

A practical guide to small and easy-to-review pull requests
source link: https://sourcediving.com/a-practical-guide-to-small-and-easy-to-review-pull-requests-a7f04a01d5d5
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
A practical guide to small and easy-to-review pull requests
If writing a great pull request is an art form, doing a good job of reviewing them can be equally hard, time-consuming, and if left unchecked easily turn into a chore.
At Cookpad we care a lot about making code review as friction-free as we possibly can.
Like many, we’ve found it to be true that the fewer concepts and code changes a reviewer has to take in, the faster and more useful the review will be.
To this end, we have adopted a combination of:
- encouraging pull requests with less than 100 additions
- allowing unfinished features to be merged to master
Results have been good. Review and merge times have been consistently dropping:

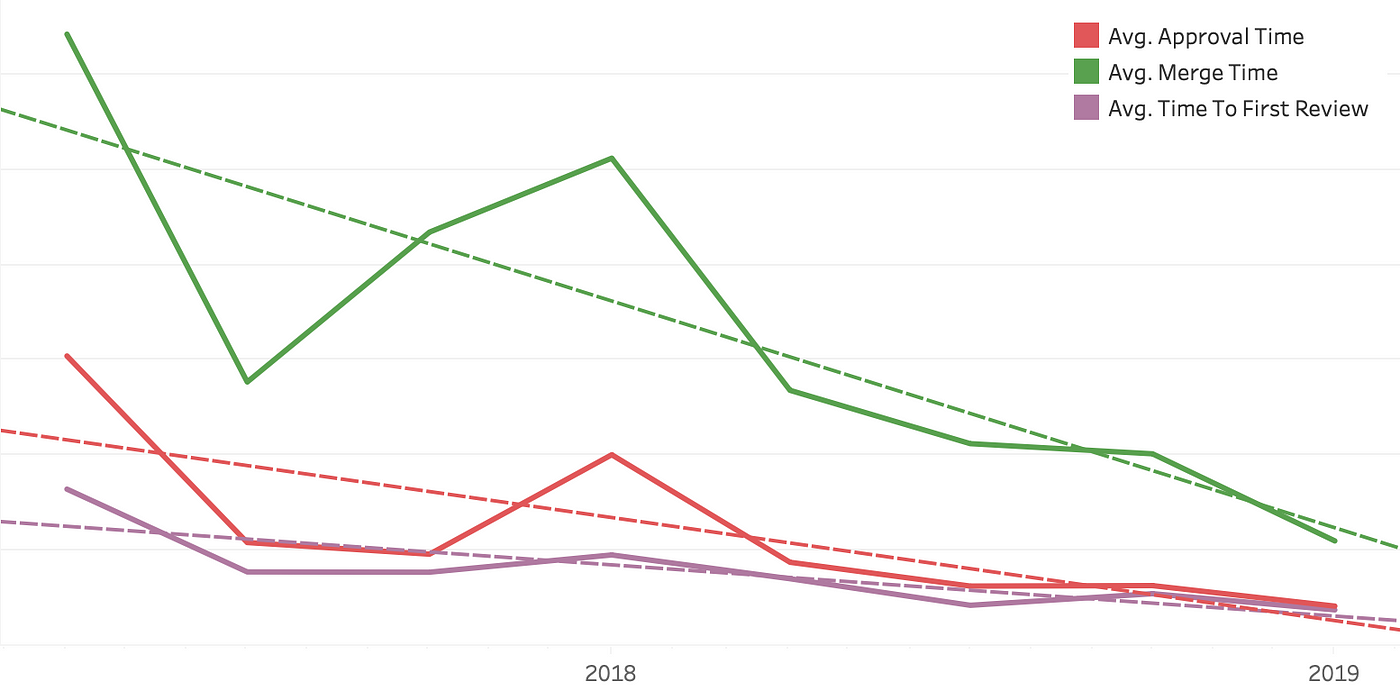
Great! So, just do small pull requests?
…turns out we had one unintended side effect of introducing this practice: a resurgence of what could be called “bottom-up pull requests”.
In the past, reviewers would often be faced with a large pull request containing all the finished parts. You might be overwhelmed with the amount of code, but at least you had the full context.
Suddenly we were seeing pull requests that were indeed small, committing for example only a database migration as the beginning of a new feature, but left reviewers thinking: “code in isolation looks good, but not sure where this is going”.
Since then we’ve been going through a process of rediscovering a top-down approach that works with our current pull request workflow.
In this blog post we’ll take a look at what that looks like.
Top-down development in practice
As an example, here is a simplified walkthrough of a recent project: an experimental feed intended to foster connections between recipe authors interacting with each other’s content.
A first rough mockup looked something like this:
Pull request #1: Building a static view
Initial inclination might be to jump straight to thinking about the database schema:
“Looks like there is some kind of
Eventrecord that is associated with auserand somerecipes. I'm going to go add a table for that!"
However, with the top-down approach, we try to forget about all that for the moment.
A first commit could instead be something as simple as a completely static page:
Based on the mockup, we can sketch out app/views/events/index.html.erb:
Controller and routing
Our controller doesn’t need to do anything beyond rendering the view:
Tests
That’s still less than 40 additions. We could even add in a rudimentary smoke test without overwhelming reviewers:
This is a good candidate for a first PR!
We have focused on just getting something on the screen, and it comes with instant benefits:
- The unfinished feature can be merged and deployed behind a feature toggle so designers can start clicking around.
- The submitter can use the pull request for sharing screenshots and filling any gaps regarding what the feature is about.
- Reviewers can focus on understanding the feature, correct usage of CSS/HTML, and basic naming/routing of the page.
Pull request #2: Driving out the model
We know we don’t want the feed to be hardcoded in the view forever, so as a next step we can start converting some of those strings to methods.
We’ll need to start making some API design and naming decisions now:
Since this is all being driven from the view, we can feel pretty good about whether the public API we’re building will work well at the top-most level.
Controller
Our view tells us that we need an instance variable @events to be set in the controller. We'll populate it with an array of "dummy models":
Model
We’re holding off on involving any kind of persistence layer yet for the events themselves. Our focus is on naming and designing the class.
Therefore, while we are beginning to dynamically fetch some data from the database, the new methods are still pretty much hardcoded:
Tests
As the behavior of our feature has now slightly changed, we can update and flesh out our test accordingly:
The total diff again is less than 40 additions and, more importantly, the number of new concepts is small.
Reviewers can focus on class design and naming, without being distracted by a large amount of new HTML and CSS.
Pull request #3: Connecting to the DB
We can see from our “dummy model” above that we have:
- something resembling relationships in
visitorandrecipe - maybe a string or enum in
action
Time to add a migration.
Migration
Model and controller
We can now convert our model to a fully-fledged ActiveRecord class:
We still haven’t figured out how to feature a recipe, it’s still in its initial naive implementation. That’s OK! Maybe it’ll come in a future PR.
We don’t have to make everything feature complete before we submit our work to the team and codebase.
Tests
Our feature is no longer hardcoded to always show the same event, so we can make use of our fully working Event class:
We still have a ways to go, we don’t know how events get created for instance, but we’re off to a good start.
At this stage reviewers, with the full context of a working page, can focus on lower level concepts such as database types and indexes, or even whether using a database is the right choice!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK