

pytorch和tensorflow的爱恨情仇之定义可训练的参数
source link: http://www.cnblogs.com/xiximayou/p/13763059.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
pytorch和tensorflow的爱恨情仇之基本数据类型
pytorch版本:1.6.0
tensorflow版本:1.15.0
之前我们就已经了解了pytorch和tensorflow中的变量,本节我们深入了解可训练的参数-变量
接下来我们将使用sklearn自带的iris数据集来慢慢品味。
1、pytorch
(1)第一种方式,不使用nn.Module或nn.Sequntial()来建立模型的情况下自定义参数;
加载数据集并转换为tensot:
import torch import torch.nn.functional as F import numpy as np from sklearn.datasets import load_iris iris = load_iris() data=iris.data target = iris.target
data = torch.from_numpy(data).float() #(150,4) target = torch.from_numpy(target).long() #(150,3) batch_size=data.shape[0] #设置batchsize的大小就是所有数据 dataset = torch.utils.data.TensorDataset(data, target) # 设置数据集 train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) # 设置获取数据方式
自己定义好要训练的参数:
classes = 3 input = 4 hidden = 10 w_0 = torch.tensor(np.random.normal(0, 0.01, (input, hidden)), dtype=torch.float) b_0 = torch.zeros(hidden, dtype=torch.float) w_1 = torch.tensor(np.random.normal(0, 0.01, (hidden, classes)), dtype=torch.float) b_1 = torch.zeros(classes, dtype=torch.float)
我们可以在定义参数的时候指定requires_grad=True使其为可训练的参数,也可以使用如下方式:
params = [w_0, b_0, w_1, b_1]
for param in params:
param.requires_grad_(requires_grad=True)
定义学习率、优化器、损失函数、网络
lr = 5
optimizer = None
criterion = torch.nn.CrossEntropyLoss()
epoch = 1000
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
def net(x):
h = torch.matmul(x,w_0)+b_0
h = F.relu(h)
output = torch.matmul(h,w_1)+b_1
#output = F.softmax(output,dim=1)
return output
为了更加清楚参数训练的过程,这里我们不使用pytorch自带的,而是我们自己定义的随机梯度下降。
定义训练主函数:
def train(net,params,lr,train_iter):
for i in range(1,epoch+1):
for x,y in train_iter:
output = net(x)
loss = criterion(output,y)
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
loss.backward()
if optimizer is None:
sgd(params, lr, batch_size)
else:
optimizer.step() # “softmax回归的简洁实现”一节将用到
acc = (output.argmax(dim=1) == y).sum().item() / data.shape[0]
print("epoch:{:03d} loss:{:.4f} acc:{:.4f}".format(i,loss.item(),acc))
train(net=net,params=params,lr=lr,train_iter=train_iter)
从这里我们也可以看到optimizer.zero_grad()和optimizer.step()的作用了,以上便是我们自定义训练参数的完整过程了,看下结果:
epoch:994 loss:0.0928 acc:0.9800 epoch:995 loss:0.0927 acc:0.9800 epoch:996 loss:0.0926 acc:0.9800 epoch:997 loss:0.0926 acc:0.9800 epoch:998 loss:0.0925 acc:0.9800 epoch:999 loss:0.0925 acc:0.9800 epoch:1000 loss:0.0924 acc:0.9800
(2)使用nn.Sequential()来构建模型,进行参数初始化:
导入相应的包并加载数据集:
import torch import torch.nn as nn import torch.nn.init as init import torch.nn.functional as F import numpy as np from sklearn.datasets import load_iris iris = load_iris() data=iris.data target = iris.target
转换为pytorch数据格式:
data = torch.from_numpy(data).float() target = torch.from_numpy(target).long() batch_size=data.shape[0] dataset = torch.utils.data.TensorDataset(data, target) # 设置数据集 train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True) # 设置获取数据方式
定义相关超参数:
classes = 3 input = 4 hidden = 10 lr = 4 optimizer = None
定义网络:
net = nn.Sequential(
nn.Linear(input,hidden),
nn.ReLU(),
nn.Linear(hidden,classes),
)
参数初始化:
for name,param in net.named_parameters(): #使用model.named_parameters()可以获得相应层的名字的参数以及具体值
if "weight" in name:
init.normal_(param, mean=0, std=0.01)
if "bias" in name:
init.zeros_(param)
自定义随机梯度下降优化器:
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
训练主循环:
epoch = 1000
criterion = torch.nn.CrossEntropyLoss()
def train(net,lr,train_iter):
for i in range(1,epoch+1):
for x,y in train_iter:
output = net(x)
loss = criterion(output,y)
# 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif net.parameters() is not None:
for param in net.parameters():
if param.grad is not None:
param.grad.data.zero_()
loss.backward()
if optimizer is None:
sgd(net.parameters(), lr, batch_size)
else:
optimizer.step() # “softmax回归的简洁实现”一节将用到
acc = (output.argmax(dim=1) == y).sum().item() / data.shape[0]
print("epoch:{:03d} loss:{:.4f} acc:{:.4f}".format(i,loss.item(),acc))
return
train(net=net,lr=lr,train_iter=train_iter)
结果:
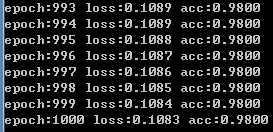
(3) 使用pytorch自带的优化器
我们只需要将opyimizer设置为以下即可:
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
需要注意的是学习率这里需要设置的比较小一点,和上面设置的有所不同,结果如下:
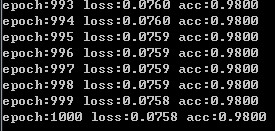
(4) 使用nn.Module来构建网络,自定义参数并进行初始化
我们只需要修改以下地方即可:
class Net(nn.Module):
def __init__(self,input,hidden,classes):
super(Net, self).__init__()
self.input = input
self.hidden = hidden
self.classes = classes
self.w0 = nn.Parameter(torch.Tensor(self.input,self.hidden))
self.b0 = nn.Parameter(torch.Tensor(self.hidden))
self.w1 = nn.Parameter(torch.Tensor(self.hidden,self.classes))
self.b1 = nn.Parameter(torch.Tensor(self.classes))
self.reset_parameters()
def reset_parameters(self):
nn.init.normal_(self.w0)
nn.init.constant_(self.b0,0)
nn.init.normal_(self.w1)
nn.init.constant_(self.b1,0)
def forward(self,x):
out = torch.matmul(x,self.w0)+self.b0
out = F.relu(out)
out = torch.matmul(out,self.w1)+self.b1
return out
net = Net(input,hidden,classes)
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
结果:
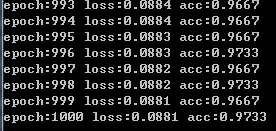
(5) 使用nn.Module()构建网路,并使用各层中的参数并进行初始化
class Net(nn.Module):
def __init__(self,input,hidden,classes):
super(Net, self).__init__()
self.input = input
self.hidden = hidden
self.classes = classes
self.fc1 = nn.Linear(self.input,self.hidden)
self.fc2 = nn.Linear(self.hidden,self.classes)
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias, 0)
def forward(self,x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
return out
net = Net(input,hidden,classes)
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
结果:
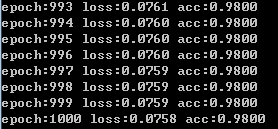
PyTorch 中参数的默认初始化在各个层的 reset_parameters()
方法
我们看下官方的Linear层的实现:
官方Linear层:
class Linear(Module):
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
def extra_repr(self):
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)
(6) 最后我们来看下从网络中获取参数名字和参数值的一些例子
我们以这个网络为例:
class Net(nn.Module):
def __init__(self,input,hidden,classes):
super(Net, self).__init__()
self.input = input
self.hidden = hidden
self.classes = classes
self.fc1 = nn.Linear(self.input,self.hidden)
self.fc2 = nn.Linear(self.hidden,self.classes)
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight,0,0.01)
nn.init.constant_(m.bias, 0)
def forward(self,x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
return out
net = Net(input,hidden,classes)
首先是model.state_dict():是一个参数字典,键是参数的名称,值是参数的值:
for name,value in net.state_dict().items():
print(name,value)
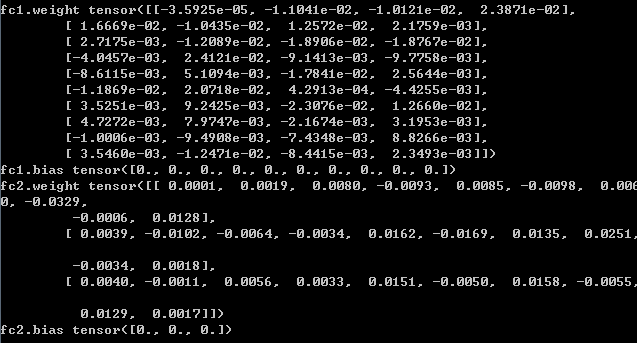
接着是:model.parameters():返回的是一个generator,我们之前也经常使用,通过param.data,param.data.grad来获取参数的值以及梯度
for param in net.parameters():
print(param.data,param.grad)
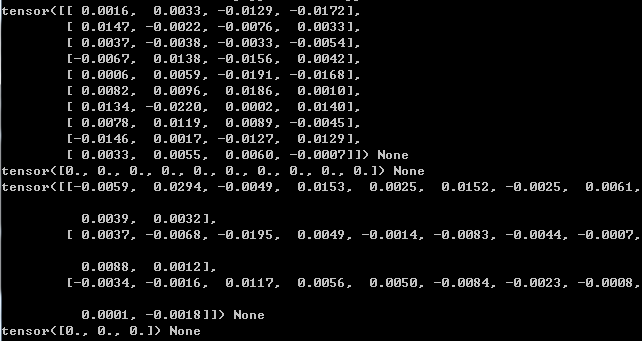
接着是model.named_parameters():返回的是一个具名参数,也就是包含了参数的名称
for name,param in net.named_parameters():
print(name,param)
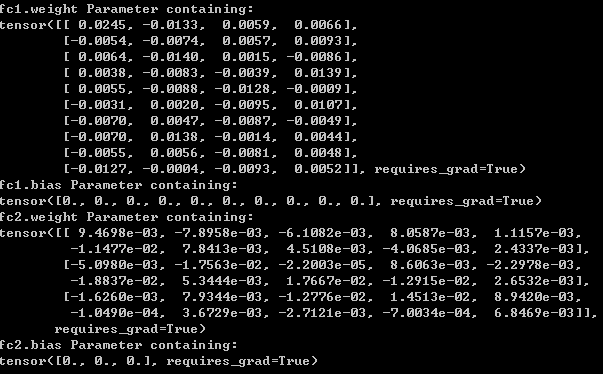
最后讲下的是self.modules():一般是在网络初始化中使用,返回的是网络中的具体层,我们可以通过其对不同层进行参数初始化,比如nn.Conv2d、nn.Linear等;
参考:
https://www.cnblogs.com/KaifengGuan/p/12332072.html
https://www.geekschool.org/2020/08/02/13455.html
https://blog.csdn.net/weixin_44058333/article/details/92691656
(2)tensorflow
导入相应的包并加载数据:
import tensorflow as tf import numpy as np from sklearn.datasets import load_iris from sklearn.preprocessing import OneHotEncoder iris = load_iris() data=iris.data target = iris.target
将标签转换为onehot编码:
oneHotEncoder = OneHotEncoder(sparse=False) onehot_target = oneHotEncoder.fit_transform(target.reshape(-1,1)) print(onehot_target)
定义超参数以及可训练的参数:
input=4 hidden=10 classes=3 w0=tf.Variable(tf.random.normal([input,hidden],stddev=0.01,seed=1)) b0=tf.Variable(tf.zeros([hidden])) w1=tf.Variable(tf.random.normal([hidden,classes],stddev=0.01,seed=1)) b1=tf.Variable(tf.zeros([classes]))
定义计算图中的占位符:
x = tf.placeholder(tf.float32,shape=(None,input),name="x-input") #输入数据 y_ = tf.placeholder(tf.float32,shape=(None,classes),name="y-input") #真实标签
定义网络、损失函数和优化器:
def net(x):
hid = tf.add(tf.matmul(x,w0),b0)
hid = tf.nn.relu(hid)
out = tf.add(tf.matmul(hid,w1),b1)
out = tf.nn.softmax(out)
return out
y = net(x)
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)) \
+ (1-y_)*tf.log(tf.clip_by_value(1-y,1e-10,1.0)))
optimizer=tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.05).minimize(cross_entropy)
训练循环:
epoch = 1000
with tf.compat.v1.Session() as sess: #建立会话
init_op = tf.global_variables_initializer() #初始化参数
sess.run(init_op)
for epoch in range(1,epoch+1):
sess.run(optimizer,feed_dict={x:data,y_:onehot_target}) #传入数据给优化器
y_pred = sess.run(y,feed_dict={x:data}) #计算输出
total_cross_entropy = sess.run(cross_entropy,feed_dict={y:y_pred,y_:onehot_target}) #计算交叉熵
pred = tf.argmax(y_pred,axis = 1) # 取出行中最大值的索引,也就是取出其中概率最大的索引
correct = tf.cast(tf.equal(pred,target),dtype=tf.int32) # 判断与测试集的标签是否相等并且转换bool为int型
correct = tf.reduce_sum(correct) # 沿着指定维度的和,不指定axis则默认为所有元素的和
acc = correct.eval() / data.shape[0]
print("epoch:{} loss:{:.4f} acc:{:.4f}".format(epoch, total_cross_entropy,acc))
结果:
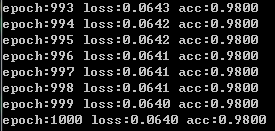
但感觉训练1000个epoch比pytorch慢好多。。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK