

Quick and dirty test of Google BigQuery's ability to scale
source link: https://www.christoolivier.com/quick-and-dirty-test-of-google-bigquerys-ability-to-scale/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Quick and dirty test of Google BigQuery's ability to scale
As a quick weekend experiment I thought it might be a good idea to look at how BigQuery scales. In order to test this out I made use of the dataset that I already created in BigQuery for my previous blog post comparing HDInsight + Hive against BigQuery.
One of the first challenges with such a test is to actually prepare some meaningful data. The original dataset had 9 years of data which totalled 227 million records and took up 77GB of space in BigQuery. If I simply inserted this data 9 times into a new table we would end up with 2.04 billion records but the size of the data in BigQuery would remain 77GB. This is all due to BigQuery being a columnar database and thus it is only storing the unique values for each column of your table.
If we used the above scenario where we have 2.04 billion records but that data is only 77GB then it would not really be anywhere near real world conditions. So instead I decided to take the entire dataset, change the dates on each insert to be a new single year and also alter all of the measures to be different on each insert by simply taking a percentage of their original value. This was done 9 times to give us our 2.04 billion row dataset. So effectively each year of data in our new dataset consists of all 9 years in the original with the measures being different for each new year.
Below is an example of the query just to show what was done (as I said, quick and dirty as I replaced the year value and multiplier, currently '2007' and 0.5, each time I inserted the data into our new table).
SELECT
cast('2007' + right(cast(DateKey as string), 4) as integer) as DateKey
,StoreKey
,ProductKey
,PromotionKey
,CurrencyKey
,CustomerKey
,SalesQuantity * 0.5 as SalesQuantity
,SalesAmount * 0.5 as SalesAmount
,ReturnQuantity * 0.5 as ReturnQuantity
,ReturnAmount * 0.5 as ReturnAmount
,DiscountQuantity * 0.5 as DiscountQuantity
,DiscountAmount * 0.5 as DiscountAmount
,TotalCost * 0.5 as TotalCost
,left(FullDate, 6) + '2007' as FullDate
,'2007' + right(Month, 2) as Month
,left(MonthYear, 4) + '2007' as MonthYear
,'2007' as Year
,left(YearName, 3) + '2007' as YearName
,'2007' + right(Quarter, 1) as Quarter
,'2007' + right(QuarterName, 3) as QuarterName
,ProductName
,ProductSubcategoryName
,ProductCategoryName
,Education
,BirthDate
,Gender
,HouseOwnerFlag
,CompanyName
,FirstName
,LastName
,MaritalStatus
,NumberCarsOwned
,NumberChildrenAtHome
,Occupation
,TotalChildren
,YearlyIncome
,DiscountPercent
,PromotionName
,PromotionCategory
FROM [retaildata.onlinesales]
By doing this we bumped the data volume up to 617GB.
Below is a screenshot of the original data.
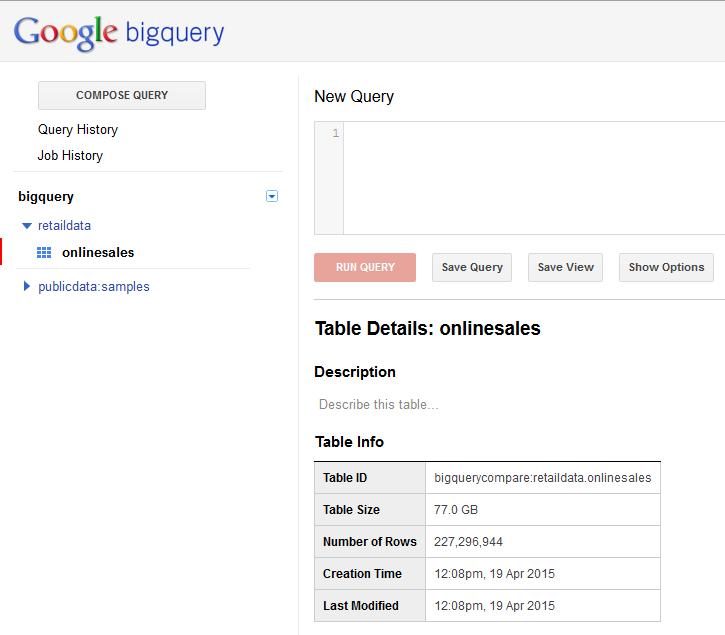
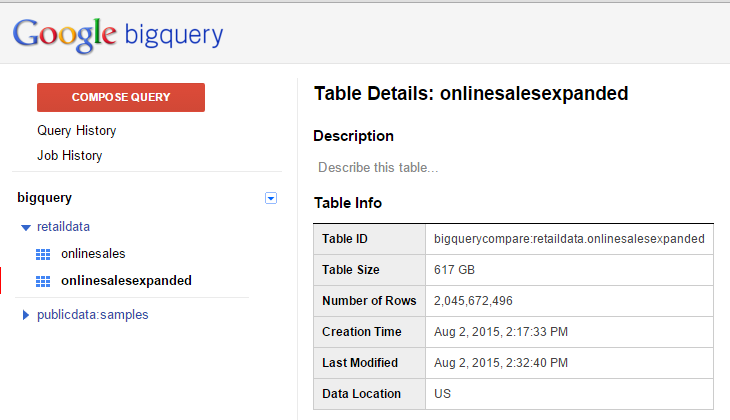
And here is a screenshot of the new expanded dataset.
To keep things simple I decided to use the two queries used in the previous blog post against the original and new datasets to measure the performance.
Query 1
SELECT YearName,
SUM(SalesAmount)
FROM TABLE_NAME
GROUP BY YearName
ORDER BY YearName
Query 2
SELECT YearName,
ProductCategoryName,
COUNT(DISTINCT CustomerKey)
FROM TABLE_NAME
GROUP BY YearName,
ProductCategoryName
Query Results
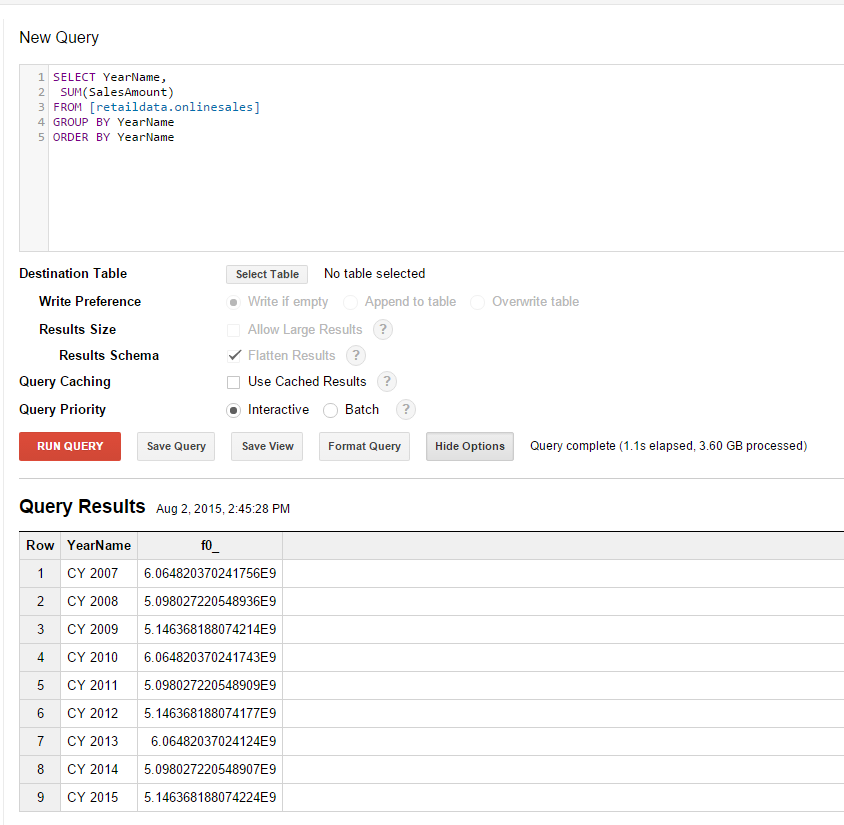
The results for the first query were as follows.
Original dataset
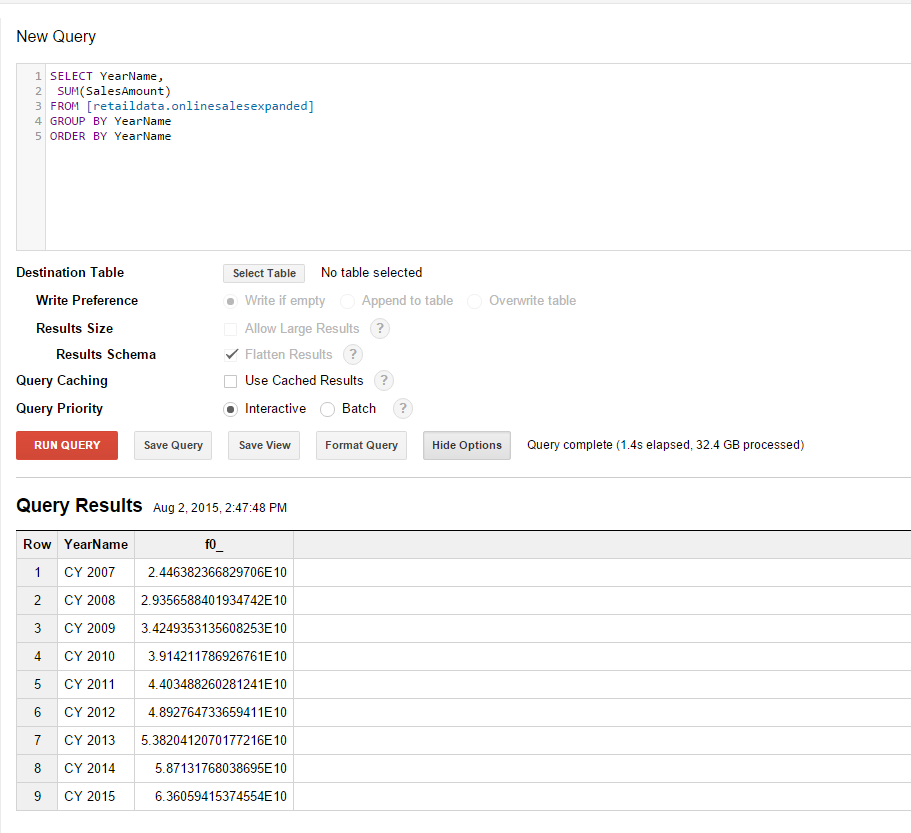
Expanded dataset
The results for the second query were as follows.
Original dataset
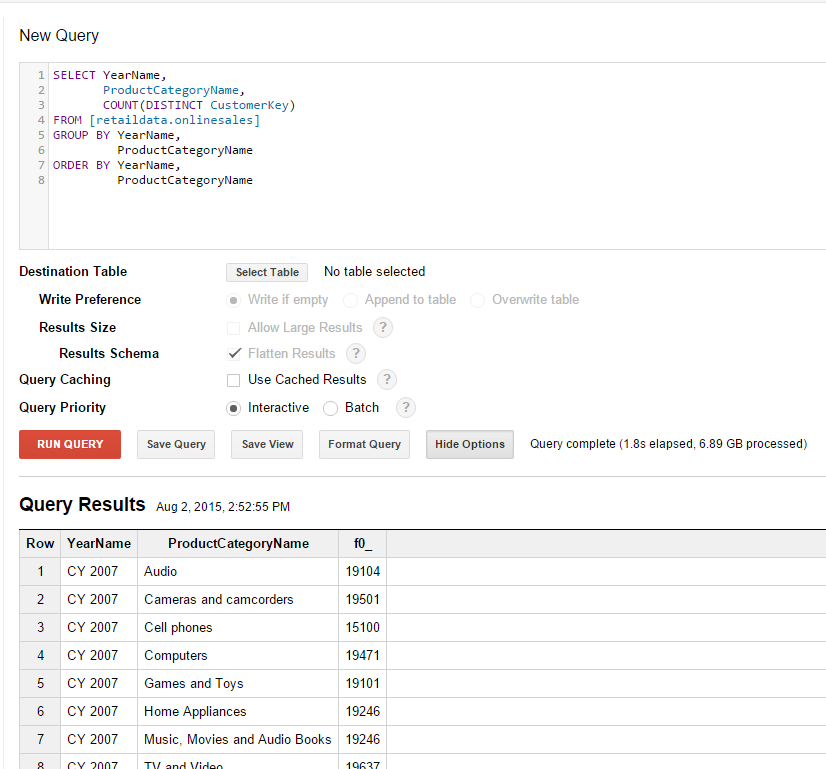
Expanded dataset
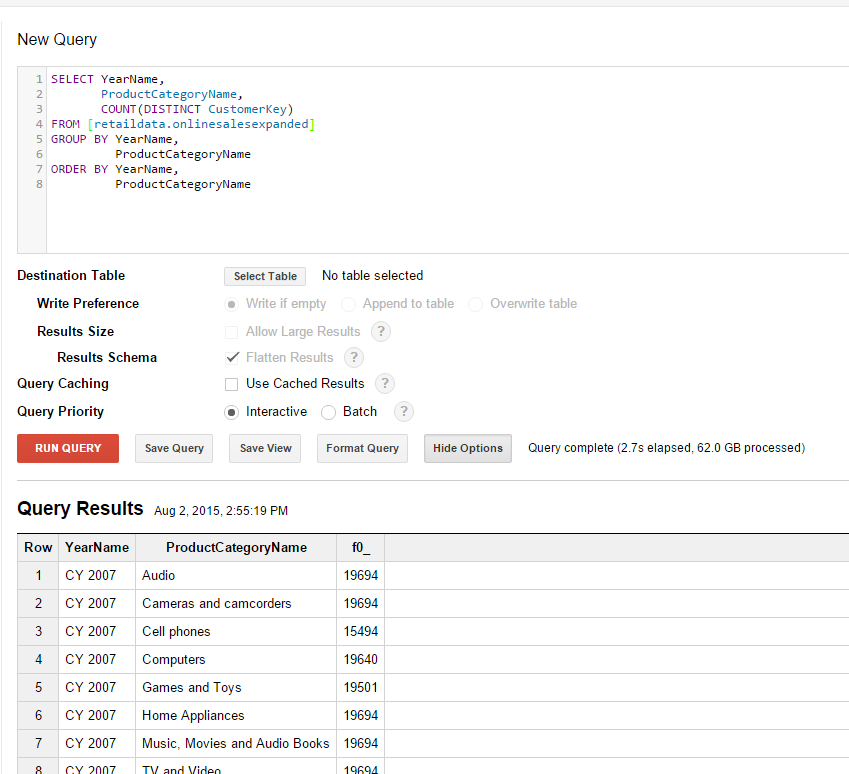
BigQuery scaled very nicely as is evident from the above results. Query 1 took only 0.3 seconds longer on our much larger dataset while Query 2 took only 0.9 seconds longer. The most impressive part of all of this is that this scaling happens seamlessly. There is no administration overhead, no adjustments to clusters or any other hardware preparation that needed to take place. The data volume increased and BigQuery simply scaled effortlessly to cope with the new data volume.
As someone that has been, and still is, involved in a lot of capacity planning for Data Warehouse and Analytics Solutions this ability to scale coupled with the fantastic pricing model of BigQuery makes it a game changing product. Simply put it is one of the most cost effective solutions with unparalleled performance capable of supporting any project from humble beginnings all the way to extremely large scale data analysis. All of this with minimal development effort and no DevOps required, leaving you to focus on solving complex business problems with data and delivering maximum value.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK