

携程风控数据仓库实践
source link: https://tech.ctrip.com/articles/a_bigdata/11108/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、引言
携程风控包括了酒店,机票,度假,火车票等所有携程产线的支付风控,同时也包括每个产线的业务风控。自2018年开始,携程风控归属于携程金融,进而也包括也携程金融的信用风控。总而言之,在携程,只要与钱相关的交易都离不开风控。
携程的业务线多,各业务的差异非常大。携程也是以BU制为单位的,各BU都建有自己的小数仓,使得各业务线的数据变化多样。为了能够满足风控的需要, 如何搭建一个可以同时适用于反欺诈风控,业务风控和金融信用风控的数据仓库 ,是风控近两年需要解决的最重要的问题。
风控是一个横向部门,依赖于各个BU的数据,而OTA行业的特点又决定了数据很难统一。风控数据仓库需要解决的难点问题如下:
1)标准化各业务线的数据,为风控规则策略人员,数据分析人员,模型人员提供稳定准确可靠的中间层数据。
2)保证数据完备性,同时与各BU业务保证同步,为各个使用数据的团队做好数据质量监控。
3)提供高效稳定宜用的工具,使得各个用数团队可以快速高效操作海量订单,设备,用户行为各种数据。
4)在整个数仓基础上支持数据的回放以及各类特征的回溯。为规则策略人员以及模型人员提供基础保证。
本文将介绍携程风控是如何解决以上重要问题的实践和思考,与大家一起探讨互联风控数据仓库的发展,希望对大家有所帮助。
二、实践篇
传统数仓建设主要目的是为了提供业务决策分析使用,我们称之为BI。但风控数仓建设的主要目的是为了实现风险识别,包括支付欺诈识别,业务风险识别,个人信用风控识别。在数仓建设中包括 ODS层建设,DW层建设,DM层建设。数据治理,质量监控。
整体上,风控的数仓包括了下图中的内容。从业务系统的源数据,到数仓,最后到应用。 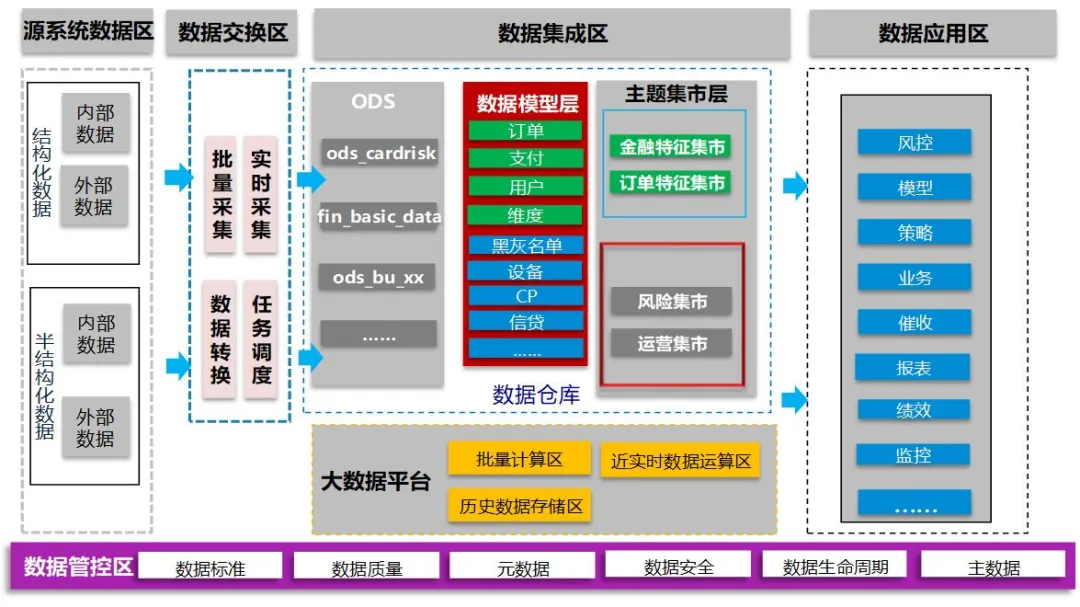
图2-1 风控数仓的物理结构
风控数仓的分层结构如下图,以简单直接,易于维护,同时方便回溯为目标。由于互联网行业的业务迭代速度非常快,这就要求数仓也需要适应这种快速迭代的要求,所以我们以简单化层次,并最大化复用为标准。设计如下的层次结构:
图2-2 风控数仓的分层
2.1 如何搭建ODS层
由于各业务线已经全面接入风控系统,数据量非常大,所以风控的ODS数据并不完全是从DB中抽取,只有少量人工审核相关的数据是通过ETL进入数据仓库的,大量的数据是通过流的方式“流进”数仓的。而风控依赖各个BU业务的数据则是在业务ODS同步完成之后,风控基于业务的ODS进行更进一步的加工处理为风控标准数据。
在ODS层,除了同步风控所有的数据以外,还做了标准的脱敏操作。不管是金融数据,还是订单数据,或者是支付数据,都涉及了大量的用户敏感信息。所以在数据进入数仓之前,我们使用了公司统一的神盾服务进行脱敏处理。
携程风控目前所有业务接入了800+个接入点的数据,相当于传DB的800+张不同的业务数据表。经过统一的ETL工具,每天零点到1:30这一个半小时完成ODS层的同步处理建设。 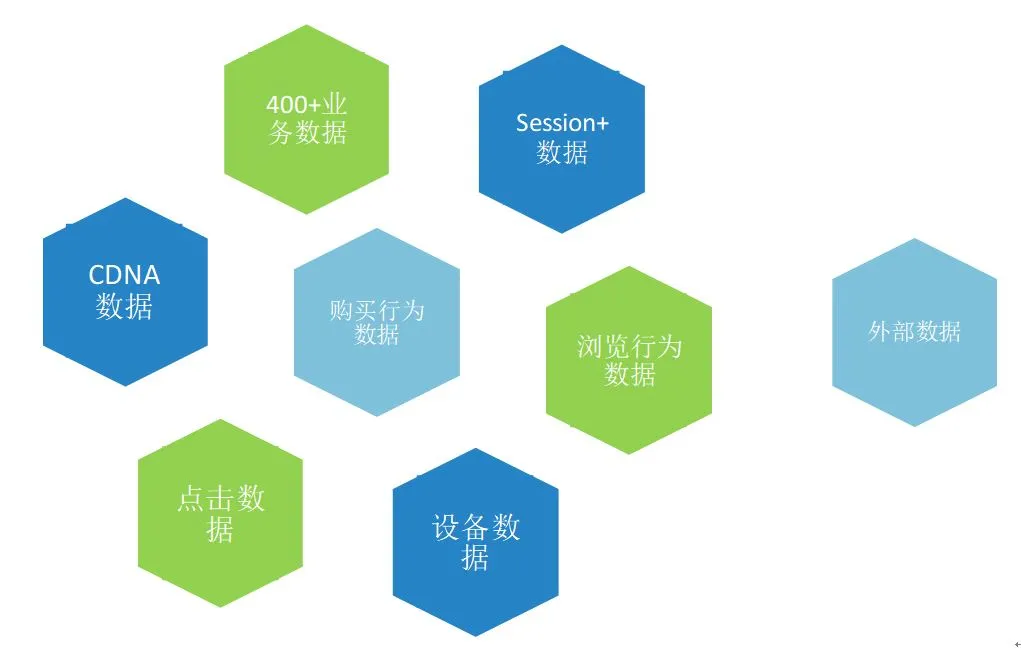
图2-3 风控数仓的丰富来源
2.2 如何标准化各业务线,建设DW层
携程的数据产线非常多,几乎涵盖了整个OTA行业所有的业务。
目前风控数仓以主题划分:
通过各数据域和主题,让千变万化的业务线数据变得标准易用,同时易于维护。
2.3 如何建设DM层
风控DM层的建设有一个很重要的原则是,要能够回溯所有的DM层特征数据。这跟传统数仓有很大区别,传统数仓只要求口径统一,指标逻辑明确即可。但是风控的任何一笔交易的决策都是由规则,策略,模型决定的。在新建,修改,迭代,下线规则策略的时候,需要历史数据回放验证变更的有效性,为变更提供数据基础。模型的增加,迭代同时需要DM层特征的回溯验证模型的变更有对识别目标真实有效的变更。
DM层的建设是基于DW层的。DW层屏蔽了业务的变化,通过数据模型的设计让DW层变得非常通用。为了支持回溯,每一个DM层的数据产出都对应了一个DWS明细数据。简单来说,DWS表就是根据产出需要,把需要的DW层的表的列汇综起来,成为一张根据产出需要的“小宽表”。数据的回溯,检验,监控,以及质量保证都是基于这张”小宽表”进行的。
图2-6 风控DM层分类
三、工具篇
3.1 PSI
在风控的数仓中,DM层包括了大量的特征。对于各类特征的监控,离不开PSI的计算。以往,PSI的计算是针对一个特征进行计算。但是不管风控规则还是各种不同的模型,一般不会只使用一个特征,尤其模型中,往往一个模型会使用上百个特征,甚至几百个特征。这就会导致大量特征的PSI计算,效率很低,执行时间很长。而且配置起来非常麻烦,往往需要使用python等模型开发先把每个特征的分bin预先计算好,每个bin的边界值预算算出来,异常值预先定义出来。这些工作需要针对每一个特征进行,在一个新的模型中,需要上百个特征的时候,这些工作十分麻烦低效。
为此,风控数仓开发了个基于hive/spark的psi计算工具。实现了各类特征的常用psi计算方式,一次同时可以计算N个特征,配置起来极其简单,计算效率也有一个质的提升,最大程度地简化特征psi的计算复杂度。
常用的PSI计算需要实现等频、等距、枚举、自定义等分bin/分箱方式。如图:
图3-1 psi计算方式
其中等距,枚举,和自定义分bin方式的psi计算,在MR中是比较容易实现的,而且计算效率也非常好。等距只需要计算出最大值和最小值,然后根据配置分bin数据可以计算出每一个bin的分界。定义分bin和枚举同样道理,在配置中就可以得到分界。但是等频是需要先排序的,排完序后才可以得到每个bin分界。所以,等频的PSI计算采用了TeraSort的思想。
简单描述一下TeraSort的思想:
一组无序的数
对无序数据均匀采样并排序,反应原始数据分布;
将无序数据按采样数据分割,得到分割点,并使用随机数解决数据倾斜;
利用MR的partition,将各采样区间内的数据放到对应的partition中,这样就可以利用MR中的排序能力,把不同的partition分配到不同的reducer中。由于partition之间是有序的,partition内部利用MR也是有序的,所以整体上就是有序的。这种方式使得全局单点排序变成了分布式并行排序,极大提高了排序的速度。
在每个reducer中确定每个bin的边界。
批量PSI等频计算方式的核心思想是MR+TeraSort。
图3-2 psi计算流程
结果
- 组件现已应用在风控数仓PSI 计算中
- 运行简单,最少只需2个参数、1个配置文件即可运行
- 配置方式多样,提供全局模式、one-stage模式、排除模式、结果文件配置等配置方式
- 计算速度快
表3-3 psi计算性能
3.2 OrJoin
在风控,有很多场景需要使用到图,如:干系人,欺诈团伙识别。金融场景中有一个原则就是物以类聚,人以群分,判断一个人的信用风险,对这个人社交关系认识也会使用到图。OrJoin是携程风控用来对图关系计算的一个基础工具。
算法描述:给定N个Key(注册手机,联系人手机,绑定手机,设备id,邮箱,支付id…)
任意两条记录,如果有其中任意一个key相同,则这两条记录属于同一个Set。
任意两个Set中的记录,有任意一个Key相同,则这两个Set合并为一个Set。
以上步骤直到没有两个Set可以合并,即收敛。
图3-4 OrJoin图
OrJoin的原理是基于最大图联通分量的分布式图[1]的收敛计算,由于风控的分析人员是以SQL为基础的,所以我们在OrJoin和回溯工具【后面介绍】中都实现SQL的接口,让大家以SQL的方式来使用。
Select* from A ORJOIN B on A.uid=B.uid OR A.clientIP=B.clientIP
其中,
- a node in graph = a record in table
- a edge in graph = 2 records with same column value
图3-5 OrJoin结果图
OrJoin工具的作用就是用来生成最大图联通分量的一个唯一子图ID,这样分析人员可以根据这个ID进行相关的统计,因为这个ID的生成是最复杂而且计算量是非常大的。正常使用Hive SQL是没有办法完成的。
3.3 回溯工具
风控需要回溯的地方非常多,所以离线数据回溯/回放在风控是一个必须要解决的问题。在设计数据仓库之初我们就考虑到这一个问题,所以在ODS层,DW层以及DWS和DM的数据设计都遵循了一定的规范,这样配合离线数库的回溯工具,可以让风控的数据使用人员可以轻松做到回溯。
风控的场景用到回溯的方式目前分为以下四大类:Streaming(流式)/Normal(通用)/Fast(快速)/时序Join。
回溯的主要目的是让时间回到历史的某个时点的时候,在当时看,所有的特征应该是多少。
表3-6 回溯工具介绍
我们以Streaming方式举个例子:
图3-7 Streaming自研回溯方式
如果使用HiveSQL实现,那每一个特征需要使用这种自关联的方式进行join,由于数据量很大的时候,这种执行慢到不可以接受。
图3-8 Streaming的hql实现方式
这是一种自定义的SQL,SQL的语法与HiveSQL非常相似,这样使用人学习成本非常低。
原理:
回溯工具在风控内部又叫离线数据回放引擎,在回放引擎中,模拟了生产环境中的一个“流”,这个流是以严格时序的,所谓严格时序,是指不考虑分布式环境,严格以时间字段先后顺序为准。这个流窗口保持了所有的统计数据的最大窗口。每个窗口上可以挂N多个聚合类统计Agg(也就是业务所需要的特征)。
图3-9 Streaming回溯的时间窗口
图3-10 Streaming回溯滑动窗口
在数据量非常大的时候(风控中的场景往往数据量很大),这种滑动窗口依然会存在执行慢,甚至OOM。于是我们做了以下优化:
图3-11 Streaming回溯的优化
下图是离线回溯工具的MR执行过程:
图3-12 Streaming回溯的MR流程
目前在风控内部测试下来:
数据集:2,2825,9934,聚合变量:624 Count(distinct),相当于624个特征计算;
SQL执行时间:180minutes à 40minutes。
3.4 丰富的UDF、UDTF、UDAF
为了满足模型,规则,策略和数据分析人员的需要,风控内部有大量的UDF、UDTF、UDAF。这些自定义的函数让很多计算变得很简单,易用。
图4-1 自研UDF
3.5 MaxX变量服务
风控规则,模型,策略以及分析人员每天大量使用离线数据进行分析。在模型,规则上线的时候需要使用到大量的离线清洗出来的数据。这些离线数据需要跟风控引擎实时计算结合起来,做到批流统一,就需要一条通道把这些离线数据能够推送到风控引擎的缓存中。 
图5-1 MaxX总流程
MaxX最重要的功能就是把离线数据推送到线上,同时要保证数据推送是万无一失的。因为离线的推送是分布式的,推送速度很快速,但不能影响线上查询,所以变速器的设计很重要。 
公式5-2 MaxX限流
目前MaxX变量已经推送3000+个变量。
四、未来规划
风控数仓建设的终极目标是让数据产生价值,让数据更容易产生价值,让数据更高效地产生价值。对于DW层和DM层的持续建设是我们的重要工作。不久的将来,以下工作也会被陆续实现:
1)Tag管理;
2)组件化模型执行,数据分析;
3)可视化数据分析;
五、总结
风控数仓是在传统数仓的建设基础上,考虑了更多的风控和模型应用场景,即数据回溯。在数仓建设过程中,也更注重于技术上的建设。风控拥有关庞大的模型团队,数据分析团队,规则策略团队以及报表团队,这就对数仓的产出有了更高的要求。除了正常的业务报表以外,还要有一个稳定可靠的DW层数据,满足这些用数人员的千变万化的需求。同时,针对风控模型和规则策略的特殊需要,有一个比较完整的DM层,还要支持数据回放和回溯。
在风控数仓的Roadmap中,Tag管理和可视化数据分析会将数据提高到一个新的高度,也让数据仓真正达到我们的目标:让数据产生价值,让数据更容易产生价值,让数据更高效产生价值。
参考文献
[1]【https://dl.acm.org/doi/pdf/10.1145/2670979.2670997】Kiveris R, Lattanzi S, Mirrokni V, et al. Connected components inmapreduce and beyond[C]//Proceedings of the ACM Symposium on Cloud Computing.ACM, 2014: 1-13.
【作者简介】K.Y.Xing,携程高级开发经理,对高并发数据处理,流式数据处理,风控大数据处理,用户行为分析有浓厚兴趣。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK