

搞定SQL!5个棘手SQL查询的解决方法
source link: http://database.51cto.com/art/202010/627767.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
对于数据科学家来讲,SQL(结构化查询语言)是其工具箱中比较重要的工具之一。掌握SQL不仅有助于你在面试中脱颖而出,而且通过解决复杂查询达到对SQL的充分理解,还能在让你许多竞争中保持领先地位。

本文就将介绍5个有关SQL的棘手问题和其解决方法。注意,每个查询都能以不同方式编写。在参考本文解决方案之前,你可以先试着自己思考一下。
查询1
下列表格由名字和职业两列组成。需要查询所有姓名,且使其后紧跟一个括号,括住“职业”列中对应的首字母。

- 本文解决方案
SELECT CONCAT(Name, ’(‘, SUBSTR(Profession, 1, 1), ’)’) FROM table;
由于需要把名字和职业结合起来,可以使用CONCAT。而且因为括号内只需要一个字母,可以使用SUBSTR来传递列名、开始索引和结束索引。因为只需要首字母,所以我们将传递1,1(开始索引包括在内,结束索引不包括在内)。
查询2
蒂娜需要从她创建的EMPLOYEES表中计算所有员工的平均工资,但结果显示的平均值很低,这可能是键盘上的回零键失效了。她希望我们帮助找出错误计算的平均值和实际平均值之间的差异。我们须编写一个查找错误的查询(实际平均值-计算平均值)。
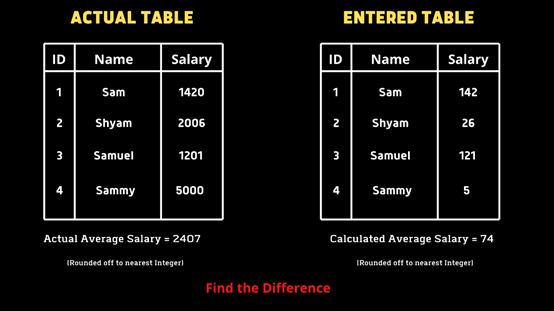
- 本文解决方案
SELECT AVG(Salary) - AVG(REPLACE(Salary, 0, ’’)) FROM table;
需要注意,只有一个表包含了实际工资值。为了创建错误场景,使用REPLACE替换0。接着传递列名、替换值以及用于替换REPLACE方法的值。然后,使用聚集函数AVG来求平均值的差。
查询3
给定一个表,它是由节点和父节点两列组成的二元搜索树。需要编写一个查询,以返回按节点值进行升序排序的节点类型。有3种类型:
- 根(Root)——如果节点是根
- 叶(Leaf)——如果节点是叶
- 内部(Inner)——如果节点既不是根也不是叶

- 本文解决方案
经过初步分析,可以得出结论:如果给定节点N的相应P值为NULL(空),则它是根。而如果给定节点N存在于P列中,则它不是内部节点。基于此想法编写一个查询。
SELECT CASE WHEN P IS NULL THENCONCAT(N, ' Root') WHEN N IN (SELECTDISTINCT P from BST) THEN CONCAT(N, ' Inner') ELSE CONCAT(N, ' Leaf') ENDFROM BSTORDER BY N asc;
可使用CASE作为开关函数。正如前文提到的,如果对于给定节点N,P为空值,则N是根。因此,我们使用CONCAT来组合节点值和标签。
类似地,如果给定节点N存在于P列中,则它是内部节点。为了获得P列中的所有节点,我们编写了一个返回P列中所有不同节点的子查询。由于要求按节点值升序对输出进行排序,因此要使用ORDER BY子句。
查询4
该事务表由transaction_id, user_id, transaction_date,product_id, and quantity(交易ID,用户ID,交易日期,产品ID和数量)组成。需要查询多天来购买产品的用户数量(注意,给定用户可以在一天内购买多个产品)。

- 本文解决方案
为了解决该查询,不能直接计算user_id的出现次数,由于给定用户在一天中可以多次购买,user_id或许会有多次返回。因此,只有当存在多个不同日期与给定的user_id相关联时,才意味着该用户多天购买了产品。按照相同方法,进行查询编写。(内部查询)
SELECT COUNT(user_id) FROM (SELECT user_id FROM orders GROUP BY user_id HAVING COUNT(DISTINCT DATE(date))> 1 ) t1
由于问题询问的是user_id的数量,而不是user_id本身,因此在外部查询中使用 COUNT 。
查询5
给定一个订阅表,其中包含每个用户订阅的开始和结束日期。需要编写一个查询,根据与其他用户的日期重叠情况,为每个用户返回true/false。例如,如果user1的订阅周期与其他任何用户重叠,则查询必须为user1返回true。

- 本文解决方案
经过初步分析,我们可以知道必须将每项订阅与其他订阅进行比较。将userA的开始和结束日期视为startA 和endA,类似地,userB也依此设为startB和endB。如果startA≤endB且endA≥startB,则可以说这两个日期范围重叠。我们来举两个例子,先比较一下U1和U3:
startA = 2020–01–01 endA = 2020–01–31 startB = 2020–01–16 endB = 2020–01–26
这里可以看出,startA(2020–01–01)小于endB(2020–01–26),那么同样,endA(2020–01–31)大于 startB(2020–01–16),因此可以得出结论,日期重叠。类似地,如果比较U1和U4,上述条件就不成立,于是返回FALSE。
这里还必须确保不会将用户与其自己的订阅进行比较。同时希望运行一个左连接,能够自行将用户与满足条件的其他用户进行匹配。现在,我们将创建同一表的两个副本S1和S2。
SELECT * FROM subscriptions AS s1 LEFT JOIN subscriptions AS s2 ON s1.user_id != s2.user_id AND s1.start_date <=s2.end_date AND s1.end_date >=s2.start_date
给定条件连接,在日期之间存在重叠的情况下,对于S1中的每个user_id,应该存在来自S2的user_id。
- 输出

可以看到,以防日期重叠,每个用户都有一个对应用户。对于user1,有2行显示其与2个用户相匹配。对于用户4,对应的ID为空,表示他与其他任何用户都不匹配。现在,将其全部组合在一起,按照s1.user_ID字段进行分组,并检查s2.user_ID不为空的用户的值是否为真。
- 最终查询
SELECT s1.user_id , (CASE WHEN s2.user_idIS NOT NULL THEN 1 ELSE 0 END) AS overlap FROM subscriptions AS s1 LEFT JOIN subscriptions AS s2 ON s1.user_id != s2.user_id AND s1.start_date <=s2.end_date AND s1.end_date >=s2.start_date GROUP BY s1.user_id
使用 CASE子句根据给定用户的s2.user_id值来标记1和0。最终输出如下:


Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK