

你听过 CatBoost 吗?本文教你如何使用 CatBoost 进行快速梯度提升
source link: https://xie.infoq.cn/article/1f34fe82de4bb48a232aaa353
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在本文中,我们将仔细研究一个名为CatBoost的梯度增强库。
在梯度提升中,预测是由一群弱学习者做出的。与为每个样本创建决策树的随机森林不同,在梯度增强中,树是一个接一个地创建的。模型中的先前树不会更改。前一棵树的结果用于改进下一棵树。在本文中,我们将仔细研究一个名为CatBoost的梯度增强库。
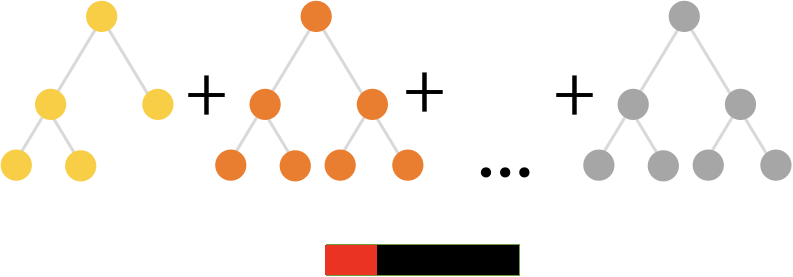
CatBoost 是 Yandex 开发的深度方向梯度增强库 。它使用遗忘的决策树来生成平衡树。相同的功能用于对树的每个级别进行左右拆分。
(CatBoost官方链接: https://github.com/catboost )
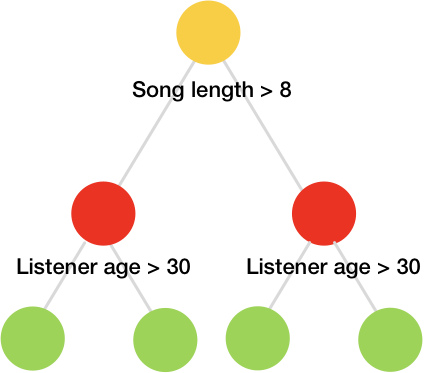
与经典树相比,遗忘树在CPU上实现效率更高,并且易于安装。
处理分类特征
在机器学习中处理分类的常见方法是单热编码和标签编码。CatBoost允许您使用分类功能,而无需对其进行预处理。
使用CatBoost时,我们不应该使用一键编码,因为这会影响训练速度以及预测质量。相反,我们只需要使用
cat_features
参数指定分类特征即可 。
使用CatBoost的优点
以下是考虑使用CatBoost的一些原因:
-
CatBoost允许在多个GPU上训练数据。
-
使用默认参数可以提供很好的结果,从而减少了参数调整所需的时间。
-
由于减少了过度拟合,因此提高了精度。
-
使用CatBoost的模型应用程序进行快速预测。
-
经过训练的CatBoost模型可以导出到Core ML进行设备上推理(iOS)。
-
可以在内部处理缺失值。
-
可用于回归和分类问题。
训练参数
让我们看一下CatBoost中的常用参数:
-
loss_function别名为objective-用于训练的指标。这些是回归指标,例如用于回归的均方根误差和用于分类的对数损失。 -
eval_metric—用于检测过度拟合的度量。 -
iterations-待建的树的最大数量,默认为1000。别名是num_boost_round,n_estimators和num_trees。 -
learning_rate别名eta-学习速率,确定模型将学习多快或多慢。默认值通常为0.03。 -
random_seed别名random_state—用于训练的随机种子。 -
l2_leaf_reg别名reg_lambda—成本函数的L2正则化项的系数。默认值为3.0。 -
bootstrap_type—确定对象权重的采样方法,例如贝叶斯,贝努利,MVS和泊松。 -
depth—树的深度。 -
grow_policy—确定如何应用贪婪搜索算法。它可以是SymmetricTree,Depthwise或Lossguide。SymmetricTree是默认值。在中SymmetricTree,逐级构建树,直到达到深度为止。在每个步骤中,以相同条件分割前一棵树的叶子。当Depthwise被选择,一棵树是内置一步步骤,直到指定的深度实现。在每个步骤中,将最后一棵树级别的所有非终端叶子分开。使用导致最佳损失改善的条件来分裂叶子。在中Lossguide,逐叶构建树,直到达到指定的叶数。在每个步骤中,将损耗改善最佳的非终端叶子进行拆分 -
min_data_in_leaf别名min_child_samples—这是一片叶子中训练样本的最小数量。此参数仅与Lossguide和Depthwise增长策略一起使用。 -
max_leavesaliasnum_leaves—此参数仅与Lossguide策略一起使用, 并确定树中的叶子数。 -
ignored_features—表示在培训过程中应忽略的功能。 -
nan_mode—处理缺失值的方法。选项包括Forbidden,Min,和Max。默认值为Min。当Forbidden使用时,缺失值导致错误的存在。使用Min,缺少的值将作为该功能的最小值。在中Max,缺失值被视为特征的最大值。 -
leaf_estimation_method—用于计算叶子中值的方法。在分类中,使用10Newton次迭代。使用分位数或MAE损失的回归问题使用一次Exact迭代。多分类使用一次Netwon迭代。 -
leaf_estimation_backtracking—在梯度下降过程中使用的回溯类型。默认值为AnyImprovement。AnyImprovement减小下降步长,直至损失函数值小于上次迭代的值。Armijo减小下降步长,直到满足 Armijo条件 。 -
boosting_type—加强计划。它可以plain用于经典的梯度增强方案,也可以 用于或ordered,它在较小的数据集上可以提供更好的质量。 -
score_function— 分数类型, 用于在树构建过程中选择下一个拆分。Cosine是默认选项。其他可用的选项是L2,NewtonL2和NewtonCosine。 -
early_stopping_rounds—当时True,将过拟合检测器类型设置为,Iter并在达到最佳度量时停止训练。 -
classes_count—多重分类问题的类别数。 -
task_type—使用的是CPU还是GPU。CPU是默认设置。 -
devices—用于训练的GPU设备的ID。 -
cat_features—具有分类列的数组。 -
text_features-用于在分类问题中声明文本列。
回归示例
CatBoost在其实施中使用scikit-learn标准。让我们看看如何将其用于回归。
与往常一样,第一步是导入回归器并将其实例化。

拟合模型时,CatBoost还可以通过设置来使用户可视化
plot=true
:
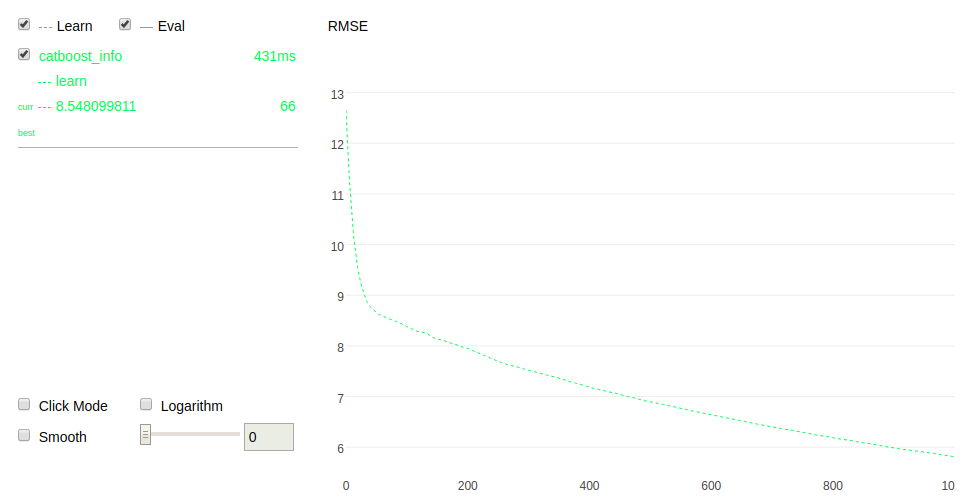
它还允许您执行交叉验证并使过程可视化:

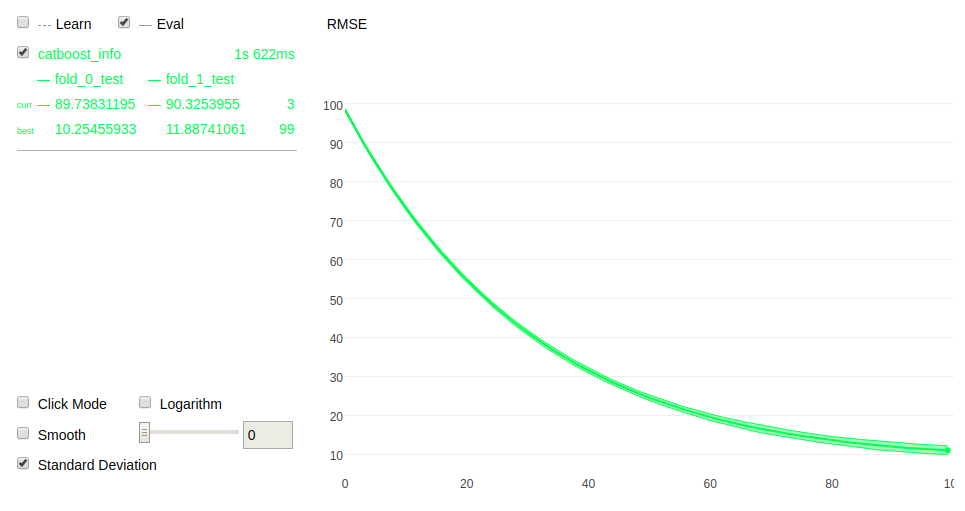
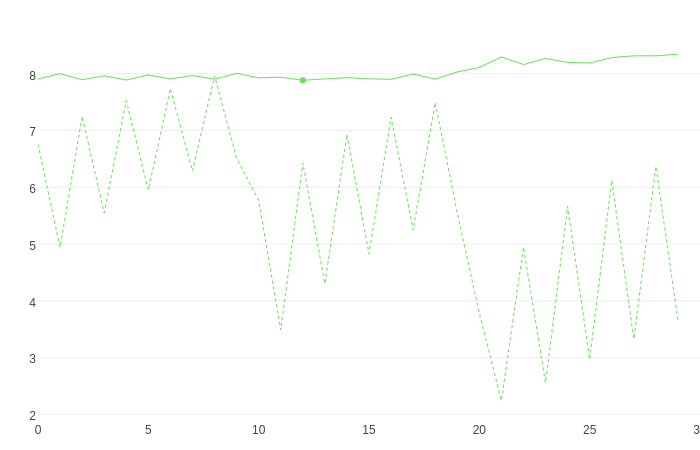
同样,您也可以执行网格搜索并将其可视化:

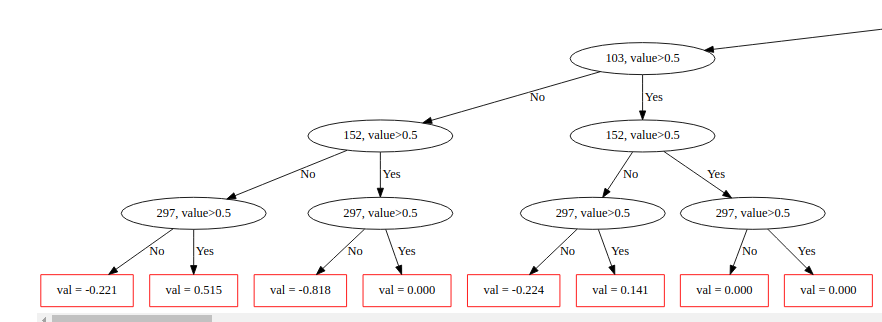
我们还可以使用CatBoost绘制树。这是第一棵树的情节。从树上可以看到,每个级别的叶子都在相同的条件下被分割,例如297,值> 0.5。

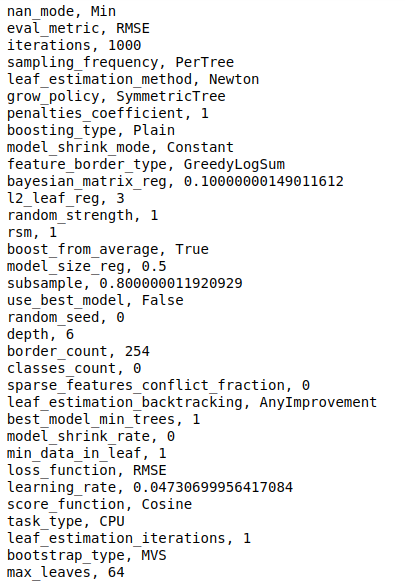
CatBoost还为我们提供了包含所有模型参数的字典。我们可以通过遍历字典来打印它们。

结尾
在本文中,我们探讨了CatBoost的优点和局限性以及主要的训练参数。然后,我们使用scikit-learn完成了一个简单的回归实现。希望这可以为您提供有关库的足够信息,以便您可以进一步探索它。
往期精彩链接:
《统计学习基础:数据挖掘、推理和预测》-斯坦福大学人工智能学科专用教材

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK