

网络编程的未来,io_uring?
source link: https://www.sdnlab.com/24474.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

前言
熟悉Linux网络或者存储编程的开发人员,对于libaio [1] (Linux-native asynchronous I/O) 应该并不太陌生。Libaio提供了一套不同于POSIX接口的异步I/O接口,其目的是更加高效的利用I/O设备。在最近几年的过程中,有很多Linux 开发人员试图去优化libaio相关的实现,但是收效甚微。于是Jens [2] 开发了一套新的异步编程接口io_uring [3] ,主要是为了替代libaio,目前主要应用在存储的场景中。相比使用libaio,在存储中使用io_uring,那么应用的性能有了显著的提升。比如说用FIO程序,采用不同的存储引擎libaio和io_uring测试同样的NVMe SSD(见[4]),io_uring的效果要好不少。为此也有一些文章宣称,在某些场景下使用io_uring + Kernel NVMe的驱动,效果甚至要比使用SPDK 用户态NVMe 驱动更好。当然在SPDK 项目中,用户也进行如下的对比,使用FIO + SPDK bdev 测试同样的NVMe 盘,可以采用以下的三种bdev进行性能比较: (1) 基于SPDK中用户态NVMe驱动的bdev; (2) 基于SPDK中libaio实现的bdev;(3) 基于SPDK中io_uring实现的bdev。然后可以自行比较一下哪种方式性能最好。
在这篇文章中,我们主要是把io_uring使用在网络中。为了使得大家更清晰的了解,我们将在本文中介绍如下内容:
- SPDK socket API的现状
- SPDK中怎么高效利用kernel TCP/IP 栈
- io_uring目前存在的一些问题
- 在SPDK 中怎么使能io_uring
SPDK socket API 现状
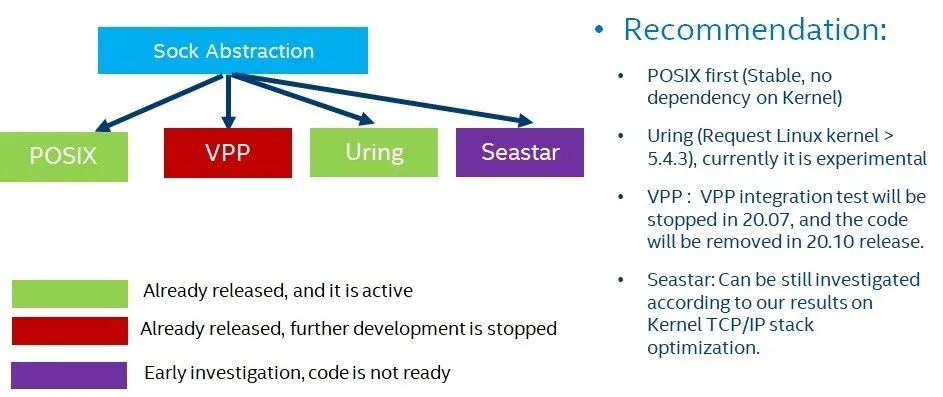
在SPDK的代码库,我们有一个socket API 位于(lib/sock)目录下,这个SPDK socket API主要用于封装各个不同的TCP/IP的socket实现,包括基于内核TCP/IP的socket, 以及用户态的socket实现。图1给出了目前代码中实现的一些情况, SPDK 20.04 版本以及主分支上有三种sock封装, POSIX(module/sock/posix), uring(module/sock/uring), vpp (module/sock/vpp) 。其中POSIX库主要是使用了POSIX的接口去操纵kernel的TCP/IP 栈,uring主要是采用io_uring的接口去使用kernel TCP/IP的栈,VPP 的socket主要是整合了VPP的用户态TCP/IP 栈。从图1中我们可以看到,目前我们主要推荐POSIX的实现。因为uring socket的实现需要环境的支持,比如对Linux kernel版本的要求。目前Linux kernel对于io_uring的支持还在开发过程中,所以在SPDK 中基于io_uring的socket实现,需要不断地完善和更新。但是不可否认,使用io_uring来高效地使用kernel TCP/IP 栈是未来的发展趋势。
对于SPDK中VPP的整合,目前的状况是在SPDK中的集成,将会在20.07停止,20.10中把VPP的sock实现从SPDK 中删除。其主要原因是基于VPP的sock实现并没有体现出相应的性能优势,具体的声明可以参考 [5] 。至于Seastar在SPDK 的集成工作,目前也处于停滞的阶段, 具体patch请见[6]。现在SPDK socket API工作的重点在怎么高效利用kernel的TCP/IP栈实现。
高效使用kernel TCP/IP 栈
SPDK 的编程框架的总体思想是异步(asynchronous),数据通路无锁化(lock free data path),以及基于用户态的存储协议栈。虽然kernel TCP/IP 栈在内核中的实现并不是无锁的,但是应用程序可以尽可能高效地利用kernel TCP/IP 栈。为了配合SPDK的编程框架,我们采用了以下的方法在用户态高效利用kernel TCP/IP栈,可以分为以下两类,针对单socket以及针对多socket。
针对单socket的优化
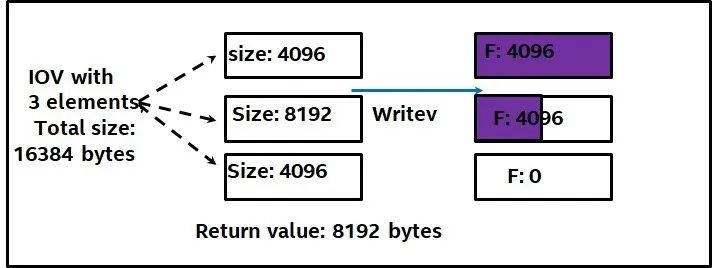
1. 采用非阻塞的I/O。 对于一个SOCKET File Descriptor(简称为SOCK_FD)。我们需要通过系统调用设置相应的属性O_NONBLOCK。这个主要是因为在发生调用的时候,诸如read或者write。我们不希望调用者阻塞在那里。因为根据SPDK的framework,我们还有其他任务去做(参考SPDK 编程framework这篇文章[7])。如果采用阻塞的I/O将会影响到后续其他任务的调度。当然采用非阻塞I/O,就必须要处理可能存在的部分读或者写的问题(partial read/write)。举个例子如图2 所示,用户发起了一个writev操作,vector里面有三个元素,长度分别是4096, 8192,8192,总长度是16384。那么可能返回结果是,第一个元素的写全部完成,第二个完成了一半,第三个什么都没完成。很显然我们需要处理这样的情况,要么让用户自己处理,要么在SPDK 库里面需要处理。
2.减少系统调用。我们知道使用内核TCP/IP栈使用网络读写,需要利用系统调用。频繁的系统调用会产生大量的上下文切换(进程和内核之间)。为此有必要减少系统调用。
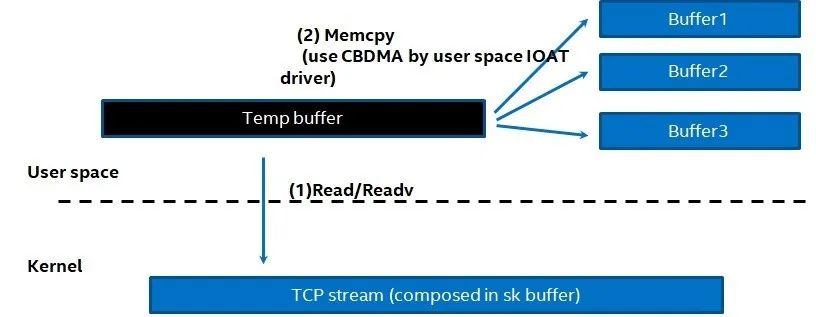
- 对读系统调用的优化。对于读的系统调用,我们可以采用以下的策略。比如在用户态开辟一片较大的缓存,然后尽可能一次性读取大量数据,如图3 所示。这里我们可以看到在用户态分配了一个大的临时buffer,然后采用read或者readv进行操作,然后把读到的内容分配拷贝到用户自己逻辑的Buffer1,Buffer2或者Buffer3中。这里读者不仅要问,为什么不能直接利用Buffer1-3 直接构建一个vector数组,进行readv读写。这个问题在于, 并不是在任何时候,我们都能明确知道要进行读的地址。举个例子,比如在NVMe-oF TCP的parse过程中,我们可以把PDU的header配置一个buffer,PDU所涉及到的数据采用另外一个buffer。但是并不是每个PDU 都有带有数据。所以我们不能保证在进行读的时候,知道所有buffer的地址。这么看来不能减少数据的拷贝。显然用这样的方法,我们可以减少读操作的系统调用,但是增加了新的代价,即数据拷贝。为此我们必须做到平衡,意思是在减少系统调用的时候,尽可能采用一些其他硬件卸载数据拷贝的代价。比如在Intel平台上我们可以使用CBDMA(Crystal beach DMA)或者DSA (Data Streaming Accelerator) 去进行copy操作,用于减轻CPU的工作。
- 合并写操作减少系统调用。对于写的操作,为了减少系统调用,我们可以把多个writev操作合并成一个writev操作。其主要思路就是构建一个新的vector数组,把多个writev各自的vector数据的信息放入。这样可以减少写的系统调用。
3. 采用MESSAGE ZERO COPY。 在网络编程中,写数据可以采用zero copy。这个特性在Linux 4.1. 4以后支持。比如在SPDK POSIX sock的实现中,我们对于写的IO, 在target 那端,采用了Message zero copy。这个需要调用setsockopt系统调用对SOCK_FD进行设置(使用这个key:SO_ZEROCOPY)。然后在对socket进行写的时候,我们不在使用writev,而是采用sendmsg, 然后采用MSG_ZEROCOPY 对应的flag。这样的好处是我们可以避免I/O copy。那么Linux网络内核栈会Pin住用户提供的内存,而不是将其复制到内核中的发送缓冲区。当然Pin住这些内存,需要有额外的代价。另外采用MSG_ZEROCOPY 后,会产生一些额外的事件, 即target端Message control path上的错误事件: MSG_ERRQUEUE。我们需要进行相应的处理。因为在POSIX实现中,我们也使用了异步的写接口,为此必须等到那个写操作已经完成了,然后调用相应的callback函数。
目前1 和2相应的实现已经存在于SPDK的POSIX和uring的socket实现中, 3的实现主要在POSIX中。
针对多socket的优化
除了针对单socket的优化,SPDK socket实现中采用了以下的机制,来保证更高效的运行;
1. 采用唯一的SPDK thread 管理一个socket 的生命周期。在SPDK 中,对于每个连接(可以对应到相应的socket)I/O 读写处理,我们都使用唯一的SPDK thread。这意味着,我们尽可能避免了多个CPU 在竞争处理同一个连接。为了做到这一点,当我们的Socket Listener得到一个新的连接的时候,我们就可以利用算法把这个connection的处理调度到一个特定的SPDK thread之上处理。
2. 基于组的高效异步I/O 处理。一个SPDK thread可以管理多个连接,为了更高效地处理每个I/O上发生的读写事件。当然用户调用SPDK 基于组的polling的时候(函数是spdk_sock_group_poll) 我们采取了如下策略:
- 一次性侦测组中所有socket的POLLIN 事件。 比如在POSIX SOCK实现中,我们采用epoll的机制。在每一轮中,一次性调用epoll_wait去侦测组中哪些socket有读的事件。这样相比用read或者readv去单独侦测哪个socket有读时间要好很多。举个极端的例子,如果一个组中有100个连接,如果只有一个连接有读的事件。那么采用epoll的方式,我们只用了两个系统调用,epoll_wait以及read。但是不采用epoll,我们需要100个系统调用,即对每个连接调用read或者readv。
- 减少整个组的"写操作"的系统调用。正常来讲,如果每一个socket都要调用"写操作",那么一个组有N个连接,就需要有N个写系统调用。为了更好的解决这个问题,我们引入了uring(当然采用libaio也可以),如图4所示。我们可以看到在每一轮中,我们可以一次性对所有组中所有socket上的写请求,进行提交。如果组中有N个连接,在每一轮我们可以减少N-1次系统调用。当然异步的写,还会引起每个socket上部分写的问题(类似图2描述的那样)。这个问题在SPDK POSIX以及uring的实现中,均已经解决。我们主要的思路是,在下一轮可以重建IO vector,然后进行在下一轮重新提交。当然我们在下一轮的写请求提交中,不仅仅是提交上一轮中每个socket未完成的写I/O,我们也会在合并在上一轮和这一轮中新产生的I/O。为此这个设计是非常高效的。

io_uring目前使用的一些问题
SPDK uring的实现完全基于io_uring,目前在满足版本需求的Linux kernel上可以正常工作。当然在SPDK uring的整个开发过程中,我们也碰到了一些问题,有些问题liburing库相关的问题,有些问题是Linux kernel中io_uring实现局限。我们把这些问题反馈给io_uring的开发者Jens,得到了非常正面的反馈,也得到了相应的支持。目前角度看来,尚且存在以下的一些问题, 诸如:
- Fixed buffer 支持。io_uring可以注册固定的缓存,使得Linux内核可以Pin住这次内存,用于提高效率。但是目前io_uring 的固定缓存的支持比较有限。比如目前支持的是:io_uring_prep_write_fixed 以及io_uring_prep_read_fixed。但是并没有支持io_uring_prep_writev_fixed以及io_uring_prep_readv_fixed。对于sendmsg以及recvmsg中的message填充的IOV似乎也没有支持fixed 的buffer。这个无疑是一个缺陷。目前这个特性的改进,估计会出现在以后的版本中。
- Control message的异步处理。目前io_uring中 io_uring_prep_sendmsg以及io_uring_prep_recvmsg对于数据通道相关的message,均可以支持异步处理。但是对于control message不能支持异步。比如在SPDK POSIX实现中的Message zero copy, 我们并不可以采用异步的recvmsg进行检查。
- IORING_SETUP_IOPOLL对于网络设备的支持。 目前创建uring的时候,这个选项仅仅可以作用于O_DIRECT模式打开的文件或者设备,才可以让用户选择在用户态自己进行轮询。显而易见,网络的描述符并不满足这个特性。
SPDK 中使能io_uring
- 升级Linux 内核,至少满足内核版本大于5.4.3. 当然越高版本的内核对于io_uring的支持越好,比如Linux kernel 版本5.7-rc1以上的特性应该丰富,诸如支持IORING_FEAT_FAST_POLL 。
- 下载和安装liburing的库:https://github.com/axboe/liburing
- 编译SPDK, 打开如下开关:./configure --with-uring 。如果liburing没有安装在系统指定的目录,需要自己指定。这样编译出的SPDK 可执行文件,会优先使用SPDK的uring socket实现,而不是POSIX。比如启动SPDK NVMe-oF tcp target, 就会采用SPDK uring 的socket实现。
总结
本文介绍了SPDK 项目中socket实现的一些现状,以及在SPDK 中我们是怎样高效利用内核的TCP/IP 栈,并在POSIX以及uring的socket 模块中实现。在我们的后续开发过程中,我们会继续不断地完善SPDK uring socket的实现。
References
[1] https://pagure.io/libaio
[2] https://en.wikipedia.org/wiki/Jens_Axboe
[3] Efficient IO with io_uring. https://kernel.dk/io_uring.pdf
[4]https://www.flashmemorysummit.com/Proceedings2019/08-07-Wednesday/20190807_SOFT-202-1_Verma.pdf
[5]https://lists.01.org/hyperkitty/list/[email protected]/thread/L7FST3E5CKUCUK4SX24IYXMDWBHH4VAA/
[6]https://review.gerrithub.io/c/spdk/spdk/+/466629
文章转载自DPDK与SPDK开源社区

Recommend
-
55
当前 Linux 对文件的操作有很多种方式,最古老的最基本就是 read 和 write 这样的原始接口,这样的接口简洁直观,但是真的是足够原始,效率什么自然不是第一要素,当然为了符合 POSIX 标准,我们需要它。一段...
-
74
Linux 5.1合入了一个新的异步IO框架和实现:io_uring,由block IO大神Jens Axboe开发。这对当前异步IO领域无疑是一个喜大普奔的消息,这意味着,Linux native aio的时代即将成为过去,io_uring的时代即将开启。 从Linux IO说起
-
27
Mental experiments with io_uring Recently, a new Linux kernel interface, called io_uring , appeared. I have been looking into it a little bit and I can’t help but wondering about i...
-
25
Last fall I was working on a library to make a safe API for driving futures on top of an an io-uring instance. Though I released bindings to liburing called iou , the fut...
-
23
Inmy previous post, I discussed the new io-uring interface for Linux, and how to create a safe API for using io-uring from Rust. In the time since that post, I have implemented a prototype of such an API. The crate is cal...
-
35
Sep 21, 2020 • 费曼 io_uring,高并发网络编程新利器 传统高性能网络编程通常是基于select, epoll, kequeue等机制实现,网络上有非常多的资料介绍基于这几种接口的编程模型,尤其是epoll,nginx, redis等都基于其构建,稳定高效,但随...
-
16
Aug 2, 2020 • 齐江 下一代异步 IO io_uring 技术解密 Alibaba Cloud Linux 2 是阿里云操作系统团队基于开源 Linux 4.19 LTS 版本打造的一款针对云应用场景的下一代 Linux OS 发行版。在首次推出一年后,阿里云操作系统团队对外正式发布...
-
11
Jun 1, 2020 • 齐江 Alibaba Cloud Linux 2 LTS 率先提供支持 io_uring Alibaba Cloud Linux 2 是阿里云操作系统团队基于开源 Linux 4.19 LTS 版本打造的一款针对云应用场景的下一代 Linux OS 发行版。在首次推出一年后,阿里云操作系统...
-
8
之前在 Facebook 上面分享不少技術文章的心得,被網友建議說可以放在 blog 上面,其實原本想在 blog 上面放一些比較長且整理過的東西,不過想想如果自己的心得能讓更多人看見,並且有機會交流也是不錯的事情,接下來應該會慢慢將之前的筆記謄過來。
-
2
Golang 中并发 IO 的现状对于 Go 这种本身便是为并发而生的语言来说,使用 io_uring 这种系统级异步接口也不是那么的迫切比如对于普通文件的读写以及 socket 的操作都会通过 netpoll 来进行优化,当文件/套接字可读可...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK