

三千字轻松入门 TensorFlow 2
source link: https://xie.infoq.cn/article/e86c844bdecfa57432d7bc441
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

通过使用深度学习实现分类问题的动手演练,如何绘制问题以及如何改善其结果,来了解TensorFlow的最新版本。
但是等等...什么是Tensorflow?
Tensorflow是Google的深度学习框架,于2019年发布了第二个版本。它是世界上最著名的深度学习框架之一,被行业专家和研究人员广泛使用。
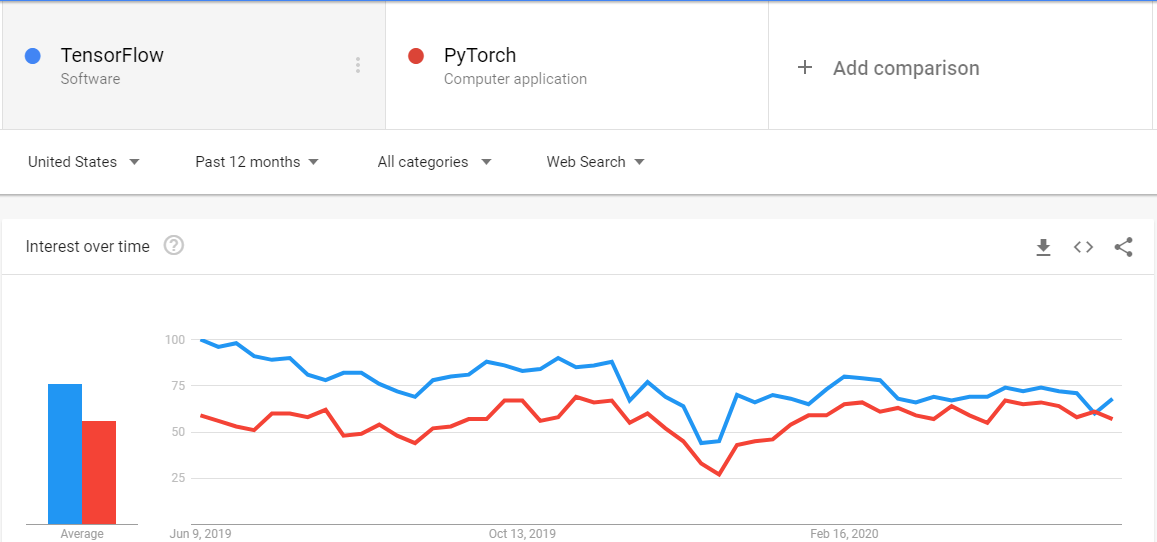
Tensorflow v1难以使用和理解,因为它不像Pythonic,但随着Keras发布的v2现在与Tensorflow.keras完全同步,它易于使用,易学且易于理解。
请记住,这不是有关深度学习的文章,所以我希望您了解深度学习的术语及其背后的基本思想。
我们将使用非常著名的数据集IRIS数据集探索深度学习的世界。
让我们直接进入代码以了解发生了什么。
导入和理解数据集

现在,这个 iris 是一本字典。我们可以使用keys()

因此,我们的数据在 数据 键中, 标签 在 标签 键中,依此类推。如果要查看此数据集的详细信息,可以使用 iris ['DESCR'] 。
现在,我们必须导入其他重要的库,这将有助于我们创建神经网络。

在这里,我们从 tensorflow中 导入了2个主要内容 ,即 Dense 和 Sequential 。我们从 tensorflow.keras.layers 导入的 密集层是紧密连接的一种层。密集连接的层意味着先前层的所有节点都连接到当前层的所有节点。
Sequential 是Keras的API,通常称为Sequential API,我们将使用它来构建神经网络。
为了更好地理解数据,我们可以将其转换为数据帧。我们开始做吧。

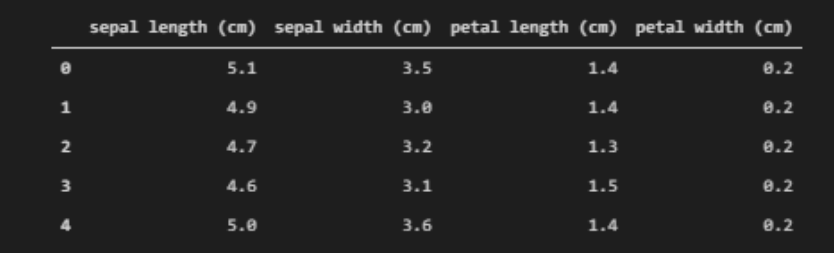
请注意,这里我们设置了 column = iris.feature_names ,其中 feature_names 是具有所有4个特征名称的键。
对于标签,


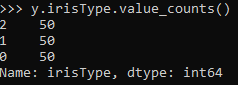
在这里,我们可以看到我们有3个类,每个类的标签分别为0、1和2。要查看标签名称,我们可以使用


这些是我们必须预测的类的名称。
机器学习的数据预处理
现在,机器学习的第一步是数据预处理。数据预处理的主要步骤是
-
填充缺失值
-
将数据分为训练和验证集
-
数据标准化
-
将分类数据转换为一键向量
缺失值
要检查是否缺少任何值,可以使用 pandas.DataFrame.info() 方法进行检查。

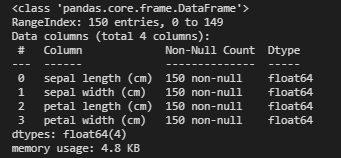
这里我们可以看到我们没有丢失值(幸运的是),所有特征都在 float64中 。
分为训练集和测试集
要将数据分为训练集和测试集,我们可以使用 先前导入的 sklearn.model_selection中 的 train_test_split 。

其中 test_size 是告诉我们我们希望测试数据占整个数据的10%的参数。
数据标准化
通常,当数据中存在大量方差时,我们将其标准化。要检查方差,我们可以使用 panadas.DataFrame中的var() 函数 检查所有列的var。

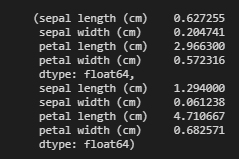
在这里,我们可以看到 X_train 和 X_test的 方差都非常低,因此无需对数据进行标准化。
分类数据转换为OneHot向量
我们知道我们的输出数据是已经使用 iris.target_names 检查的3个类 之一 ,好处是当我们加载目标时,它们已经是0、1、2格式,其中0 = 1stclass ,1 = 2nd class , 等等。
这种表示形式的问题在于我们的模型可能会给较高的数字更高的优先级,这可能导致结果出现偏差。因此,为了解决这个问题,我们将使用一站式表示法。您可以 在此处 了解更多关于一键矢量的 信息 。我们可以使用 Keras 内置的 to_categorical 或使用 sklearn中 的 OneHotEncoder 。我们将使用 to_categorical 。

我们将仅检查前5行,以检查其是否正确转换。

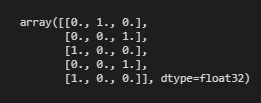
是的,我们已经将其转换为OheHot表示形式。
最后一件事
我们可以做的最后一件事是将数据转换回 numpy 数组,以便我们可以使用一些额外的特征功能,这些特征将在稍后的模型中为我们提供帮助。为此,我们可以使用

让我们看看第一个训练示例的结果。


在第一个训练示例中,我们可以看到4个要素的值,其形状为(4,)
当我们对它们使用 to_categorical时 ,它们的目标标签已经是数组格式 。
深度学习模型
现在终于可以开始创建模型并对其进行训练了。我们将从简单的模型开始,然后进入复杂的模型结构,其中将介绍Keras中的不同技巧和技术。
让我们编写基本模型

首先,我们必须创建一个顺序对象。现在,要创建模型,我们要做的就是根据我们的选择添加不同类型的图层。我们将制作一个10个密集层模型,以便我们可以观察过度拟合,并在以后通过不同的正则化技术将其减少。

注意,在第一层中,我们使用了一个额外的 input_shape 参数 。 此参数指定第一层的尺寸。在这种情况下,我们不关心训练示例的数量。相反,我们只关心功能的数量。因此,我们传递了任何训练示例的形状,在我们的例子中,它是 (4,) 在 input_shape 内部 。
注意,我们在输出层中使用了 softmax 激活函数,因为它是一个多类分类问题。如果是二进制分类问题,我们将使用 Sigmoid 激活函数。
我们可以传入我们想要的任何激活函数,例如 S型 , 线性 或 tanh ,但是通过实验证明 relu 在这类模型中表现最佳。
现在,当我们定义了模型的形状时,下一步就是指定它的 损失 , 优化器 和 指标 。我们在Keras中使用 compile 方法指定这些 。

在这里,我们可以使用任何 优化程序, 例如随机梯度下降,RMSProp等,但是我们将使用Adam。
我们在 这里使用 categorical_crossentropy 是因为我们有一个多类分类问题,如果我们有一个二元类分类问题,我们会改用 binary_crossentropy 。
指标对于评估一个人的模型很重要。我们可以基于不同的指标来评估模型。对于分类问题,最重要的指标是准确性,它表明我们的预测有多准确。
我们模型的最后一步是将其拟合训练数据和训练标签。让我们编写代码。

fit 返回一个回调,该回调具有我们训练的所有历史记录,我们可以用来执行不同的有用任务,例如绘图等。
History回调具有一个名为 history 的属性 ,我们可以将其作为 history.histor y进行访问 ,它是具有所有损失和指标历史记录的字典,即,在我们的示例中,它具有 loss , acc , val_loss 和 val_acc 的历史记录 并且我们可以访问 history.history.loss 或 history.history ['val_acc'] 等中的每一个 。
我们指定的epoch数为800,批量大小为40,验证分为0.1,这意味着我们现在有10%的验证数据可用于分析训练。使用800个epoch将过度拟合数据,这意味着它将在训练数据上表现出色,但在测试数据上表现不佳。
在训练模型的同时,我们可以在训练和验证集上看到我们的损失和准确性。

在这里,我们可以看到我们的训练精度为100%,验证精度为67%,对于这样的模型而言,这是相当不错的。让我们来绘制它。

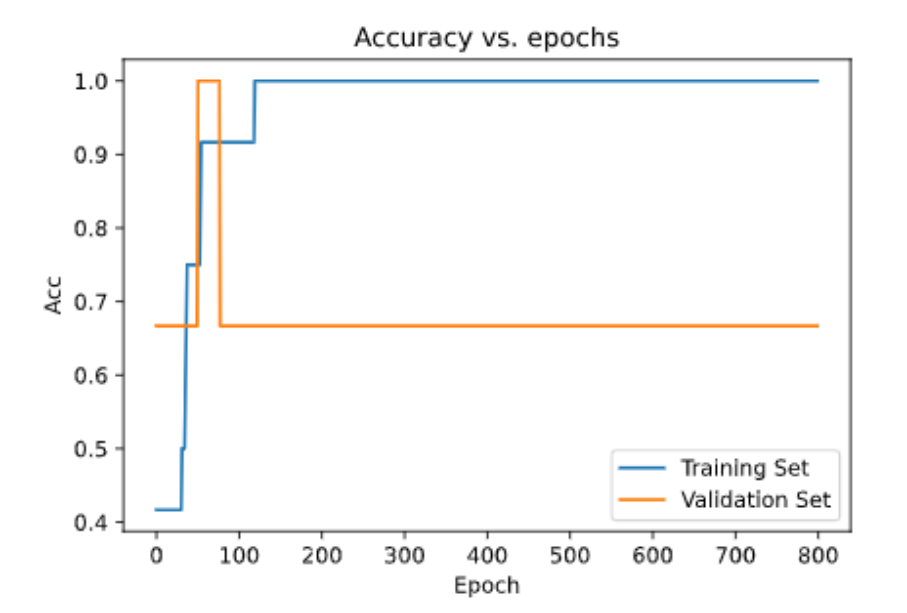
我们可以清楚地看到,训练集的准确性比验证集的准确性高得多。
同样,我们可以将损失绘制为

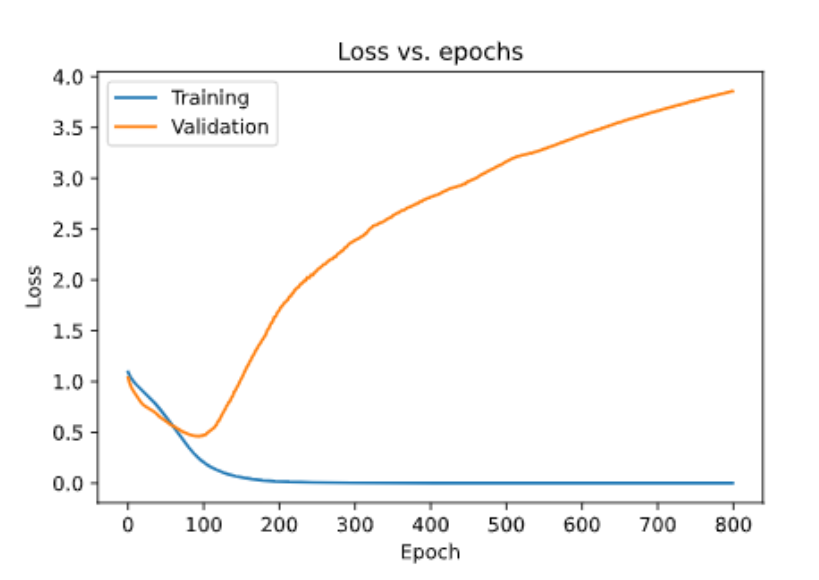
在这里,我们可以清楚地看到我们的验证损失比我们的训练损失高得多,这是因为我们过度拟合了数据。
要检查模型性能,可以使用 model.evaluate 检查模型性能。我们需要在评估方法中传递数据和标签。


在这里,我们可以看到我们的模型给出了88%的准确度,这对于过度拟合的模型来说相当不错。
正则化
让我们通过在模型中添加正则化使其更好。正则化将减少我们模型的过度拟合并改善我们的模型。
我们将在模型中添加L2正则化。 在此处 了解有关L2正则化的更多信息 。要在我们的模型中添加L2正则化,我们必须指定要在其中添加正则化的层,并提供另一个参数 kernel_regularizer ,并传递 tf.keras.regularizers.l2() 。
我们还将在模型中实现一些改进,这将有助于我们更好地减少过度拟合,从而获得更好的性能模型。要了解更多有关理论和动机背后辍学,请参阅 此 文章。
让我们重新制作模型。

如果您密切注意,我们的所有层和参数都相同,除了我们在每个密集层中添加了2个Dropout和正则化。
我们将使所有其他内容(loss,优化器,epoch等)保持不变。

现在让我们评估模型。


你猜怎么着?通过添加正则化和Dropout,我们将准确性从88%提高到94%。如果我们向其添加批处理规范化,它将进一步改善。
让我们来绘制它。
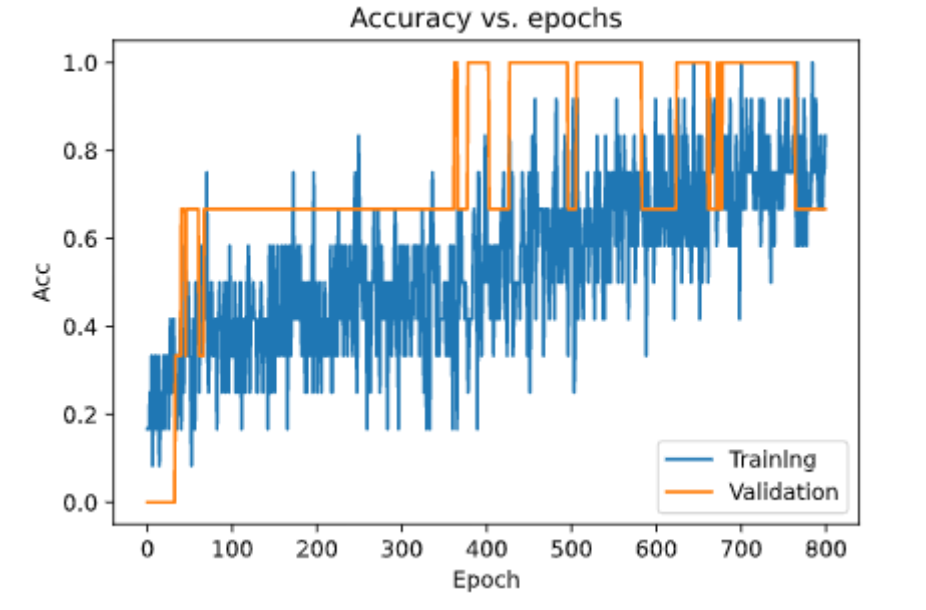

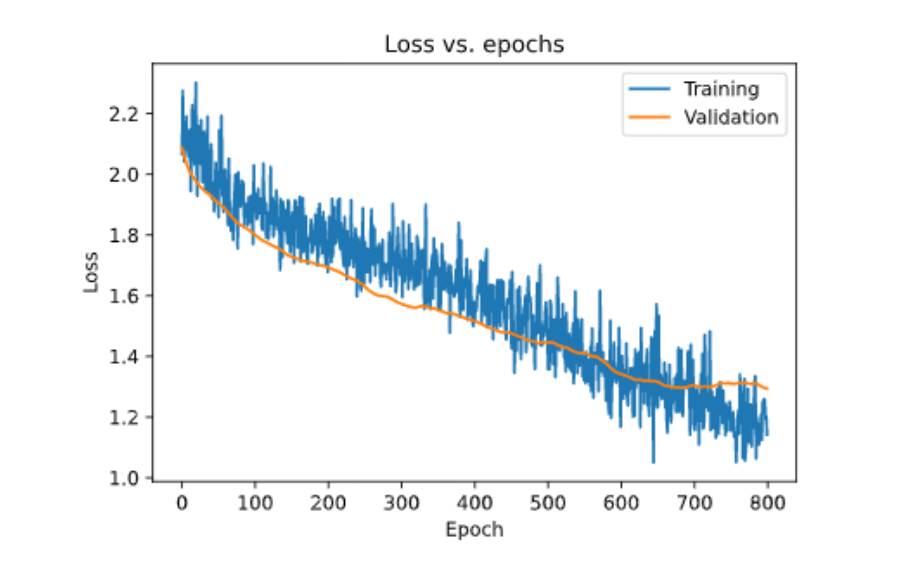
见解
在这里,我们可以看到我们已经成功地从过度模型中去除了过度拟合,并将模型提高了近6%,对于如此小的数据集而言,这是一个很好的改进。
如果你喜欢本文的话,欢迎点赞转发!谢谢。
看完别走还有惊喜!
我精心整理了计算机/Python/机器学习/深度学习相关的2TB视频课与书籍,价值1W元。关注微信公众号“计算机与AI”,点击下方菜单即可获取网盘链接。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK