

The Differences Between Interpreter and Compiler Explained
source link: https://thevaluable.dev/difference-between-compiler-interpreter/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

The Differences Between Interpreter and Compiler Explained

“Why would I care about the difference between interpretation and compilation?” ask Dave, your colleague developer. “After all, this is a low level detail, and I don’t care about that! That’s why we have abstractions all over the place!”.
Dave is wrong, in many aspects. First, knowing the foundations supporting the high level abstractions you use every day, as a developer, will give you an edge to understand quickly whatever is built upon them. Programming languages, frameworks, you name it. Second, knowing the difference between compilation and interpretation will help you debug, improve performances, and deploy the software you’ve built. It’s a very important subject we need to understand, even roughly.
So today, let’s dive into the differences between interpretation and compilation. We’ll see together:
- How a computer execute a program.
- How a compiler works.
- How an interpreter works.
- The advantages and drawbacks of both solutions.
This article is a (gentle) introduction to the topic. I won’t cover everything in details. If you’re interested to dive more, feel free to contact me or to let a comment. I’m always happy to help, or to gather suggestions for a future blog post.
I hope you’re ready! This article is packed with information, so take your time and don’t hesitate to come back to it.
Interpreted And Compiled Programming Languages
As humans, we love categorizing things to make sense of the world. Also, it prevents our brain to burn out with too many details to consider at once. But sometimes these generalizations don’t hold a lot of truth anymore. It’s not different for programming languages; we often speak, as developers, about interpreted programming languages and compiled programming languages, two convenient categories.
If you need to remember only one thing from this article, it’s this one: every programming language can be interpreted or compiled.
For example, PHP is very often interpreted in real life projects, that’s why we put it in the “interpreted programming language” category. But if you’re Facebook and you write a compiler for PHP, you have now a “compiled programming language”.
These categories don’t qualify a programming language, but the common way we create program with these languages. That’s an important difference to have in mind.
With that out of the way, let’s descend into the depth of your Computer, tackling the Orcs and Dragons of the Dark World of Compilation™.
The Heart of Your Computer

To understand what a compiler and an interpreter can do, we need to dive a bit into the lowest level of the abstraction stack first.
Machine Code
If our best friend the computer had a heart, it would be the CPU (Central Processing Unit). You’ll heard about it as well under the names “processor”, “main processor”, “THE processor”, and other cute names.
What do you want a software to do? Things, like calculating or displaying something. You want it to execute a bunch of instructions you communicated by writing source code.
What does a CPU do? It executes a bunch of instructions! How practical! To do that, it will control and coordinate the hardware of your machine. “The goal becomes clear!” scream Dave, your colleague developer. “I’ll speak with the CPU for it to do stuff!”.
Here’s the problem, though: Dave and the CPU don’t speak the same language. As humans, we can communicate with words, sentence, and even beautiful high level code. Your CPU, as a mechanical being, speaks only machine code, a purely numerical language.
Indeed, a CPU only understand numbers represented in binary. “0” and “1” will be its only letters, to form more complex numbers (called, surprisingly, words), which will have more complex meanings, or semantics.
To make the matter worst, different CPUs don’t speak the same machine code. Each family of CPU understand a precise set of instructions, called as well ISA (Instruction Set Architecture), or simply CPU architecture. Even in the same CPU family, the architecture can be a bit different from one CPU to another.
This set of instruction include:
- Logical operations:
and,or, bitwise operations… - Arithmetic operations: add, multiply, subtract, divide…
- Data transfer: memory management inside or outside the CPU.
- Flow control: branching, conditional executions…
For example, on a PC, you’ll encounter mostly the x86 CPU architecture family, used by the behemoth Intel. On mobile, you’ll encounter often the ARM family.
For your specific CPU to understand you, you’ll need a translator. It’s a very generic term which refer to anything that can translate code from a programming language to another. You’ll need, one way or another, to translate your high level code (PHP, C++, C, and whatnot) into machine code.
But there is another problem. As a mere human, you can’t ask everything you want to the CPU. It’s the Eternal and Mighty God of your computer, after all. It can do many powerful things, even harmful things. If every program written by everybody could do everything on your computer, it would lead to huge security problems.
That’s where your operating system (OS) comes in the mix (Windows, Linux, Android, MS DOS, Plan 9… you name it). If your program want to do any direct operation on the hardware, say writing to the disk, it needs to ask your OS the permission via system calls.
If the permission is granted, your OS will then instruct the CPU to do whatever you want to do. Since the OS plays such an important role between your source code and the CPU, the machine code needs to use some APIs from your OS to get the authorizations it needs. That’s one of the reason why so many programs can run on a specific OS, but not on another.
Assembly Language (ASM)
During the rise of computing, humanity understood that giving instructions to the CPU in binary was not the easiest thing to do. They tried to abstract the machine code into a first programming language, called assembly language. It has almost nothing to do with the high level languages we are used to, in this day and age.
An assembly language is a bit easier to read than machine code: there will be mnemonics looking like English words in there, not only binary! It stays very close to the instruction set of the CPU however, that’s why an assembly language will often be tied to a specific CPU and its instruction set.
To translate assembly language to machine code, you’ll need a program called an assembler. It will take the assembly as input and spit some machine code as output.
What’s a Compiler?
Here we are, finally in front of the Compiler Beast!
A compiler is a set of tools which translate code in a programming language into another programming language. It can be often defined as a translator from a programming language to machine code, but it’s not necessarily true. You can compile C into the programming language Pikachu for example, if you have a compiler which does that.
An Overview With gcc
Let’s go through an example by using the gcc compiler, which can compile C code into machine code. If you have gcc on your machine, you can follow along with me. It’s easy and not painful, I promise! Just open a terminal and type gcc. If you have a nice fatal error: no input file message, you’re good to go.
Let’s first create a new file called conquering-the-world.c and let’s copy this fantastic code:
#include
int main()
{
printf("Hello world! I'll conquer you! \n");
return 0;
}
Now, let’s use the terminal to compile our code, by running gcc conquering-the-world.c -o conquering-the-world. BAM! The compiler just translated your ambitious code into machine code, in the blink of an eye. Where is it? In the newly created conquering-the-world file. A file containing machine code is commonly called a binary file, or an executable.
If you run it in your terminal, it will unsurprisingly display “Hello world! I’ll conquer you!”.
Since you should doubt everything you can find on the Internet, how can you verify my claim that it’s indeed machine code in this file? If you try to open it with an editor, you’ll just see a bunch of gibberish which is very different from the “0” and “1” you’ve expected. That’s normal: your text editor always try to display characters from some alphabet, so it will try to translate this bunch of “0” and “1” into human-readable characters.
If you have the program xxd installed on your computer, you can display the machine code from your binary, by running the command xxd -b conquering-the-world. Since you burn with impatience to see how it looks like, here’s an extract:
00003f90: 00000000 00000000 00000000 00000000 00000000 00000000 ......
00003f96: 00000000 00000000 00000001 00000000 00000000 00000000 ......
00003f9c: 00000000 00000000 00000000 00000000 00000000 00000000 ......
Welcome to the weird realm of machine code!
Using gcc again, we can have an overview how the compilation itself is done, without going into too many details. It’s time to run gcc -save-temps conquering-the-world.c -o conquering-the-world!
It will create four files, each representing one step of the compilation process:
- Preprocessing: removing comment, expanding included files and tokenization (grouping semantics together) -
conquering-conquering-the-world.i - Compiling: your C code is compiled in assembly language -
conquer-the-world.s - Assembly: an assembler translates the assembly code into machine code. You end up with object code. -
conquer-the-world.o - Linking: gather every library (depending on the OS you want your program to run on) and other object files the program needs, link them to your code, and translate everything into machine code.
If you want to give your ambitious program to a friend who has a different CPU architecture, you might think it won’t work. Indeed, as we saw, your compiled machine code is only understandable by your CPU architecture. Fortunately, gcc will create machine code which can run on different (most common) CPU architectures! It’s called cross-compiling. It has some performance drawbacks, but your friend will be able to conquer the world with you!
All of that makes the implementation of a compiler like gcc very complex.
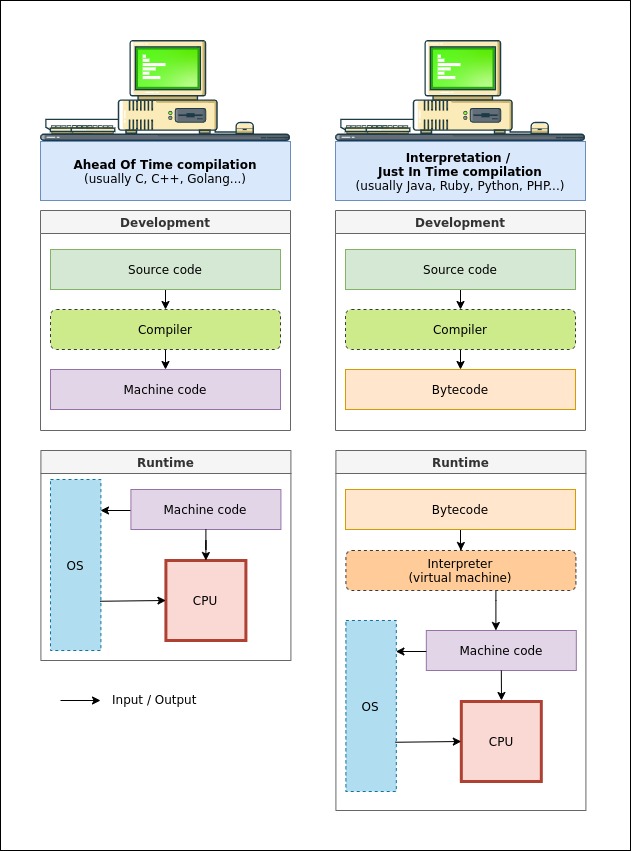
This specific compilation process is called Ahead Of Time compilation (AOT), because your entire source code is translated to machine code without even be executed once.
Let’s have now a quick overview how a compiler can be versatile for different CPU architecture, or even different programming languages. We can roughly divide a compiler in two parts:
- The front end
- The back end
These two parts will perform hundred of transformations from your code source to the machine code. There is as well an optimizer which runs between the front end and back end.
The Front End
It’s where syntax and semantic analysis takes place. It’s where type checking for statically typed languages is done, too. From there, an AST (Abstract Syntax Tree) will be created. For example, gcc can compile source code written in different programming languages like C, as we saw, but as well C++, Golang, Fortran, Objective-C, and more. You’ll need a specific front end for each language you want to compile.
The Back End
The back end will read the AST generated by the front end. It will then output the machine code depending on a targeted CPU architecture. For example, some back end will create assembly and/or machine code for x86 CPUs only. If you want to do cross-compiling like gcc does, you need multiple back end.
For PC and Macs, CPU’s instruction sets are similar, and many compilers will target them. Problems can arise for embedded systems, which can have very exotic architectures. If you want to create software on these systems, you might need to use compilers provided by manufacturers of these embedded systems.
What’s an Interpreter?

Compilers are great, but what about interpreters? Historically, an interpreter is a program reading the source code you wrote, line by line. Each line was translated to machine code and fed directly to the CPU while executing the program. For example, the programming language BASIC was interpreted using this method. It means that each time you execute your code, this line-by-line translation have to take place. This was pretty slow and costly, so the way we interpret our high level code changed over the years.
Nowadays, to interpret your code, you’ll need to compile it into another form of code, called bytecode. This code is designed to be interpreted efficiently by a specific interpreter, or virtual machine. It looks pretty similar to assembly, even if it’s even less readable.
“Wait a minute!” claims suddenly Dave, your colleague developer. “Why interpreted code is first compiled? It doesn’t make sense! I thought that interpretation and compilation were completely different!”
Dave’s worries are understandable. Compiling first your code into bytecode is 10 times more efficient than interpreting the source code you wrote directly into machine code. The fact that you use a very generic bytecode makes the virtual machine dependent of the OS, but not the bytecode itself! This is one of the biggest advantage of interpretation.
Let’s take an example. The JVM, or Java Virtual Machine, is often used to run Java programs. It exists different implementations of the JVM: one for Linux systems, another one for Windows, and many other ones for different OS or embedded systems. Java programmers first compile their programs into JVM bytecode. Then, the different virtual machines will always take the same bytecode as input and spit whatever machine code a CPU needs.
As a result, you can develop your Java program once, and, since it’s always compiled to JVM bytecode, it can run anywhere a JVM can run! Your source code stays the same whatever system (OS or CPU) your users use. You can even run it in the browser if you want. Ah! The good old times of Java applets.
If you write a compiler to translate another programming language into JVM bytecode, you can even run your programs on the JVM without writing a line of Java. You can write python and compile it for the JVM to your heart’s content. You prefer Ruby? No problem!. You can do that with PHP, too. Rich Hickey, the inventor of Clojure, went a step further: he created a whole programming language which sits on top of the JVM, allowing you to use Java libraries along the way.
Let’s take another example, WebAssembly (or WASM). It’s a bytecode which can be interpreted by a virtual machine running in your browser. If you can compile your source code (written in your favorite language) into WASM, it will run, in theory, in any browser. Farewell, JavaScript!
Some interpreters will compile the bytecode it needs into machine code while executing your program. This is called Just In Time compilation (JIT), as opposed to Ahead of Time compilation (AOT) we’ve seen above. The success of Java was a stepping stone for the success of JIT compilation.
If Everything Is Compiled, Why Using An Interpreter?
Even if, at the end, compilation and interpretation look pretty similar, using one of them can have different consequences.
Advantages and Drawbacks of Ahead Of Time Compilation
Advantages
- The compiler can optimize the machine code depending of the CPU and the OS it targets, making it faster to execute.
- You don’t need any virtual machine running on your computer to run the program.
Drawbacks
- Cross compiling is a difficult problem. In most cases, you’ll still need different executables for every OS you target, and other ones for some different CPU architectures. You might end up with a growing list of programs to download, and your users need to choose the good one, depending on their system.
- Compiling to machine code takes longer than compiling to bytecode. Bigger your application is, slower it will be. That being said, some compilers are incredibly fast nowadays. I look at you, crazy Golang compiler!
Advantages and Drawbacks of Interpretation
Advantages
- Your code is more portable. If the virtual machine can run on many OS and CPUs ISA (which is often the case), your software will run on these OS and CPUs, too.
- Compiling to bytecode is often faster than compiling to machine code. Therefore, it can make the whole development cycle faster, too: run the software, crash everything, fix, repeat.
Drawbacks
- It’s (often) slower to execute.
- Your users will need to install a virtual machine on their computer, and they’ll need to update it. Virtual machines consumes resources, too.
Your Source Code Will Become A Software

By now, I hope you understand that compilation and interpretation are not mutually exclusive, but can be orthogonal (they fit well together). It might save you some headaches when you’ll have customers telling you that your software doesn’t work on their machine, or when it doesn’t work on your new server.
What did we learn with this article?
- Machine code is a set of low level instructions for a specific family of processors (CPU).
- Assembly Language (ASM) is very close to machine code, but it’s more understandable by humans. You need an assembler to translate it to machine code.
- A compiler is simply a translator between one language to another. Many compilers will translate source code into machine code before running the program (AOT, Ahead Of Time compilation).
- Other compilers will translate source code to bytecode, which is similar to an assembly language. This bytecode will then be interpreted by an interpreter (or virtual machine), or even compiled into machine code while running the program (JIT, Just In Time compilation).
Summarized like that, things look already less complex! If you have any question, feel free to contact me by social media (on the about page). If you think I made a mistake somewhere, it would be very helpful to point it out in the comment section below.
Since you’ve made it that far, I’ve a surprise for you: the next poster you’ll put on your walls. You can make a wallpaper out of it, too, for the bedroom of your new born child.
Recommend
-
65
README.md
-
16
Compared to many other programming languages, structs are very powerful in Swift. Hence, they should be used more often. Hint: This post is using Swift 5 Similarities First, let’s...
-
6
The MIR C interpreter and Just-in-Time (JIT) compiler
-
7
Kuroko Kuroko is a dynamic, bytecode-compiled programming language and a dialect of Python. The syntax features indentation-driven blocks, fam...
-
4
What is QBasic/QuickBASIC? QBasic as well as QuickBasic is an easy-to-learn programming language (and therefore ideal for beginners), based on DOS operating system, but also executable o...
-
4
The Big Differences Between Apple Watch Series 8 And Apple Watch SE 2 Explained ...
-
12
Coinbase Vs. Gemini: The Big Differences Between The Crypto Exchanges Explained ...
-
6
The Major Differences Between AirPods Pro 2 Vs AirPods Pro Explained
-
5
Favorite compiler and interpreter resources Last updated Jan 5, 2023 My personal path, a hobbyist, was focused at first on interpreters for Brainfuck, Scheme, lower-case forth, and lower-cas...
-
5
Distinguishing an Interpreter from a Compiler January 26 2023 In
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK