

VisDA-2020 技术方案分享
source link: https://zhuanlan.zhihu.com/p/265758275
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文介绍我们在ECCV 2020的Visual Domain Adaptation Challenge中取得第二名的技术方案,该方案主要结合了两个我们自己的工作:MMT[1]和SDA[2],并且在原始MMT的基础上进行了升级,提出MMT+,用以应对更嘈杂的目标域数据。比赛结束快三个月了,终于抽出空来总结一下,也方便以后的参赛者参考。代码和模型均已公开。
比赛链接: http:// ai.bu.edu/visda-2020/
技术报告链接: Improved Mutual Mean-Teaching for Unsupervised Domain Adaptive Re-ID
代码链接: https:// github.com/yxgeee/MMT-p lus
视频介绍: https://www. bilibili.com/video/BV14 V411U7mb
比赛

今年视觉领域自适应的比赛关注于行人重识别问题,参见主办方推文:
https://zhuanlan.zhihu.com/p/137644578 zhuanlan.zhihu.com
背景技术
目前针对领域自适应行人重识别的算法主要分为两类:
1) 域转换类 ,如:SPGAN、PTGAN、SDA等。算法主要分为两步,第一步先训练一个GAN模型将源域图像转换为目标域风格,并保持原本ID;第二步利用转换后的源域图像及其真实标签进行训练,获得最终模型。 优势 在于可以充分利用源域图像; 劣势 在于目前来看单独使用时性能不佳。
2) 伪标签类 ,如:SSG、PAST、MMT等。训练过程中在两步之间交替进行,其中第一步是利用聚类算法(也有的算法不使用聚类,这里主要介绍基于聚类的算法)为目标域图像生成伪标签,第二步是利用伪标签与目标域图像进行训练。 优势 在于目前公共benchmark上一直保持SoTA的性能; 劣势 在于当伪标签噪声较大时,训练不稳定,甚至误差放大。
挑战
该比赛与公共benchmark相比,最大的两项挑战在于:
1)源域为合成行人图像(PersonX[3]),目标域为真实行人图像, 域差异较大 。若直接使用源域图像进行模型的预训练,预训练的模型在目标域上表现非常差,从而生成的伪标签也不理想。 解决方案 为,先利用域转换算法(SDA)将源域图像的风格迁移到目标域,再做预训练,这样可以较大程度上提升初始伪标签的质量,从而有助于后续的伪标签法。
2) 目标域ID分布较为嘈杂 ,有的人可能有多张图片,而有的人可能只有很少的图片,为聚类型算法带来挑战。 解决方案 为,进一步改进伪标签算法(MMT+)以对抗较大的伪标签噪声,保证模型鲁棒性。
技术框架
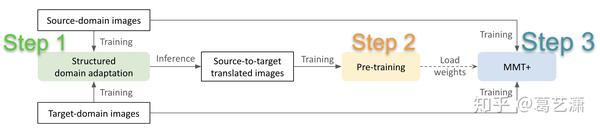
我们的总体训练框架主要分为三步:利用SDA算法训练的GAN模型将源域图像转换到目标域、利用转换后的源域图像进行预训练、在预训练后的模型基础上利用MMT+算法继续训练。下面具体介绍每个步骤。
训练步骤一:SDA域转换
Structured Domain Adaptation (SDA)是我们在19年下半年所做的一篇工作,很不幸的是一直还没有被收录,但是该方法在域转换上还是很有效的,论文如下:
Structured Domain Adaptation with Online Relation Regularization for Unsupervised Person Re-ID arxiv.org该方法的idea很简单,主要围绕一个loss,文中称作 关系一致性损失 (relation-consistency loss)。Intuition是,在训练域转换GAN模型时,要求源域图像风格迁移后,图像间的关系保持不变,这样可以更好地维持源域图像原有的信息和数据分布。
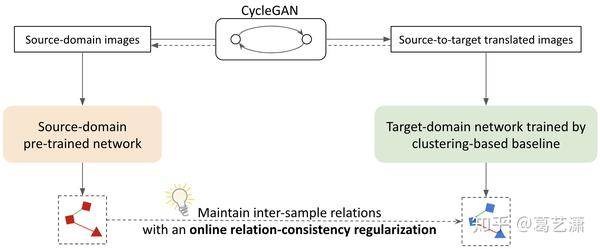
和经典工作SPGAN相比时,SDA迁移的源域图像在目标域仍保持良好的类内关系,如下图所示,蓝色裙子的人在经过SPGAN的域转换后变成了蓝裙子和白裙子,而SDA维持了蓝色裙子。

具体训练细节在这里不展开了,感兴趣的同学可以参阅SDA的原论文以及比赛的technique report。
训练步骤二:转换后的源域图像预训练
对源域图像进行域转换的目的是,提供更好的预训练模型。所以,我们使用训练好的SDA将所有源域图像转移到目标域,并用其进行网络的预训练。如下图所示,无论是SPGAN还是SDA,用域转换后的源域图像进行预训练比原始源域图像预训练所得到的的模型精度要明显高出许多。

关于源域的预训练,我们总结了几点有用的training tricks:
- 使用auto-augmentation可以有效避免overfit;
- 使用GeM pooling代替average pooling;
- 一个在MMT开源代码中涉及的trick:虽然目标域图像无标签,但是也可以用于在训练过程中进行forward computation,可以一定程度上有效地将BN adapt到目标域,以下是伪代码。

训练步骤三:MMT+目标域训练
Mutual Mean-Teaching (MMT) 是我们发表于ICLR 2020上的工作,框架非常有效,在公共benchmark上一直保持SoTA水平。以下是以前写的论文讲解,
https://zhuanlan.zhihu.com/p/116074945 zhuanlan.zhihu.com
我们将原始的MMT画成以下示意图:
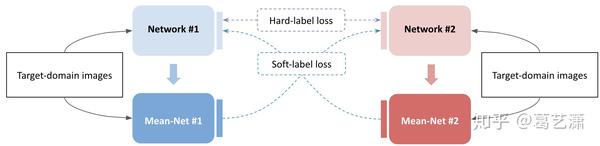
之前提到,该比赛的目标域数据集ID分布较为嘈杂,导致伪标签噪声很大,为了进一步减轻伪标签噪声对MMT训练带来的影响,我们采取了以下两个措施:
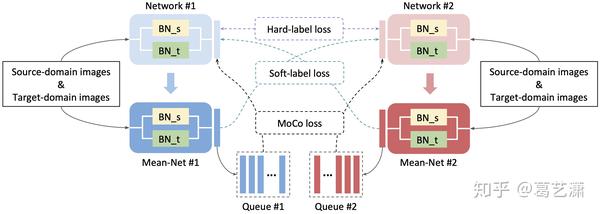
- 加入源域的图像进行协同训练,等于是加入了有真实标签的干净数据,这里使用Domain-specific BN[4]来消除domain gap对训练的影响;
- 加入MoCo[5] loss进行实例区分任务,一定程度上抵消错误的伪标签带来的影响。值得注意的是,由于MMT中的Mean-Net和MoCo中的momentum encoder基本上一致,所以在MMT中加入MoCo loss很方便。
结合以上两点后,我们将新的框架称之为MMT+:
这里还是送大家一点干货,training tricks:
- 使用ArcFace或CosFace代替普通的linear classification loss;
- 由于ArcFace或CosFace已经很强了,所以triplet loss作用不大了;
- 使用GeM pooling代替average pooling;
- 一个实验性的结论,不要在这一步使用auto-augmentation;
- 一个在MMT开源代码中涉及的trick:每次重新聚类后重置优化器。
对比一下MMT+与原始MMT的性能差异:

测试后处理:
- 模型融合
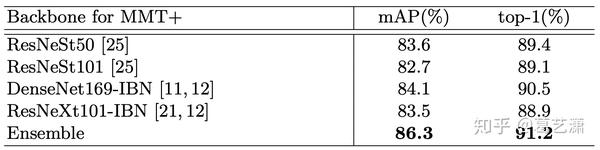
融合了四个backbone,具体做法很简单,就是提取特征->concate->L2-norm。
- 消除相机偏差 [6]:单独训练一个相机分类模型,在原始person similarity的基础上减去camera similarity。
- K-reciprocal re-ranking [7]
总结
我们主要在模型训练上进行了改进,充分利用了域转换和伪标签两类方法,每个模型单独的性能都是不错的。但是比赛小白,测试后处理上差了点意思,还是有很大提升空间的,再接再厉。感谢组委会,祝以后的参赛者好运。
[1] Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification. ICLR 2020.
[2] Structured Domain Adaptation with Online Relation Regularization for Unsupervised Person Re-ID.
[3] Dissecting Person Re-identification from the Viewpoint of Viewpoint. CVPR 2019.
[4] Domain-Specific Batch Normalization for Unsupervised Domain Adaptation. CVPR 2019.
[5] Momentum Contrast for Unsupervised Visual Representation Learning. CVPR 2020.
[6] Voc-reid: Vehicle re-identification based on vehicle orientation camera. CVPRW 2020.
[7] Re-ranking person re-identification with k-reciprocal encoding. CVPR 2017.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK