

什么是函数式编程
source link: https://zhuanlan.zhihu.com/p/173631835
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
(本文已经迁移备份到gitee项目中,不再为知乎提供内容,但对于本文,由于讨论区和内容相关,所以内容仍留在原地。后续全部内容都会迁移,完成后再删除帐号)
最近在讨论一个通过加速器加速部分计算过程的问题,谈到函数式编程支持。但看起来不同的讨论方对什么是函数式编程有不同的认识,本文尝试抽象一下这个概念,以便支持相关的讨论。
作者自己对函数式编程的认识主要来自对Python,JS和Haskell一些语法表现的认知。而作者的主工作语言主要是C和Java,前面提到的这些语言都只用于特定场合中的特殊补充,所以更多深层次的问题认识不一定那么准确。但无论如何,我们还是可以先把模型建出来。
函数式编程的本质是:把函数看作是数据。
这听起来很冯诺伊曼或者图灵机(注1),其实它就是,只是不一定每个人都对这两个概念有感性的认识。比如下面这个计算:
我们一般人认为我们给计算机提交了一个函数和两个输入,得到一个输出:
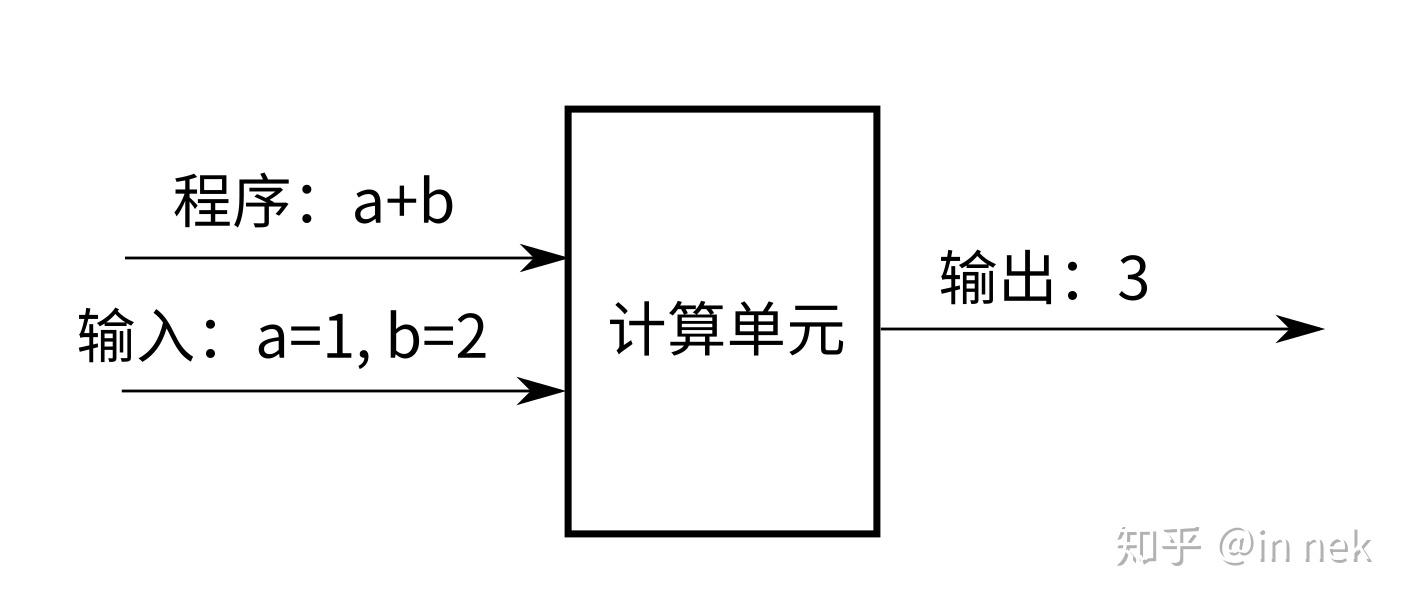
a+b这个东西能输入到计算机,本质也是一组数据。比如我们可以通过00代表a,10代表加,01代表b,给计算机输入这组参数:(00, 10, 01, 01, 02)来作为输入,把程序和输入参数同等看待,我们的计算模型就是这样的:
这种把程序(以函数为单位)当作数据使用的程序处理法,就叫函数式编程。这是它的内涵。
现在我们来看外延。看把函数变成纯粹的数据后,我们语法上会发生什么样的改变。回到前面的问题,1+2这个计算的输入,被我们分解成了这样:
output=a+b,a=1, b=2
我们把加号这种语法糖去掉,改写成这样:
output = add a b, a=1, b=2
我们可以对前面这个函数进行化简(注意了:函数化简意味着计算单元硬件的化简),让整个计算变成两步:
adda = add a b, a=1
output = adda b, b=2
在没有把函数看作是数据之前,我们函数和数据是“两种”东西,函数和数据的语义空间是互相独立的,不能一同处理。但当我们把他们看作是数据以后,这个问题就不存在了。所以,在上面这个计算中,我们看见了,对于add a b这个计算过程,其实我们是先把变量a给它输进去了,让这个有两个变化维度的算法,变成只有一个变化维度了,a+b,变成了1+b。
这明显就是《三体》中神族文明的降维攻击么。
所以,函数式编程的本质就是不断的降维攻击过程:一开始你有很多的自由度(参数),而计算的过程就是我固定你其中一个自由度,让它退化成一个降维的函数,当所有的维度的自由度都没有了,我们就完成我们的计算了。
这样就会天然地形成一个我们经常在函数式编程中听到的概念:所谓闭包(Closure)。
前面的adda中,包含了一个维度固化信息:a=1。它就构成了一个闭包。因为我们可以直接引用adda这个“数据”,而这个数据在我们的认知中,它仍有自由度,所以它仍是一个函数,它还是拥有“调用”这个概念在里面,我还可以用adda(2)这样的方式来调用它。这就很像面向对象中的“对象”的概念了:一个拥有私有数据的可调用实体。
这个把函数看做是数据,和把这个函数看做是函数指针有什么不同呢?我觉得其实没有什么不同。比如一个函数有三个参数f(a, b, c),我们把f看做函数指针(反正代码段又不会变),现在我们把f降一维,得到一个新的数据结构g=(f, a),这就构成一个闭包了。这不需要什么特别的设计(Haskell那一堆类型Match的算法和函数式编程的核心没有什么直接的关系),唯一的问题在于,编程语言需要内置(f, a)的管理,能够允许g=(f, a),可以直接进行g(b, c)这样的调用而已。
很多语言,比如JS和Python做得都没有这么直接,你不能写类似这样的语法:
f = lambda x, y : x+y
g = f(x=1)
g(y=2)因为这些语言没有Haskell那么灵活的类型匹配算法,所以它们取了个巧,要求你这样弄:
def f(x):
return lambda y: x+y
g = f(1) #g成为一个带x=1这个信息的闭包
g(2) #解封这个闭包弄得这么惨,完全是因为这些实现对函数类型是有要求的,你调用f(1),它不能像Haskell那样直接进行咖喱化(Currying),变成另一个函数,Python和JS的语法一种函数类型就只能是一个完整的调用。这只能说是一种从权,并不改变函数式编程的本质。(注2)
所以函数式编程的概念空间的核心是什么呢?我认为是“针对函数参数的语法糖”,这是针对软件的帮助,硬件对此无能为力。
本文最初的版本,我是寄望于函数式编程所暗示的:每个函数在计算中都是可以看见所有的状态,数据可以被封装在一个状态集中的,这样我们可以以这个状态集为中心来堆芯片面积。但一旦考虑到对IO等的支持,我们单独抽象函数式编程本身的特征,我就发现,其实它除了成为语法糖,没有在其他任何地方引入额外的优势,所有可以用函数式编程可以实现的功能,其实用普通的语法是一样表达的,所以最终的版本我放弃了这个结论。
评论区中有人提到Haskell中Monoid,Semigroup,Functor(注3)这些内容,我感觉和工程师是没啥关系的。这些全部都是抽象代数中群论有关的内容,你知道Manoid抽象了什么classtype,可以当C++模板那样去用它,但一般工程师(比如我)有几个能弄懂背后那一大堆定理和相关的语义?这个问题上我就不挣扎了。暂时我不认为它和“函数式编程”有什么关系。
注1:这里提到的“图灵机”,仅指一个计算系统,被一个连续的输入刺激所驱动,对一个有限的状态进行持续的更新,这样一个设计。当我们用数据来理解一个函数的时候,我们就很容易和这样一个执行机制对应起来了。至于深入的图灵机理论和数据证明等东西,和本文讨论的上下文无关。
注2:我觉得Haskell能这么作,主要原因是这些类型匹配都是编译阶段做的,所以它不太在乎这种复杂的匹配关系和过程,而Python和JS不敢这样弄,因为这个匹配过程必须在运行阶段完成的。
注3:Monoid和Semigroup是抽象对数中的,幺半群和半群的概念,大概的意思是满足结合律的代数系统就是一个半群,和半群任何值参与运算都等于原来的值的的那个元素,就是独异点,它是多维代数系统中,这一维的单位(1)。包含独异点的半群,就叫幺半群。Haskell中把一些类型定义为Monoid或者Semigroup,是为了保证组合这些类型的时候,它们在数学上是合理的,比如一个幺半群做任意代数运算,结果一定在这个幺半群内。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK