

Raft 算法之领导人选举
source link: https://qeesung.github.io/2020/04/14/Raft-%E7%AE%97%E6%B3%95%E4%B9%8B%E9%A2%86%E5%AF%BC%E4%BA%BA%E9%80%89%E4%B8%BE.html?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Raft 算法之领导人选举
Raft 论文地址:https://ramcloud.atlassian.net/wiki/download/attachments/6586375/raft.pdf
Raft论文中分为三块:
本文中主要介绍领导人选举
Raft中的节点状态
Raft中的节点有三种状态:
- 领导人状态:
Leader - 跟随者状态:
Follower - 候选人状态:
Candidate
每一个节点都是一个状态机,Raft会根据当前的心跳,任期等状态来进行状态的迁移转化,就如下图所示:
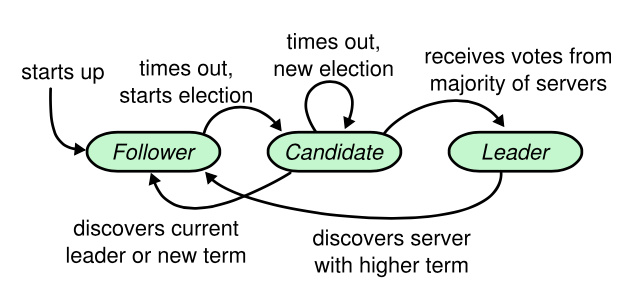
首先,在Raft节点启动的时候,所有任务都是Follower状态, 因为此时没有Leader,所有Follower都在固定的超时时间内都收不到来自Leader的心跳,从而变成了Candidate状态,开始选举Leader
当节点处于Candidate状态的时候,会并发的向所有的节点发出请求投票请求RequestVote(后面章节会向详细介绍),在Candidate状态下,节点可能会发生三种状态的迁移变化:
- 开始下一轮新的选举:发出的投票请求在固定时间内没有收到其他节点的响应,或者是收到响应(或者同意投票)的节点数量没有达到
N/2+1,那么选取超时,进入下一轮选举 - 选举成功,成为新的
Leader:如果选举过程中收到大于N/2+1数量的节点的投票,那么选举成功,当前的节点成为新的Leader - 成为
Follower:如果选举过程中收到来及其他节点的Leader心跳,或者是请求投票响应的Term大于当前的节点Term,那么说明有新任期的Leader
如果节点选举成功,成为了Leader,那么Leader将会在固定周期内发送心跳到所有的节点,但是如果心跳请求收到的响应的Term大于当前节点的Term,那么当前节点的就会成为Follower。比如Leader节点的网络不稳定,掉线了一段时间,网络恢复的时候,肯定有其他节点被选为了新的Leader,但是当前节点在掉线的时候并没有发现其他节点选为Leader,仍然发送心跳给其他节点,其他节点就会把当前的新的Term响应给已经过时的Leader,从而转变成Follower
领导人选举
整个集群必须要在丢包,乱序,延时等诸多不稳定因素的情况下,能够选举出唯一一个Leader
请求投票RPC
就如上文中提到的,如果Follower在一定时间内没有收到心跳请求,那么将会切换到Candidate状态,开始一轮新的选取,选举过程中会向集群中的所有节点发送请求投票的RPC
RPC请求参数:
term:当前候选人的任期号candidateId:候选人的IdlastLogIndex:候选人的最后日志条目索引值lastLogTerm:候选人的最后日志条目的任期号
其中lastLogIndex和lastLogTerm用来判断候选人的日志是否和服务器的日志一样新(后文中会解释),必须要至少一样新才能投票。
RPC响应值:
term:被请求节点的任期号voteGranted:是否同意投票给候选人
Candidate发送请求投票RPC
Candidate何时发送请求投票RPC?
如果Leader发生异常,那么基本上所有的Follower在同一时间切换为Candidate,并同时发出请求投票的RPC,那么就有可能导致选票被均衡的瓜分,从而需要重新发起新一轮的投票。为了避免选票被瓜分的问题,选举超时的是可以可以从一个固定的区间(例如150-300毫秒)随机选择。
Candidate如何发送投票RPC?
- 自增当前节点的任期号
- 给自己投票
- 重置选举超时计时器
- 发送请求投票的RPC给其他服务器
节点收到请求投票的RPC该如何处理?
- 判断当前的
Term的和请求投票参数中的Term:- 如果当前的
Term> 请求投票参数中的Term,那么拒绝投票(设置voteGranted为false),并返回当前的Term - 否则就更新当前
Term为请求投票参数中的Term, 并将自身状态切换成Follower
- 如果当前的
- 检测当前节点的投票状态:
- 如果当前的节点没有给任何其他节点投过票,或者是已经投过票给当前节点,那么继续检测日志的匹配状态(步骤3)
- 否则,那么拒绝投票(设置
voteGranted为false), 因为一个节点在一个任期内不能同时投票给多个节点
- 检测候选人的日志是否至少比当前节点的日志新,通过比较候选人的
lastLogIndex和lastLogTerm和当前节点的日志,确保新选举出来的Leader不会丢失已经提交的日志:- 如果日志匹配,即当前的任期和候选人的任期相同,且候选人的日志长度比当前的日志长度 或者 候选人的任期比比当前节点的任期高,那么就为候选人投票(设置
votedGranted为true),并成为Follower - 否则,那么就拒绝投票(设置
voteGranted为false)
- 如果日志匹配,即当前的任期和候选人的任期相同,且候选人的日志长度比当前的日志长度 或者 候选人的任期比比当前节点的任期高,那么就为候选人投票(设置
Candidate收到请求投票的响应该如何处理?
每一个候选人在每一个任期内都会发出一轮投票请求,如果在指定时间内,收到大于N/2+1个节点的同意投票的响应,那么说明投票成功,晋升为Leader
因为在整个投票过程中,假设网络是不稳定的,那么就有可能导致投票请求和请求的响应丢失,乱序,延时等,从而导致收到和当前任期不相匹配的响应,所以如果收到和当前任期不匹配的响应,那么就直接丢弃不处理。
完整的处理流程如下:
- 检查响应的
Term是否大于当前候选人的Term:- 如果是,那么说明有其他节点开始了新一轮的选举或者是有新的
Leader被选举出来,那么就把当前节点从Candidate切换为Follower状态,并更新当前节点的Term - 否则,进行步骤2
- 如果是,那么说明有其他节点开始了新一轮的选举或者是有新的
- 检查响应的
Term是否和当前的节点的Term是否相等:- 如果相等,那么说明在指定时间内收到了投票请求的响应,那么就进行步骤3
- 否则说明这是一个过期的投票请求响应,直接丢弃
- 检查响应是否同意投票:
- 如果同意,那么增加当前任期的同意投票节点数量,并检查同意投票的节点数量大于
N/2+1,那么就切换为Leader - 如果不同意,可能是日志不匹配,因为
Leader的日志至少要比Follower的日志新
- 如果同意,那么增加当前任期的同意投票节点数量,并检查同意投票的节点数量大于
领导人选举的安全性
从上文的请求投票RPC的处理流程中得知,Leader不是随便选一个节点都可以成为的,如果候选人不满足要求,那么其他节点就不会给候选人投票。
如果集群中的任何一个节点不经过判断就能成为Leader,那么将会发生什么?这种情况可能导致已经被提交的日志被覆盖,如果状态机已经Apply了被覆盖的日志,将会导致不一致的结果。所以为了选举的安全性,Raft添加了以下的限制:
Leader不会覆盖自己的任何日志,Follower严格按照Leader的日志进行复制(必要时强行覆盖)- 选举
Leader的时候,Candidate的日志至少要比当前节点新(这个“新”稍后解释),否则就拒绝投票;因为已经提交的日志肯定是存在大于等于N/2+1个节点上的,而投票至少也需要N/2+1个节点同意,所以整个投票过程中肯定会有包含有所有已经提交日志的节点存在的。
上文中的“新”就是:即当前的任期和候选人的任期相同,且候选人的日志长度比当前的日志长度 或者 候选人的任期比比当前节点的任期高
follow me on github ~=[,,_,,]:3
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK