

Decrease complexity by separating Code from Data
source link: https://blog.klipse.tech/databook/2020/10/30/data-book-chap2-part1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
This article is an excerpt from my upcoming book about Data Oriented Programming. The book will be published by Manning, once it is completed (hopefully in 2021).
More excerpts are available on my blog.
Enter your email address below to get notified when the book is published.
Introduction
As we mentioned in Chapter 0, the big insight of Data Oriented Programming (DO) is that we can decrease the complexity of our systems by separating code from data. Indeed, when code is separated from data, our systems are made of two main pieces that can be thought separately: Data entities and Code modules.
This chapter is a deep dive in DO Principle #1:
Principle #1: Separate code from data in a way that the code resides in functions whose behavior does not depend on data that is somehow encapsulated in the function’s context.
We illustrate the separation between code and data in the context of a Library Management system and we unveil the benefits that this separation brings to the system:
-
The system is simple: it is easy to understand
-
The system is flexible: quite often, it requires no design changes to adapt to changing requirements
We show how to:
-
Design a system where code and data are separate
-
Write code that respects the separation between code and data.
This chapter focuses on the design of the code part of a system where code and data are separate. In Chapter 3, we will focus on the design of the data part of the system. As we progress in the book, we will discover other benefits of separating code from data.
The two parts of a DO system
You invite Joe to your office. Joe is a 40-year old developer that used to be a Java developer for many years and moved to Clojure 7 years ago.
When you tell Joe about the Library management system you built (Chapter 1) and the struggle you had to adapt to changing requirements, he is not surprised.
Joe tells you that the systems he and his team have build in Clojure over the last 7 years are less complex and more flexible than the systems he used to build in Java. The main cause of this benefits is that the systems he built were following principles of Data Oriented Programming.
YOU: What makes DO systems less complex and more flexible?
JOE: The first insight of DO is about the relationships between code and data.
YOU: You mean the encapsulation of data in objects?
JOE: Actually, DO is against encapsulation.
YOU: Why is that? I thought encapsulation was a positive programming paradigm.
JOE: Data encapsulation has its merits and drawbacks: Think again at what happened when you implemented Nancy’s LMS (in Chapter 1). According to DO, the main cause of the complexity of systems and their lack of flexibility is because code and data are mixed together (in objects).
YOU: Does it mean that in order to adhere to DO, I need to get rid of OO and learn a Functional programming language?
JOE: No. DO principles are language agnostic: they can be applied both in OO and FP languages.
YOU: Cool! I was afraid that you were going to teach me about monads, algebraic data types and high order functions.
JOE: None of this is required in DO.
YOU: How does the separation between code and data looks like in DO?
JOE: Data is represented by data entities that hold members only. Code is aggregated into modules where all the functions are stateless.
YOU: What do you mean by stateless functions?
JOE: Instead of having the state encapsulated in the object, the data entity is passed as an argument.
YOU: I don’t get that.
JOE: Let me make it visual.
YOU: It’s still not clear
JOE: It will become clearer when I show you how it looks like in the context of your library management system.
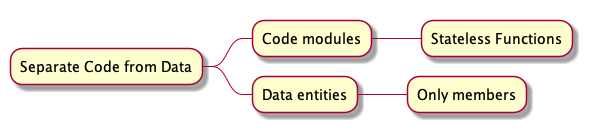
YOU: OK. Shall we start we code or with data?
JOE: Well, it’s Data oriented programming. Let’s start with Data!
Data entities
In DO, we start the design process by discovering the data entities of our system.
JOE: What are the data entities of your system?
YOU: What do you mean by data entities?
JOE: I mean the parts of your system that hold information.
YOU: Well, it’s a library management system, so for sure we have books and members.
JOE: Of course. But there are more: One way to discover the data entities of a system is to look for nouns and noun phrases in the requirements of the system.
You look at Nancy’s requirement napkin and you highlight the nouns and noun phrases that seem to represent data entities of the system:
-
Two kinds of users: library members and librarians
-
Users log in to the system via email and password.
-
Members can borrow books
-
Members and librarians can search books by title or by author
-
Librarians can block and unblock members (e.g. when they are late in returning a book)
-
Librarians can list the books currently lent by a member
-
There could be several copies of a book
Data entities are the parts of your system that hold information
JOE: Excellent. Can you see a natural way to group the entities?
YOU: Not sure, but it seems to me that users, members and librarians form a group while books, authors and book copies form another group.
JOE: Sounds good to me. How would you call each group?
YOU: User management for the first group and Catalog for the second group.
-
The catalog data
-
Data about books
-
Data about authors
-
Data about book items
-
Data about book lendings
-
-
The user management data
-
Data about users
-
Data about members
-
Data about librarians
-
YOU: I am not sure about the relationships between books and authors: should it be association or composition?
JOE: Don’t worry too much about the details for the moment. We will refine our data entities design later (Chapter 3). For now, let’s visualize the two groups in a mindmap.
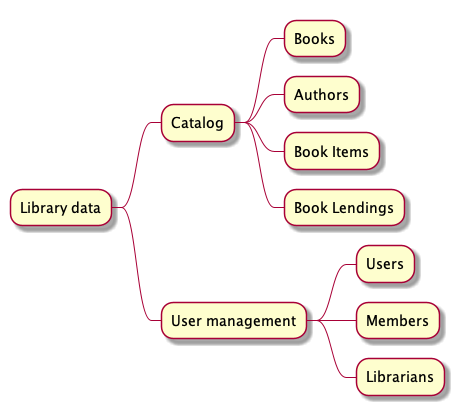
The most precise way to visualize the data entities of a DO system is to draw a data entity diagram with different arrows for association and composition. We will come back to data entity diagram in Chapter 3.
Discover the data entities of your system and group them into high level groups.
We will get deeper into the design and the representation of data entities in Chapter 3. For now, let’s simplify and say that the data of our library system is made of two high level groups: User Management and Catalog.
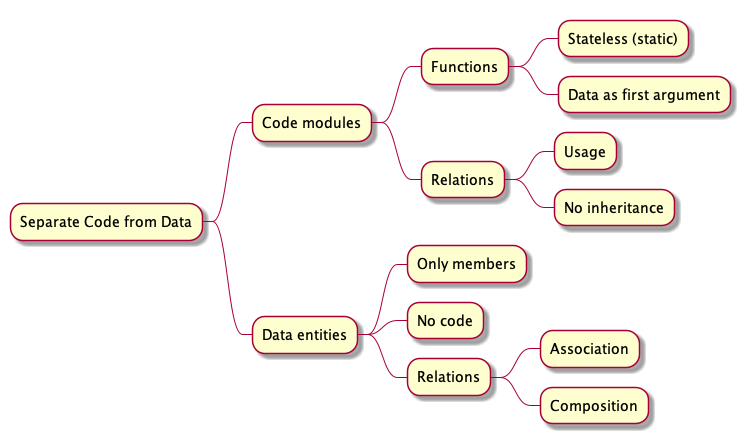
Code modules
The second step of the design process in DO, is to define the code modules of the system.
JOE: Now that you have identified the data entities of your system and group them into high level groups, it’s time to think about the code part of your system.
YOU: What do you mean by code part?
JOE: One way to think about it is to identity the functionalities of your system.
You look again at Nancy’s requirement napkin and this time you highlight the verb phrases that represent functionalities of the system:
-
Two kinds of users: library members and librarians
-
Users log into the system via email and password.
-
Members can borrow books
-
Members and librarians can search books by title or by author
-
Librarians can block and unblock members (e.g. when they are late in returning a book)
-
Librarians can list the books currently lent by a member
-
There could be several copies of a book
In addition to that, it is obvious that members can also return a book. Moreover, there should be a way to detect whether a user is a librarian or not.
Your write down a list of the functionalities of the system.
-
Search a book
-
Add a book item
-
Block a member
-
Unblock a member
-
Login a user into the system
-
List the books currently lent by a member
-
Borrow a book
-
Return a book
-
Check whether a user is a librarian
JOE: Excellent! Now, tell me what functionalities need to be exposed to the outside world?
YOU: What do you mean by exposed to the outside world_?
JOE: Imagine that the library management system were exposing an API over HTTP: what would be the endpoints of the API?
YOU: I see. All the functionalities them beside checking if a user is a librarian should need to be exposed.
JOE: Perfect, now give to each exposed functionality a short name and gather them together in a box called Library
Then you draw the exposed functions of the Library.

The first step in designing the code part of a DO system is to aggregate the exposed functions in a single module.
JOE: Beautiful. You just created your first code module.
YOU: To me it looks like a class: What’s the difference between a module and a class?
JOE: A module is an aggregation of functions. In OO, a module is represented by a class but in other programming languages, it might be a package or a namespace.
YOU: I see.
JOE: The important thing about DO code modules is that they contain only stateless functions.
YOU: You mean like static methods in Java?
JOE: Exactly!
YOU: So how the functions know on what piece of information they operate?
JOE: We pass it as the first argument to the function.
YOU: I don’t understand. Could you give me an example?
Joe takes a look at the list of functions of the Library module.
JOE: Let’s take for example getBookLendings(): in classic OO, what would be its arguments?
YOU: The id of the librarian that wants to list the book lendings and the member id
JOE: In classic OO, getBookLendings would be a method of a Library class that receives two arguments: userId and memberId
YOU: Yeap.
JOE: Now comes the subtle part: in DO, getBookLendings is part of the library module and it receives the
LibraryData as the first argument.
YOU: Could you show me what you mean?
JOE: Sure.
Joe gets closer to your keyboard and start typing.
That’s how a class method looks like in OO:
class Library {
libraryData // state of the object
getBookLendings(userId, memberId) {
// accesses library data via this.libraryData
}
}The method accesses the state of the object — in our case the library data — via this.libraryData. The object’s state is an implicit argument to the object’s methods.
In classic OO, the state of the object is an implicit argument to the methods of the object.
In DO, the signature of getBookLendings would look like this:
class Library {
static getBookLendings(libraryData, userId, memberId) {
}
}The state of the library is stored in libraryData and it is passed to the getBookLendings static method as an explicit argument.
In DO, functions of a code module are stateless: they receive the state they manipulate as an explicit argument, usually the first argument.
A module is an aggregation of functions. In DO, the module functions are stateless.
The same rule applies to the other functions of the library module. All of them are stateless: they receive the library data as first argument.
You apply this rule and you refine the design of the library module by including the details about functions' arguments.

JOE: Perfect. We are now ready to design at a high level our system.
YOU: What’s a high level design in DO?
JOE: The definition of modules and the interaction between them.
YOU: I see. Is there any guideline to help me define the modules?
JOE: Definitely. The high level modules of the system correspond to the high level data entities.
YOU: You mean the data entities that appear in the data mind map?
JOE: Exactly!
You look again at the data mind map and you focus on the high level data entities: Library, Catalog and User management.
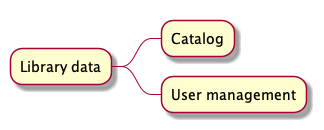
It means that in the system, beside, the Library module, we have two high level modules:
-
Catalogmodule that deals with catalog data -
UserManagementmodule that deals with user management data
Code modules correspond to the data entities of the system.
Then you draw the high level design of library management system, where:
-
Functions of
CatalogreceivecatalogDataas first argument -
Functions of
UserManagementreceiveuserManagementDataas first argument
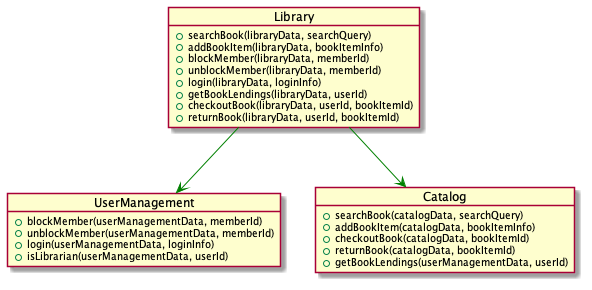
It might not be totally clear for you at the moment, how the data entities get passed between modules. For the moment, you can think of libraryData as a class with two members:
-
catalogthat holds the catalog data -
userManagementthat holds the user management data
The functions of Library share a common pattern:
-
It receives
libraryDataas an argument -
It passes
libraryData.catalogto functions ofCatalog -
It passes
libraryData.userManagementto functions ofUserManagement
Later on, in this chapter, we will see code for some functions of the Library module.
The high level modules of a DO system correspond to the high level data entities.
DO systems are easy to understand
You take a look at the two diagrams that represent the high level design of your system:
-
The data entities in the data mind map
-
The code modules in the module diagram
A bit perplexed, you ask Joe:
YOU: I am not sure that this system is better than a classic OO system, where objects encapsulate data.
JOE: The main benefit of a DO system over a classic OO systems is that it is easier to understand.
YOU: What makes it easier to understand?
JOE: The fact that the system is split clearly in code modules and data entities.
YOU: I don’t get you.
JOE: When you try to understand the data entities of the system, you don’t have to think about the details of the code that manipulates the data entities.
YOU: You mean that when I look at the data mind map of my library management system, I am able to understand it on its own?
JOE: Exactly. And similarly, when you try to understand the code modules of the system, you don’t have to think about the details of the data entities manipulated by the code. There is a clear separation of concerns between the code and the data.
You look again at the data mind map, and you get kind of a Aha moment:
Data lives on its own!
A DO system is easier to understand because the system is split in two parts: data entities and code modules.
Now you look at the module diagram and you feel a bit confused:
-
On one hand, the module diagram looks similar to the class diagrams from classic OO: boxes for classes and arrows for relations between classes.
-
On the other hand, the code module diagram looks much simpler than the class diagrams from classic OO, but you cannot explain why.
You ask Joe for a clarification.
YOU: The module diagram seems much simpler that the class diagrams I am used to in OO. I feel it but I cannot put words on it.
JOE: The reason is that module diagrams have constraints.
YOU: What kind of constraints?
JOE: Constraints on the functions as we saw before: All the functions are static (stateless). But also constraints on the relations between the modules.
YOU: Could you explain that?
JOE: There is a single kind of relation between DO modules: the usage relation. A module uses code from another module. No association, no composition and no inheritance between modules. That’s what make a DO module diagram easy to understand.
YOU: I understand why there is no association and no composition between DO modules: after all, association and composition are data relations. But why no inheritance relation? Does it mean that in DO is against polymorphism?
JOE: That’s a great question. The quick answer is that in DO, we achieve polymorphism with a different mechanism than class inheritance. We will talk about it later (in Chapter 5).
YOU: Now, you triggered my curiosity: I was quite sure that inheritance was the only way to achieve polymorphism.
You look again at the module diagram and now you not only feel that this diagram is simpler than classic OO class diagrams, you understand why it is simpler: All the functions are static and all the relation between modules are of type usage.
Data entities
Members (no code)
Association and Composition
Code modules
Code (no members)
Usage (no inheritance)
Each part of a DO system is easy to understand, because it has constraints.
DO systems are flexible
YOU: I get that the sharp separation between code and data makes DO systems are easier to understand than classic OO systems. But what about adapting to changes in requirements?
JOE: Another benefit of DO systems is that it is easy to adapt them to changing requirements.
YOU: I remember that when Nancy asked me to add Super Members and VIP Members to the system, it was hard to adapt my OO system: I had to introduce a few base classes and the class hierarchy became really complex.
JOE: I know exactly what you are talking about. I experienced the same kind of struggle when I was a OO developer. Tell me what were the changes in the requirements for Super Members and VIP Members and I am quite sure that you will see by yourself that it is easy to adapt your DO system.
-
Super Members are members that are allowed to list the book lendings of other members
-
VIP Members are members that are allowed to add book items to the library
You open your IDE and you start to code the getBookLendings function of the Library module, first without addressing the requirements for Super Members. You remember what Joe told you about module functions in DO:
-
Functions are stateless
-
Functions receive the data they manipulate as first argument
In terms of functionalities, getBookLendings have two parts:
-
Check that the user is a librarian
-
Retrieve the book lendings from the catalog
Basically, the code of getBookLendings have two parts:
-
Call
isLibrarianfunction from theUserManagementmodule and pass it theUserManagementData -
Call
getBookLendingsfunction from theCatalogmodule and pass it theCatalogData
The code for Library.getBookLendings is shown in this listing.
class Library {
static getBookLendings(libraryData, userId, memberId) {
if(UserManagement.isLibrarian(libraryData.userManagement, userId)) {
return Catalog.getBookLendings(libraryData.catalog, memberId);
} else {
throw "Not allowed to get book lendings"; // (1)
}
}
}
class UserManagement {
static isLibrarian(userManagementData, userId) {
// will be implemented later (2)
}
}
class Catalog {
static getBookLendings(catalogData, memberId) {
// will be implemented later (3)
}
}-
There are other ways to manage errors
-
In Chapter 3, we will see how to manage permissions with generic data collections
-
In Chapter 3, we will see how to query data with generic data collections
It’s your first piece of DO code: passing around all those data objects libraryData, libraryData.userManagement and libraryData.catalog feels a bit awkward. But you made it.
Joe looks at your code and seems satisfied.
JOE: How would you adapt your code to adapt to Super Members?
YOU: I would add a function isSuperMember to the UserManagement module and call it from Library.getBookLendings
JOE: Exactly! It’s as simple as that.
You type this piece of code on your laptop.
class Library {
static getBookLendings(libraryData, userId, memberId) {
if(Usermanagement.isLibrarian(libraryData.userManagement, userId) ||
Usermanagement.isSuperMember(libraryData.userManagement, userId)) {
return Catalog.getBookLendings(libraryData.catalog, memberId);
} else {
throw "Not allowed to get book lendings"; // (1)
}
}
}
class UserManagement {
static isLibrarian(userManagementData, userId) {
// will be implemented later (2)
}
static isSuperMember(userManagementData, userId) {
// will be implemented later (2)
}
}
class Catalog {
static getBookLendings(catalogData, memberId) {
// will be implemented later (3)
}
}-
There are other ways to manage errors
-
In Chapter 3, we will see how to manage permissions with generic data collections
-
In Chapter 3, we will see how to query data with generic data collections
Now, the awkward feeling caused by passing around all those data objects is dominated by a feeling of relief: Adapting to this change in requirement takes only a few lines of code and require no changes in the system design.
Once again, Joe seems satisfied.
DO systems are flexible. Quite often, they adapt to changing requirements without changing the system design.
You prepare yourself a cup of coffee, and you start coding the addBookItem code.
You look at the signature of Library.addBookItem and it is not clear to you what is the meaning of the third argument bookItemInfo. You ask Joe for a clarification.
Library.addBookItemclass Library {
static addBookItem(libraryData, userId, bookItemInfo) {
}
}YOU: What is booItemInfo?
JOE: Let’s call it the book item information and imagine we have a way to represent this information in a data entity named bookItemInfo.
YOU: You mean an object?
JOE: For now, it’s ok to think about bookItemInfo as on object. Later on (in Chapter 3), I will
show you how to represent data entities as generic data collections.
Beside this subtlety about how the book item info is represented by bookItemInfo, the code for Library.addBookItem is quite similar to the code you wrote for Library.getBookLendings. Once again, you are amazed by the fact that adding support for VIP Members requires no design change.
class Library {
static addBookItem(libraryData, userId, bookItemData) {
if(UserManagement.isLibrarian(libraryData.userManagement, userId) ||
UserManagement.isVIPMember(libraryData.userManagement, userId)) {
return Catalog.addBookItem(libraryData.catalog, bookItemData);
} else {
throw "Not allowed to add a book item"; // (1)
}
}
}
class UserManagement {
static isLibrarian(userManagementData, userId) {
// will be implemented later (2)
}
static isVIPMember(userManagementData, userId) {
// will be implemented later (2)
}
}
class Catalog {
static addBookItem(catalogData, memberId) {
// will be implemented later (3)
}
}-
There are other ways to manage errors
-
In Chapter 3, we will see how to manage permissions with generic data collections
-
In Chapter 4, we will see how to manage state of the system with immutable data
YOU: It required a big mindset shift for me to learn how to separate code from data.
JOE: What was the most challenging part for your mind?
YOU: The fact that data is not encapsulated in objects.
JOE: It was the same for me when I switched from OO to DO.
YOU: Will there be other mindset shifts in my journey into DO?
JOE: There will be two more mindset shifts but I think that they will be less challenging than separating code from data.
YOU: What will it be about?
JOE: Representing data entities as generic collections (Chapter 3) and constraining ourselves to immutable data objects (Chapter 4).
Wrapping up
In this chapter we illustrated DO Principle #1 about the separation between code from data:
Principle #1: Separate code from data in a way that the code resides in functions whose behavior does not depend on data that is somehow encapsulated in the function’s context.
It required quite a big mindset shift to learn that in DO:
-
Code is separated from data
-
Code is aggregated in modules
-
Data is aggregated in data entities
-
Code is made of stateless functions
-
Functions receive data as first argument
We illustrated how to apply this principle in a OO language.
A consequence of this separation is that:
-
We have the freedom to design code and data in isolation
-
Module diagrams are simple: it’s only about usage (no inheritance)
-
Data entities diagram are simple: it’s only about association and composition
The details of Principle #1 are summarized in this mindmap.
Overall, the DO systems are simpler (easier to understand) than classic OO systems and more flexible (easier to adapt to changing requirements).
Oh my love
What follows is an adaptation of Oh My Love by John Lennon and Yoko Ono.
Oh my love for the first time in my life
My system is quite simple
Oh my lover for the first time in my life
My system can adapt
I see the code, oh I see the data
Everything is clear in my heart
I see the code, oh I see the data
Everything is clear in my system
Oh my love for the first time in my life
My entities are quite simple
Oh my lover for the first time in my life
My modules can adapt
I feel the arguments, oh I feel the dreams
Everything is stateless in my code
I feel life, oh I feel love
Everything is clear in my system
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK