

增长黑客AB-Testing系统设计
source link: http://www.woshipm.com/pd/4171327.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
编辑导语:增长黑客这一概念起源于美国互联网行业,最早由 Sean Ellis 提出。近年来,增长黑客的概念传到国内,其核心是驱动用户飞涨增长黑客,指的是创业型团队在数据分析基础上,利用产品或技术手段来获取自发增长的运营手段。本文作者详细的分析了增长黑客的AB-Testing系统应该如何设计,希望对你有所帮助。

一、AB-test思路
数据驱动概念兴起的同时,AB-test也同步出现在大家的视线中,各互联网大厂率先引进了AB-test系统,希望通过循环的测试,上线最符合公司客群的产品。
这一理念一出引发行业内各个公司的效仿,各种宣导纷至而来,那么什么是AB-test?什么样的公司能迅速构建出AB-test系统?我们今天来一起聊一下。
1. 什么是AB-test?
携程的大佬们曾给出一个定义:AB试验可以简单的认为是传入一个实验号和用户分流ID到AB试验分流器,分流器吐出分流版本A、B、C、D等,截取一部分应用流量,落地某一段时间的分流数据,进而分析各个版本的优劣,决定启用新版本还是沿用老版本的过程。
这一定义大家能不能理解呢?我们用更通俗的语言做一下解读:
首先:试验的目的是为了决策新开发的两个或两个以上的版本该上线哪一个的问题——即当有较多的版本选择时可以先测一把,让数据告诉我们哪一个方案比较适合我们公司的客户。
大家有没有遇到经验失效的时候,就是我们按照自己的经验设计出来的产品、活动,客户并不买账,失效的原因有很多,其中一个比较常见的原因就是经验失效,即我们培养起来的经验往往是根据之前公司或者历史数据形成的。
问题在于新公司/当下时间中客群发生了变化,我们之前的经验未必完全符合现在的客群,这也就凸显出了AB-test的价值,AB-test是根据本公司现在的客群进行的对照试验,可以直观的表达出客户需要什么样的产品。
其次:试验用到的一个重要组件是分流器,分流器有什么用处呢?
顾名思义——分流用的,就是通过一定的规则将APP中随时流动的数据分成多个版本,客户进入APP后会自动分配到各个版本中,各个版本对应开发的新旧版本,进行稳定测试。
分流器中常用的方法是对客户的session/cookie进行hash运算,然后将运算结果取模mod(即取余运算,不清楚的看官可以百度一下)。通过取模后的值进行分流,分流的过程涉及正交、互斥试验的设计,其中细节,我们下文中会详细描述。
其三:就是试验效果评估的过程,AB-test的两个重点之一就是效果评估(另一个就是上面的分流器),如何评估一个试验是否成功?试验1的UV大于试验2的UV是否就说明试验1是好的?
这其中就涉及到了统计中的各种检验知识,我们会在下文原理部分详细描述。
现在我们从简到繁了解一下AB-test的试验思路,假设一个客户来到我们的APP,其在AB-test中的数据访问可以如下图描述:
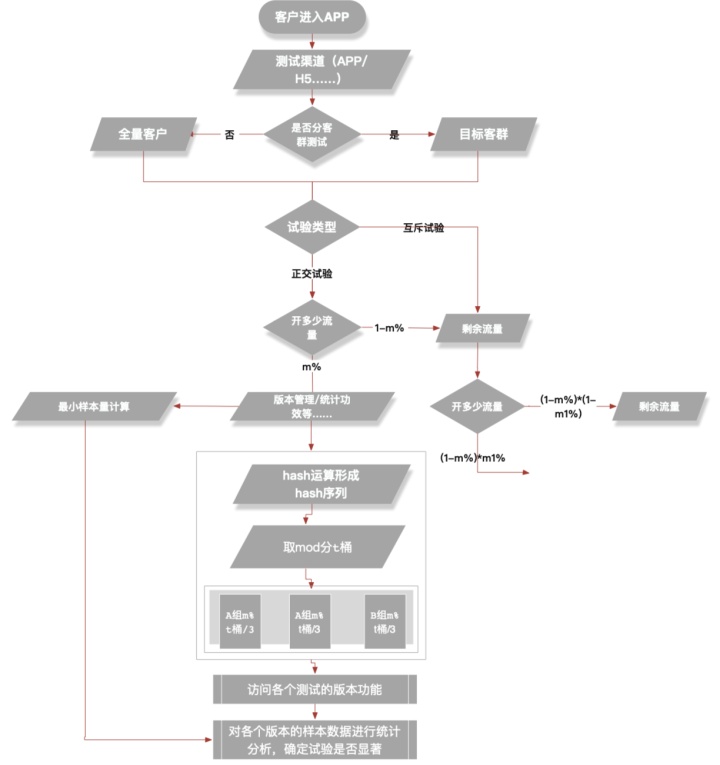
看图听故事如下:
- 一个客户进入到我们的APP时,会在客群的部分做一次筛选,即试验是否是有划分客群,如果有客群划分,则需要判断新来的客户是否命中我们的试验客群;
- 第二步我们要判断需要进行什么类型的试验,正交还是互斥?以及此次试验需要切分多少流量,5%还是10%;
- 经过了客群识别和流量切分后,我们的客户来到了试验分组部分,系统采集客户访问的cookie/session信息计算出唯一hash值,并对这一hash值做mod处理;
- mod处理之后的数据会被分到t个桶中的某一个,然后再根据一定的比例和算法将t个桶中的数据分成三组,即:A组、A组和B组,假设分流比例为:1/3,1/3,1/3;
- A-A组即为旧版本对照组,用来检验分流是否有效,如果A-A组不显著,说明数据不受系统性因子影响,分流是有效的;A-B组即为新旧版本的对照组,其中B组为新版本;
- A-A-B组的数据比较即为试验数据分析,分析人员借此完成试验的效果检验,确定试验是否显著。
看完上面这一串介绍,有没有一种原来如此的感觉?
AB-test的基本流程可以是上图的样式,但是充其量只能作为一个简图,接下来我们一点点的抽丝剥茧,还原AB-test产品的真相:
2. 什么是正交试验?什么是互斥试验?
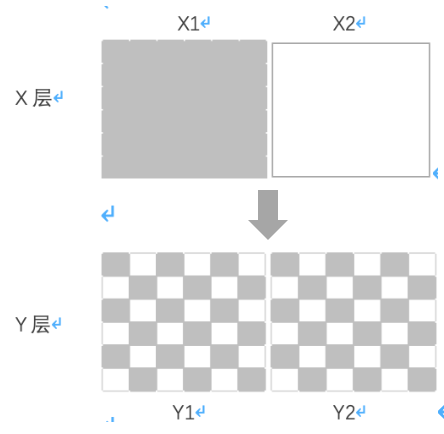
正交试验:每个独立试验为一层,为保证各层之间不相互影响,一份流量穿越每层试验时,会再次随机打散,且随机效果离散,这一过程叫正交,这样的试验叫正交试验。
正交试验能最大化的保证各层试验相互独立,确保各个试验不会相互影响。
我们用图形来表示正交,如下图:
X层的全部流量随机打散,然后进入到Y层,看到的结果即为Y层的流量为X层流量重组之后的再分配,两层之间相互独立。
互斥试验:即为在同一层中拆分流量,且不论如何拆分,不同的流量是不重叠的。
互斥试验是在流量足够的情况下进行的分流策略,各个试验之间也不会相互影响。我们同样用图形来表示互斥,如下图:
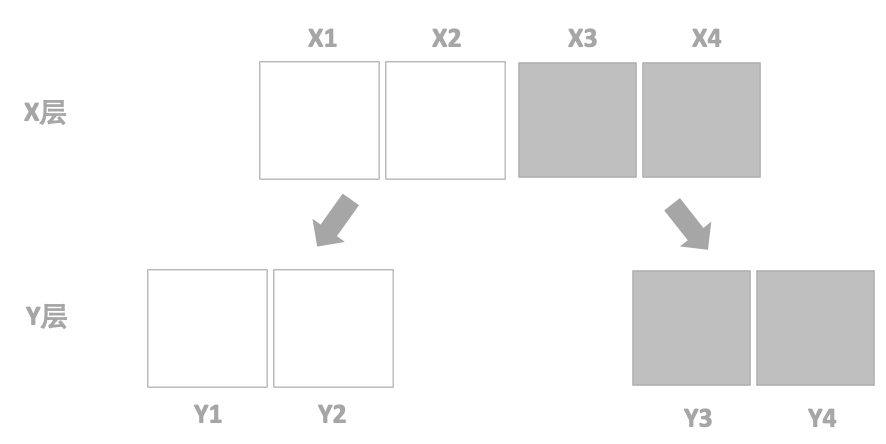
X层的流量会各自独立的分到Y层,相互之间不受影响。
3. 如何计算最小样本量?
最小样本量的计算,我们会在下文原理篇详细讲解~
4. 多个试验同时发生时如何分层?
前面我们讲解了正交和互斥两个原则,接下来我们介绍一下在正交和互斥的原则下该如何设计试验分层?
正交、互斥两种试验的引用是为了能够更充分、更高效的使用流量,实际试验中往往是多组试验同时存在,既有正交,又有互斥,如下图:
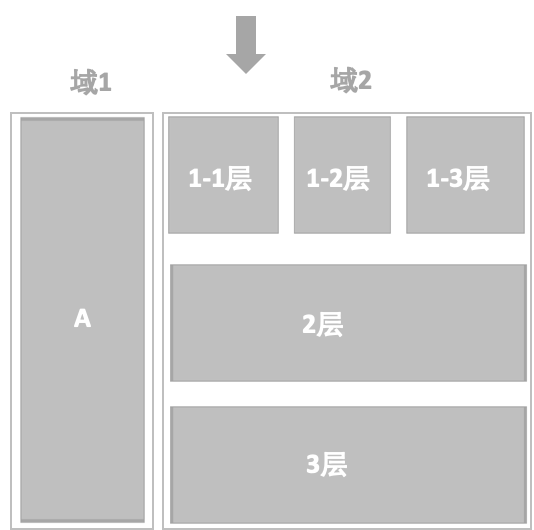
上图中的分组情况可以看出:域1和域2互斥拆分流量,域2中的流量串过1-1层、1-2层、1-3层,进入到2层和3层,1-1层、1-2层、1-3层是互斥的,1层、2层、3层是正交的,上层的流量大于等于下层。
从使用场景上看,1层、2层、3层可能分别为UI层、搜索结果层、广告结果层,这几个层级基本上没有任何的业务关联度,即使共用相同的流量,也不会对实际的业务造成影响。
但是如果不同层之间所进行的试验相互关联,就需要进行互斥试验。
例如:1-1层是修改页面按钮上文字的颜色,1-2层是修改按钮颜色,如果按钮和文字颜色一致,估计按钮就不可用了。试验的基本原则是控制变量,即尽可能的保证每次试验只有一个变量,不要让一个变量的试验动态影响另一个变量试验,否则试验就会失去公正性。
另外,如果我们觉得一个试验可能会对新老客户产生完全不同的影响,那么就应该对新客户和老客户分别展开定向试验,观察结论。
无论从层级上还是单层的分流上都被充分应用,流量的使用效率很高,但是,随着试验越来越多,对试验的管理也会显得越来越重要,往往后期会需要专门的人员进行管理。
5. Hash分流过程是啥样的?
分流的方式有很多种,笔者这次来和大家聊一下hash的算法如何实现分流效果。
AB-test又称作是桶测试,为什么叫桶测试呢?关键就在于分流的过程,我们先解释一下桶和试验组的关系:
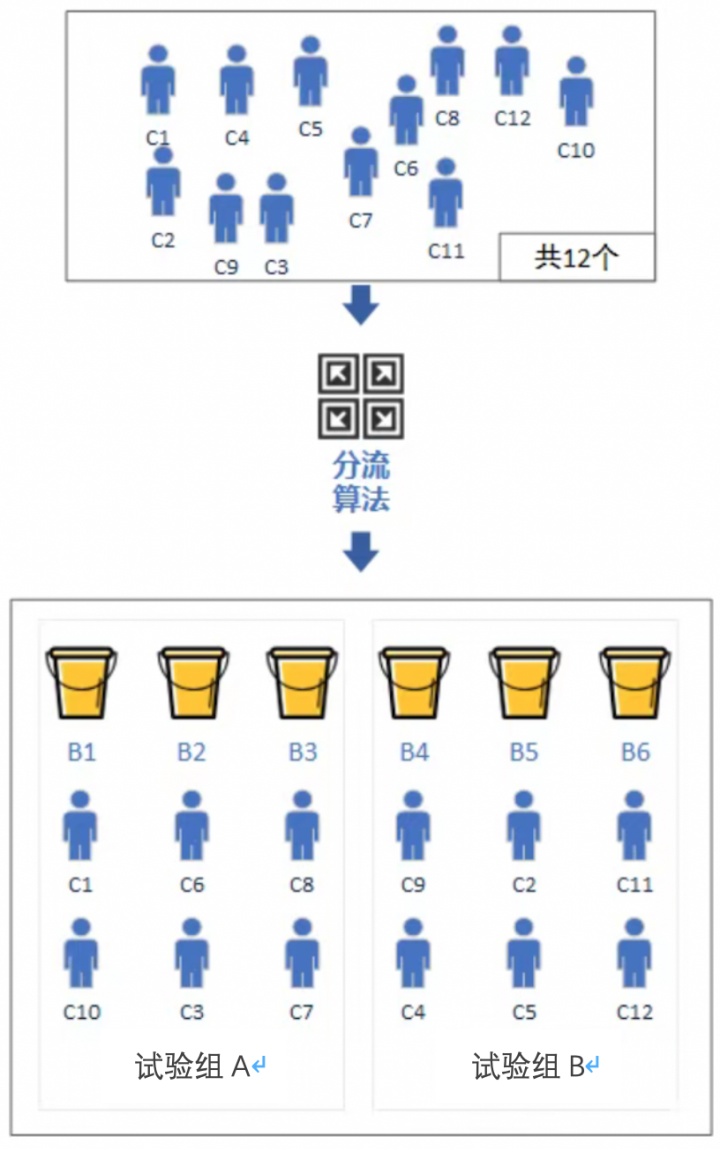
假设试验有12个人,我们对这12个人进行编号,编号方法可以使用cookie,也可以使用session,总之获取到这12个人的唯一编码。
当获取到唯一编码之后我们就可以开始分流了,我们对每个人的唯一编码进行hash处理,常规使用MD5进行hash计算,这样计算的好处在于MD5几乎不会重复,分流效果较好。
计算好的hash值需要进行mod处理,图中有6个桶,我们就用6进行mod处理, 12个人按照余数分散到六个桶里面,原则上12个人的分流是随机的分散到各个桶里面,很难保证每个桶里的人数一致。
但是从统计学的角度上讲,当数据量足够大时,数据会均匀的分散到各个桶里面。
桶分流完成后,我们需要处理的就是将这些桶平均分成两组,原则是保证随机性和平均分配,聪明如你,应该已经明白分流的原理了吧?
6. Hash分流是否能保证样本在A-A-B三组中平衡分布?
三组数据的分流原则上需要尽可能平衡,即各个特征都能均匀的分布在三组试验中,这样才能符合AB-test控制变量的原则。
生化试验中控制变量是一个较为简单的问题,不管是脊蛙反射还是肠胃蠕动试验;但是社会学中的试验,控制变量却异常复杂,因为面对大量人群,很难通过随机分配保证各个特征的平衡,而且有些隐含变量很难被发现,也难以做到平衡。
这样的问题称在生化试验中称作是系统误差,在互联网AB-test中则会引发辛普森悖论。
生化试验中往往通过重复试验来避免,互联网下的AB-test很难进行重复试验,因为无法让一个人即使用A版本,又使用B版本,串行试验又会添加时间因素,所以只能采用其他的方式解决这个问题。
那么,什么是辛普森悖论呢?
我们用一个真实的医学 AB 测试案例来说明这个问题,这是一个肾结石手术疗法的 AB 测试结果:
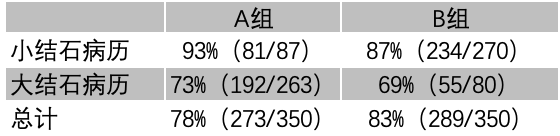
看上去无论是对于大型结石还是小型结石,A疗法都比B疗法的疗效好。但是总计而言,似乎B疗法比A疗法要好。
这个AB测试的结论是有巨大问题的,无论是从细分结果看,还是从总计结果看,都无法真正判断哪个疗法好。
那么,问题出在哪里呢?
这个AB测试的两个实验组的病历选取有问题,都不具有足够的代表性。
参与试验的医生人为的制造了两个试验组本身不相似,因为医生似乎觉得病情较重的患者更适合A疗法,病情较轻的患者更适合B疗法。所以下意识的在随机分配患者的时候,让A组里面大结石病历要多,而B组里面小结石病历要多。
更重要的问题是:很有可能影响患者康复率的最重要因素并不是疗法的选择,而是病情的轻重!换句话说,A疗法之所以看上去不如B疗法,主要是因为A组病人里重病患者多,并不是因为A组病人采用A疗法。
所以,这一组不成功的AB测试,问题出在试验流量分割的不科学,主要是因为流量分割忽略了一个重要的“隐藏因素”,也就是病情轻重。
正确的试验实施方案里,两组试验患者里,重病患者(也就是AB-test中的特征值)的比例应该保持一致。
我们再来聊一个互联网领域的场景:我们对APP上一个按钮进行了颜色调整,需要比较一下颜色调整前后用户UV点击率是否提高?
经过一段时间的试验,我们得到了两组试验的数据,为了说明辛普森悖论的问题,我们单独抽离出了性别作为比较。
原因有二:一是性别在这次试验中是重要特征;二是这一特征的数据不均衡,刚好出现了辛普森问题。计算出了两组试验的点击率,如下:
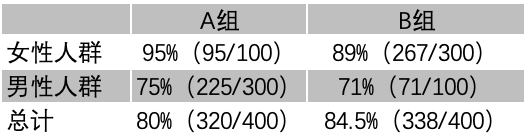
数据中我们发现:单独看这一试验,无论是女性特征和男性特征,数据表现都是A组中较好。但是,总计却是B组效果较好,其中的差异我想大家已经清楚了,性别特征并没有均衡的分布在两个试验组中。
这个解决方法就是——定向试验。
在进行试验之前,先做一次试验分析,确定对试验影响较大的因素,然后通过分流的权重设置来均衡各个组之间的特征差异,因素确认用到的方法较多,比如GBDT等等。
如下图:

在进行试验同时,可以实现各分组特征中的监控。如果发现某一特征在某一组中偏小,就增加这一特征在这一组的分配权重,以保证特征一致性。
但是这样也存在特征取舍的问题,具体就不展开来描述了,有兴趣的小伙伴可以自行查询一下。毕竟,能做到这一点的公司已经很不错了。
分层试验,交叉试验,定向试验是我们规避辛普森悖论的有力工具。
规避辛普森悖论,还要注意流量动态调整变化的时候新旧试验参与者的数据问题,试验组和对照组用户数量的差异问题,以及其他各种问题。
而优秀的增长黑客,不会去投机取巧“制造数据”,而是认真思考和试验,用科学可信的数据来指导自己和企业的决策,通过无数次失败的和成功的AB测试试验,总结经验教训,变身能力超强的超级英雄。
二、AB-testing原理
统计计算主要应用在效果评估领域。
客户经过分流之后在各个试验组中产生数据,统计的作用即为查看对应组的样本量是否达到最小样本量,数据之间是否存在显著性差异,以及进行差异大小的比较。
如下图:
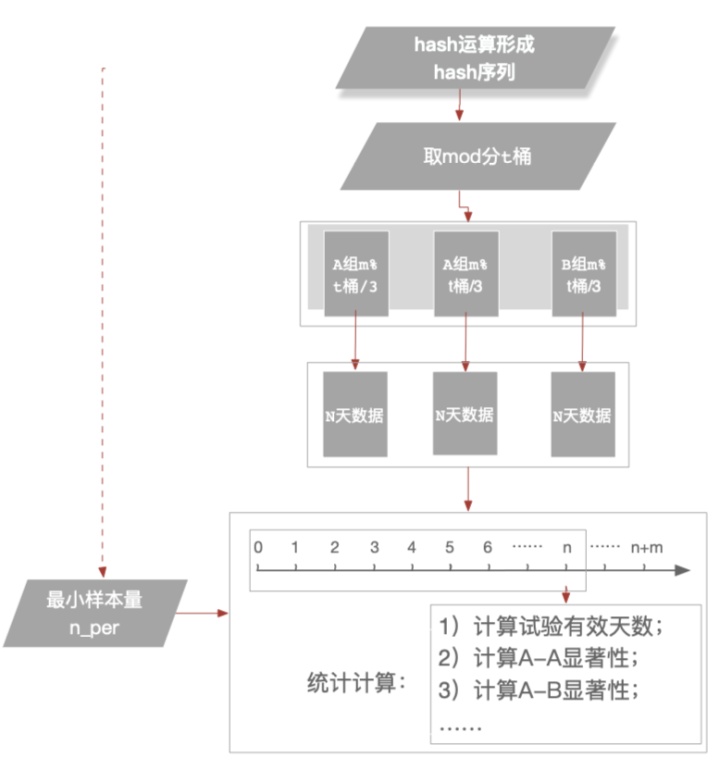
A-A-B三组数据观察n天后,会产生3组数据,我们接下来的任务就是计算这三组数据的统计效果,进而确定哪个方案效果好。
1. 如何计算最小样本量?
最小样本量是按照统计功效进行计算的,主要分两类:绝对值类(例如:UV)和比率类(例如:点击率)。
在试验过程中,大部分场景是进行比率类指标的比较,单纯的计算绝对值是没有价值的;而且对于试验效果来讲,绝对值的比较可以转化为比率的比较。
所以在计算过程中,我们统一成比率计算,以方便口径统一和数值比较。
理论上,比率类最小样本量计算:
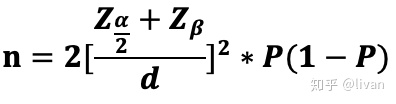

例如:“XX提交”按钮由红色变为橙色,统计的指标是点击UV转化率UV_rate,测试时间是20200801~20200814,则计算“XX提交”按钮的历史月均值mean(UV_rate)为下面数据的均值avg(UV_rate):


注:此处的计算需要对统计学中的统计功效有所了解,阅读有阻力可以补充一下“统计功效”的计算方法。
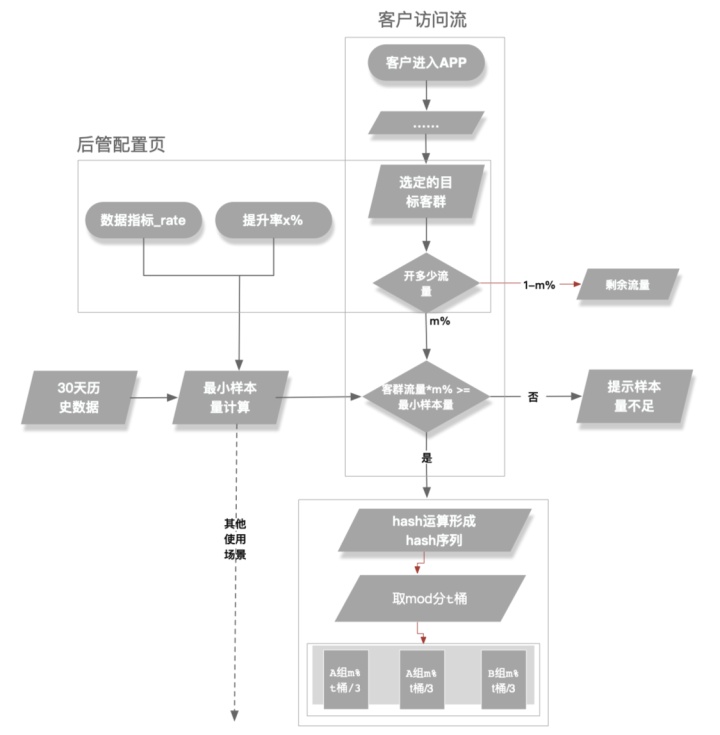
流程图介绍:最小样本量的作用是确定试验是否有效,后管配置好对应的客群信息、开放流量占比、提升率等信息后,后台需要进行“最小样本量”的计算,并进行相关判断,如下图:

2. 如何计算试验有效天数?
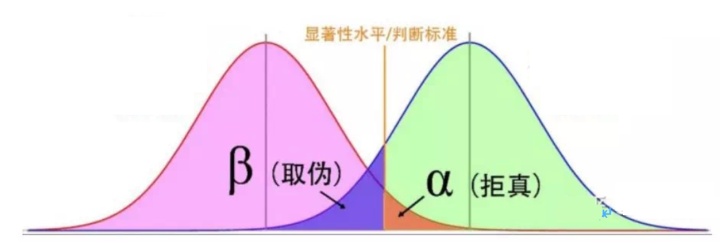
补充——统计功效:
确定好最小样本量并实现分流、试验上线之后,需要进行数据的有效天数需要进行相应计算:
试验的有效天数即为试验进行多少天能达到流量的最小样本量。
当流量达到最小样本量时,查看数据是否存在显著性差异,如果不存在显著性差异则继续进行试验,直到达到最大要求天数;如果试验仍然没有达到显著性,则确定两组试验不显著,即没有明显差异。
计算过程如图:
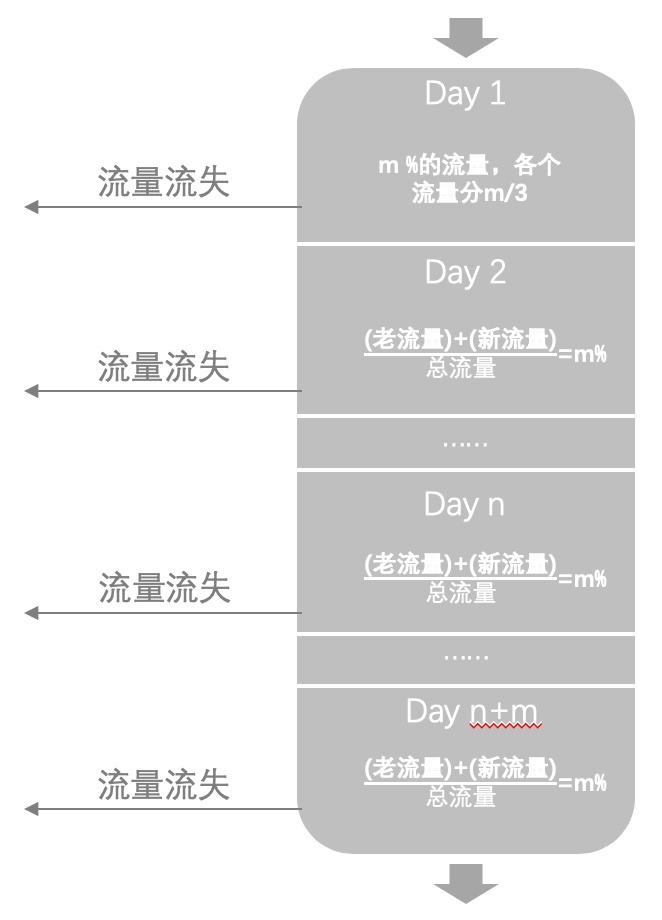
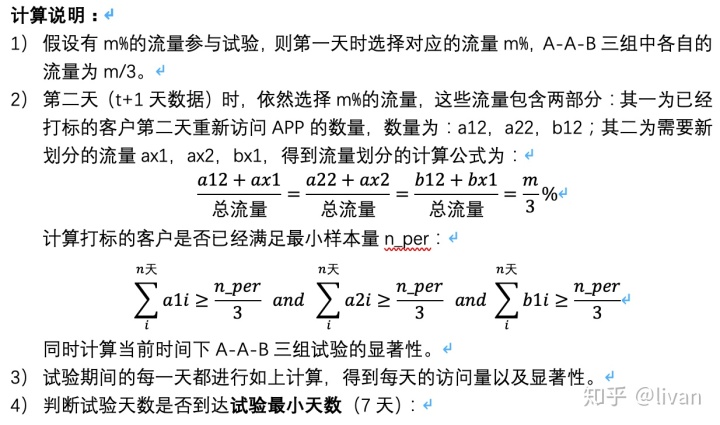
如果到达试验最小天数且试验样本量>=最小样本量n_per,则观察试验是否有显著性,如果A-A试验没有显著性且A-B存在显著性(B>A),则表示试验成功,否则试验失败。
如果到达试验最小天数且试验样本量<最小样本量n_per,则继续进行试验;
3. 判断试验天数是否到达试验最大天数(t天):
如果到达试验最大天数且试验样本量>=最小样本量n_per,则观察显著性;如果到达试验最大天数且试验样本量<最小样本量n_per,则终止试验并标注试验失败。
逻辑流程图为:
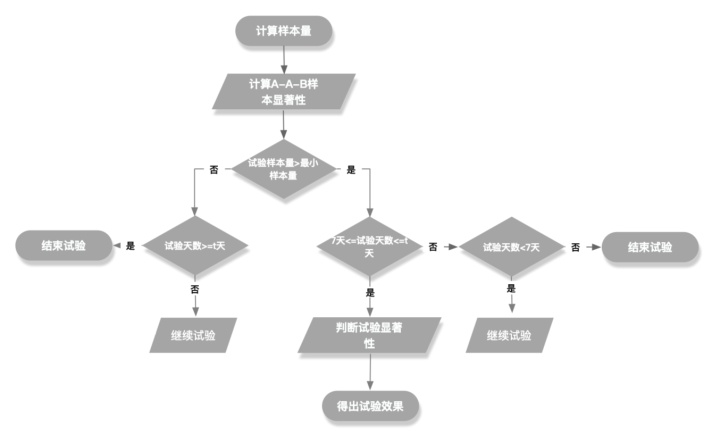
通过每天的数据计算可以做出如上判断,进而确定试验进行的有效天数并计算出显著性水平。
三、AB-testing工程化
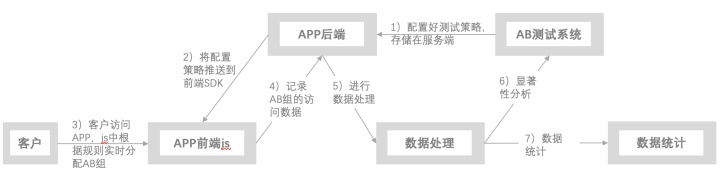
经过上面的描述,我们可以通过下面的两张图来了解一下在工程方面,AB测试系统是什么样子的:
注释:
- 根据需求设计好AB试验之后,在AB测试系统配置好对应的策略;
- 将这一策略固化成文件,并推送到APP的AB系统SDK中;
- 客户每次访问APP,先扫描AB系统SDK中的策略文件,根据策略文件给客户打标,分配对应的A、B版本;
- APP中根据策略呈现A、B版本的试验内容,并监控客户的操作行为以及订单行为;
- 这一行为被记录并上报到大数据环境中;
- 天在大数据中进行显著性计算和最小样本量的处理,得到对应的显著性结果。
我们再来看一个详细的系统数据,如下图:
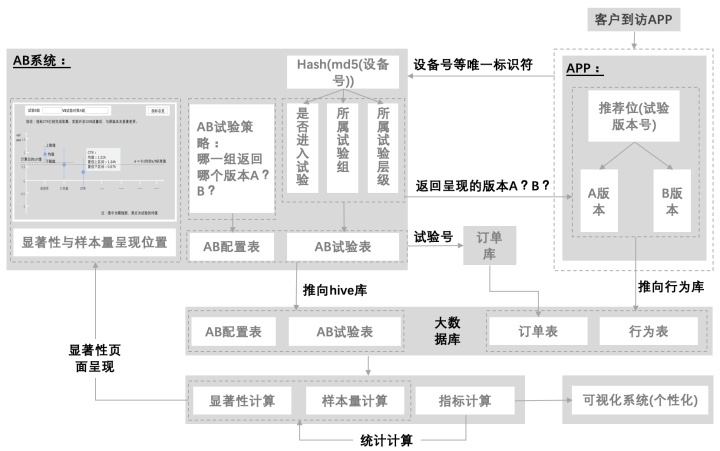
目前为止,AB系统已经介绍完成了,AB的结构深不可测,其中也需要经常的更新和讨论,欢迎大家关注沟通~
作者:野水晶体;个人公众号:livandata
本文由 @野水晶体 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 Pexels,基于 CC0 协议
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK