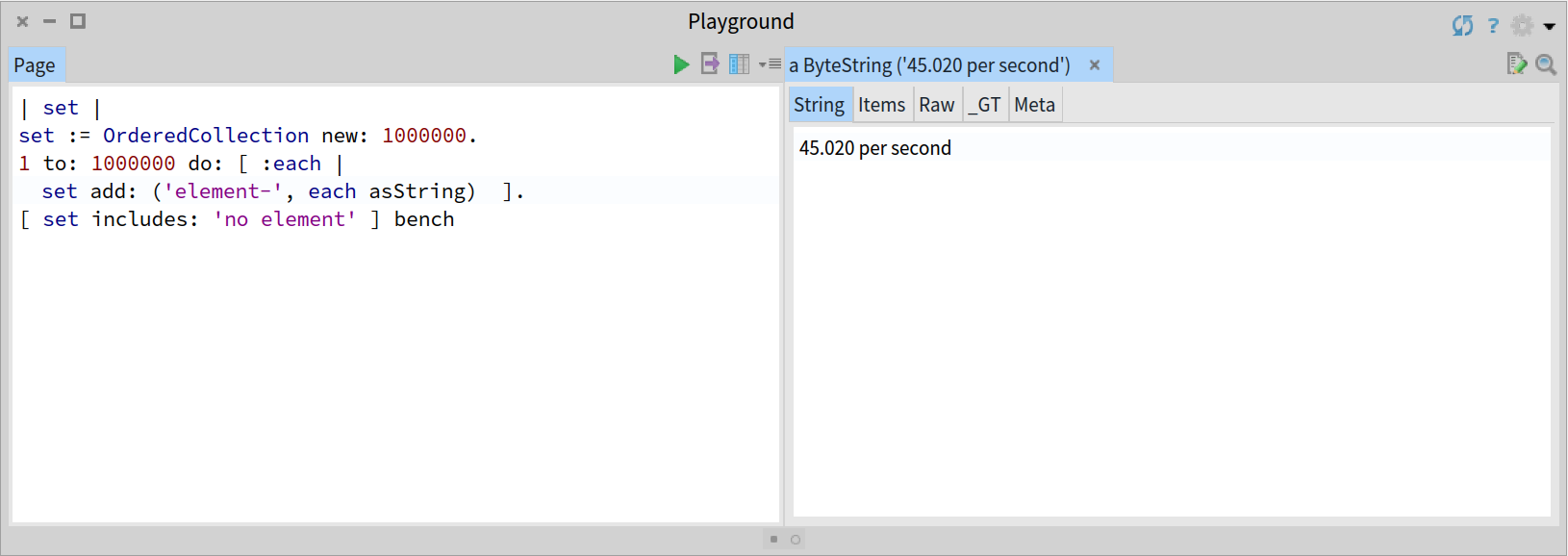
一个基于 Collection 数据结构的简单实现将是线性的 O(n) 的时间复杂度,一个有序集合的最优情况将会是 O(log n) 的时间复杂度。你可以通过观察下面压测使用一个长度为 n 的 OrderedCollection 集合的降级行为来检验:
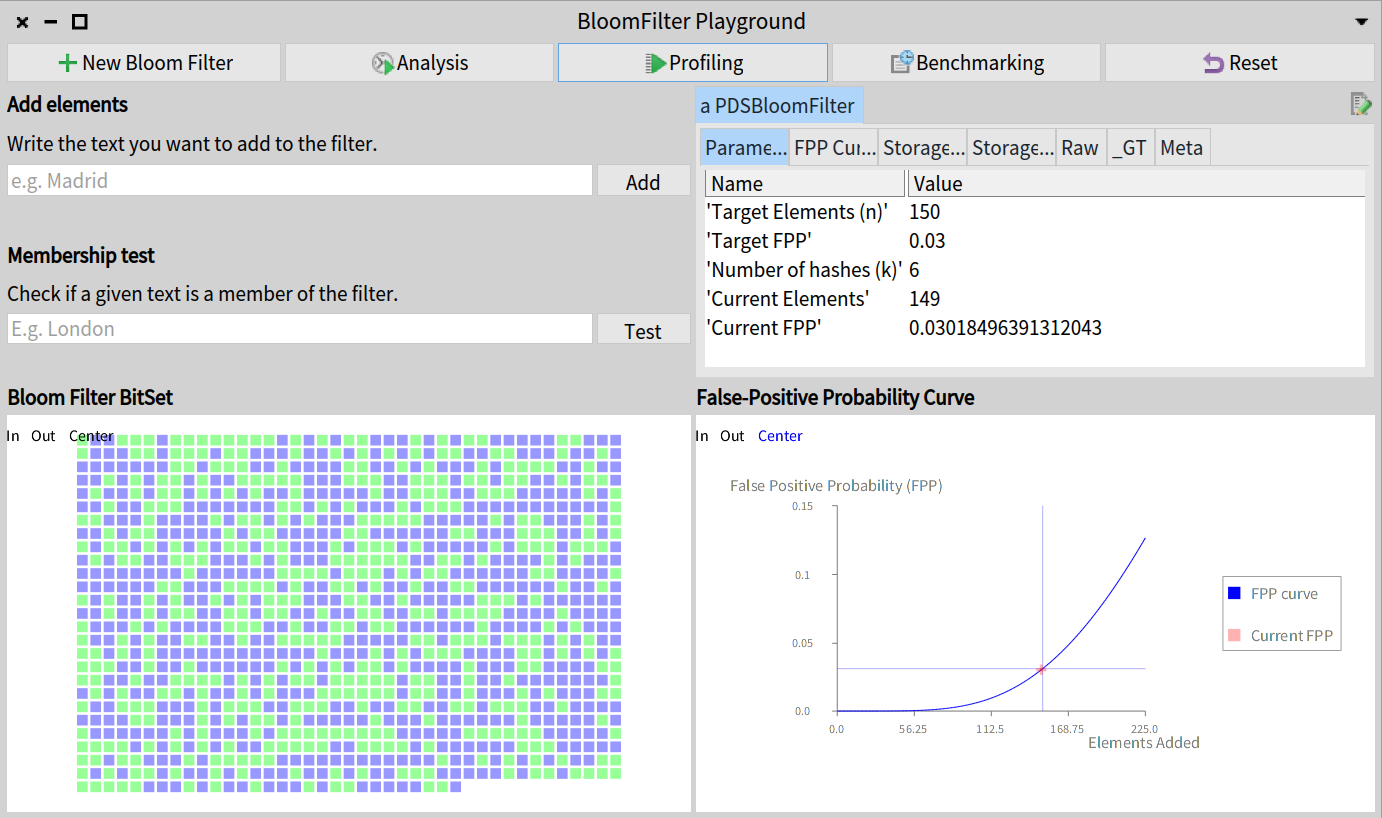
PharoPDS 提供了一个简单的工具让你可以探索和尝试布隆过滤器。
PDSBloomFilterPlayground 允许你创建一个布隆过滤器尝试一些操作并且进行可视化。甚至你可以基于 UI 运行压测和调优。
可以通过如下代码运行:
PDSBloomFilterPlayground open
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK