

nodejs crash如何分析和定位
source link: https://zhuanlan.zhihu.com/p/197607018
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
nodejs crash如何分析和定位
自己团队(腾讯/看点/搜索)长期招聘web前端、c++后台、搜索/推荐算法,欢迎来撩,[email protected]。
---------------------------------------------------------------------
先闲扯淡下,要把nodejs服务写挂对于一个稍微有点水平的前端开发来说,其实并不是一个容易的事。
nodejs服务异常无外乎两种情况,一是进程挂掉,二是“僵死”。进程挂掉大概有以下几种原因:一、内存泄漏,内存一点点积累到达临界值爆掉;二、死循环导致内存突增爆掉;三、死循环导致磁盘写爆;四、被动被kill,主动退出。至于“僵死”大概有以下几种可能:一、有某个非常耗时的cpu操作正在执行;二、写了个死循环(死循环不一定会导致服务挂掉,有可能只会cpu飙升,让服务处于假死状态)。
下面进入正题,背景是这样,8月1号开始频繁收到服务器异常重启的告警,翻看历史,近几个月都有不同程度的crash记录。
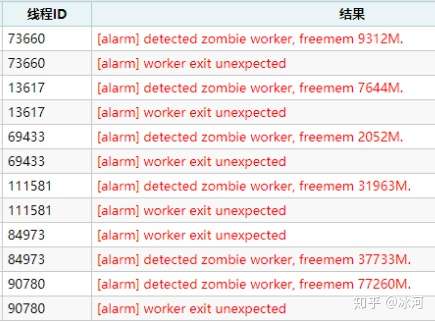
由于该crash问题越来越频繁,再加上大家手上事情都挺多,于8.4开始投入时间定位该问题。
8.4号
第一想到的是内存泄漏导致的crash,但通过taf上内存监控发现,crash时内存并不高(50%不到),而且每次crash时内存没有任何规律性,所以排除内存泄漏的可能性。
第二想到的是不是有什么js错误导致的,看代码和log后发现,错误我们都进行了捕获,在最外层我们也设置了全局js异常捕获的回调,所以也排除了业务js错误导致的可能。
因为之前听过别的同学的一个分享,利用coredump文件来辅助定位nodejs oom的案例。所以我也尝试了找coredump文件,遗憾的是没有找到。但我相信如果是oom的case,当你不能从log和代码看出端倪时,coredump文件分析一定会是一个不错的选择。
最后,通过仔细观察taf监控,发现每次crash的时候磁盘io飙升很多,所以“会不会是因为磁盘打爆了”。
然后登上服务器一看log,满屏幕都是log文件,大部分都是10G左右,有些可疑,但内心里还是觉得可能性不大,毕竟磁盘空间还有富余,也没收到磁盘不足的告警。抱着试一试的心态进行了第一次尝试:删掉多余的日志,把log的输出级别从info改为了error,去掉重复的log。
8.7号
等待发版,等待crash,这一天到来后不出所料,继续crash。log的日志从之前的10G级别已经降为了1G左右,所以可以排除上面的猜测。
这就让我重新整理了思路,crash的原因是检测到僵死进程。什么是僵死?主进程和子进程间会通过心跳来判断子进程是否“僵死”,如果僵死主进程会kill掉子进程然后重启拉起一个新的进程,最大可能性的保障服务的稳定性。
什么会导致僵死?死循环(或者某个非常耗时的方法)。这回我比较坚信是因为业务逻辑的某个死循环导致的,很可能是因为一个特殊的请求(甚至有可能是安全扫描),触发了某段特殊的逻辑,导致死循环,占用线程cpu资源,让心跳一直发不出去。
但这个时候我发现log依然很大,即使定位到crash的那一秒,依然有成千条日志需要去看,干扰因素太多,所以进行了第二次操作:精简日志,把没用的日志全部删除。
8.12号
这回日志清晰了很多,每个请求对应唯一一条access日志,但这时候我才意识到另外一个问题,每个nodejs节点会起3个进程,而这三个进程的access日志会往同一个文件中打,导致了另外两个进程的日志干扰了我的判断,所以日志还得按进程维度来打。
为了方便查看日志,我把日志修改为按进程id打,每个进程id打一个日志文件,这时候我的认为crash时只需要看这个进程处理的最后一次请求是啥就行了。
8.17号
忙碌了一阵子,忘了这事,等回想起来又过去了好几天。
继续观察crash的进程log,发现最后一个请求并没有什么特殊,而且也不是固定的,一点可疑的味道都没有。
这时候的我冷静分析了下,每个请求要处理的异步任务很多,比如有ABC三个异步事项要处理,但如果真的crash在C,意味着AB两个阶段还可以处理请求,所以只看最后一个请求并不合理,有可能导致crash的请求在前面。
这时候我又做了两个事情:
1. 去掉安全扫描,看下去掉安全扫描后是否还会crash
2.在每个请求返回时也打了一个log(res.end和res.send时),如果有导致死循环的逻辑那么一定只会收到进来时的日志,并不会留下返回的日志,crash时只需要看哪个请求没有返回log即可
8.21号
很遗憾,发现依然crash,一是排除了安全扫描的影响。
再就是请求都是成双成对的出现,也排除了异常请求的影响。
这时候问题的定位就陷入了死胡同,之前所有的怀疑都被推翻。
。。。。。。。。
直到我发现有些进程僵死后过了10分钟会再次crash,这个时间不多不少,刚刚好10分钟,这才出现转折点。
我即刻把注意力就放在了定时任务上面去,搜索整个项目,并未发现有任何半小时内的定时任务。
那一定是框架层面的定时任务,这时候我就想到了主进程和子进程之间维持的心跳,一看代码间隔是5分钟,逻辑判断是“>”不就刚好是10分钟吗,直觉告诉我这里很可疑。
有没有可能是服务根本没有死循环,而仅仅是因为该发心跳的时候没有发送而已?
为了验证我的判断,我在框架层打了两处log:
1. 子进程给主进程每1分钟发送心跳时打了一个log
2. 子进程起了一个定时任务,每10秒打印一下内存情况
等待再次crash后拉出log一看,10秒的定时任务一直在执行,直到最后一刻,内存都很正常,这里就排除了死循环和内存问题导致的crash。
心跳却有几分钟没发送,10秒任务和心跳的任务都是用的setInterval,这就没道理了,仔细一看发送心跳的代码后才发现端倪。
发送心跳的setInterval用了unref这个方法,js中timer的实现跟宿主环境有关,跟V8没关系,所以nodejs的版本就有可能导致差异。
发现这个问题后立即咨询了团队的小伙伴我们是否修改过nodejs的版本,得知了一件事情,就是两三个月前有同学把nodejs的编译机从12.X的版本降到了11.X,这个时间跟出现crash的时间又刚好对上,内心一阵欢喜。
最后满怀希望的进行了最后一次尝试:升级nodejs版本为12.X。
发版后再没发现crash的问题出现,happy ending~
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK