

Automaton(二)
source link: https://www.amazingkoala.com.cn/Lucene/gongjulei/2020/0727/157.html?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Automaton(二)(Lucene 8.4.0)
在文章Automaton中我们介绍了确定型有穷自动机(Deterministic Finite Automaton)的概念,以及在TermRangeQuery中如何根据查询条件生成一个转移图,本文依旧根据该文章中的例子,介绍在Lucene中如何构建DFA,即生成图2的转移图,以及存储状态(state)、转移(transition)函数的数据结构。
我们再次给出文章Automaton中的例子:
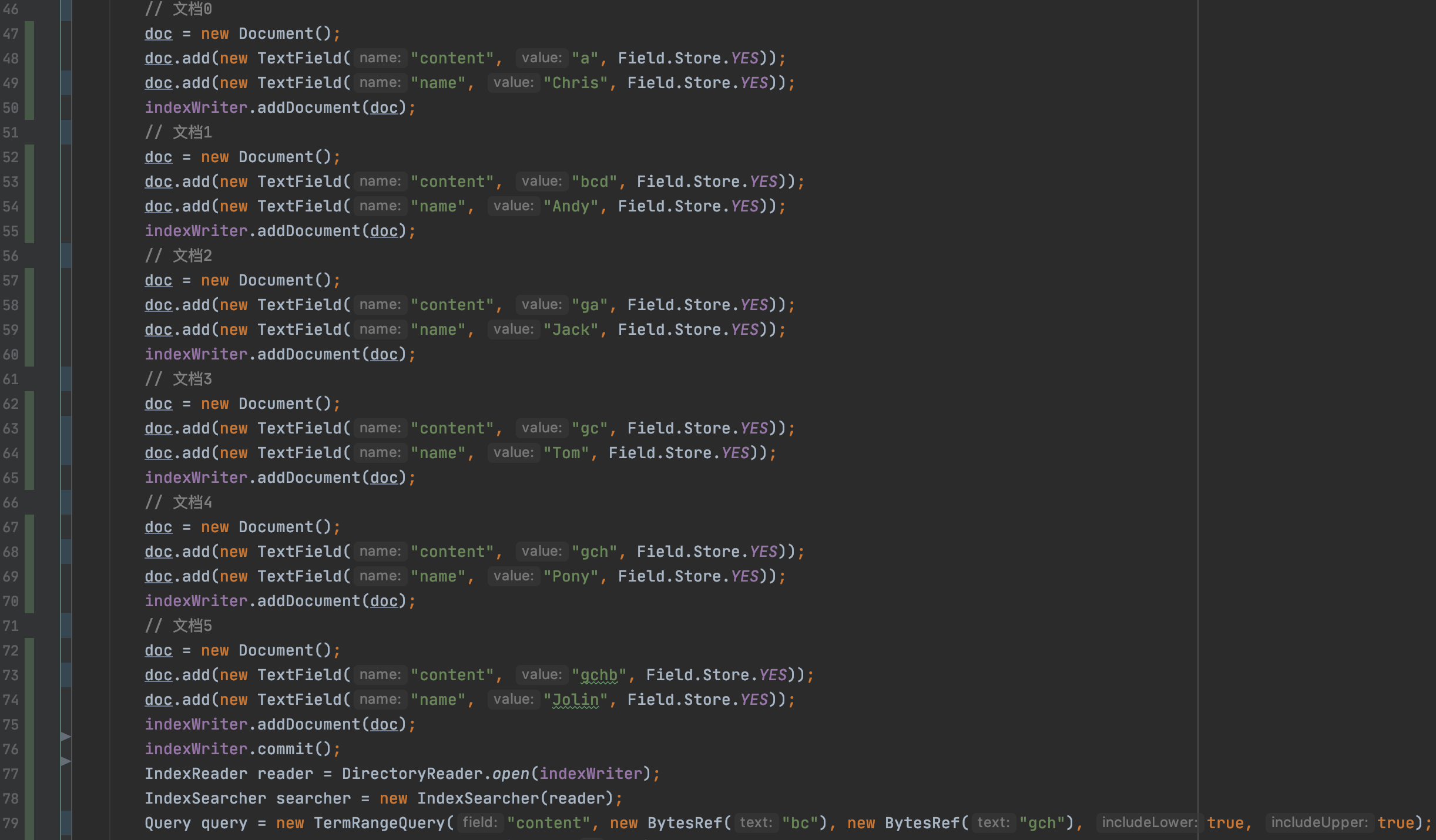
图1的第79行代码描述了TermRangQuery的查询范围为["bc","gch"],下文中会用minValue来描述下界"bc"、maxValue来描述上界"gch",根据minValue、maxValue构建的DFA如下所示:
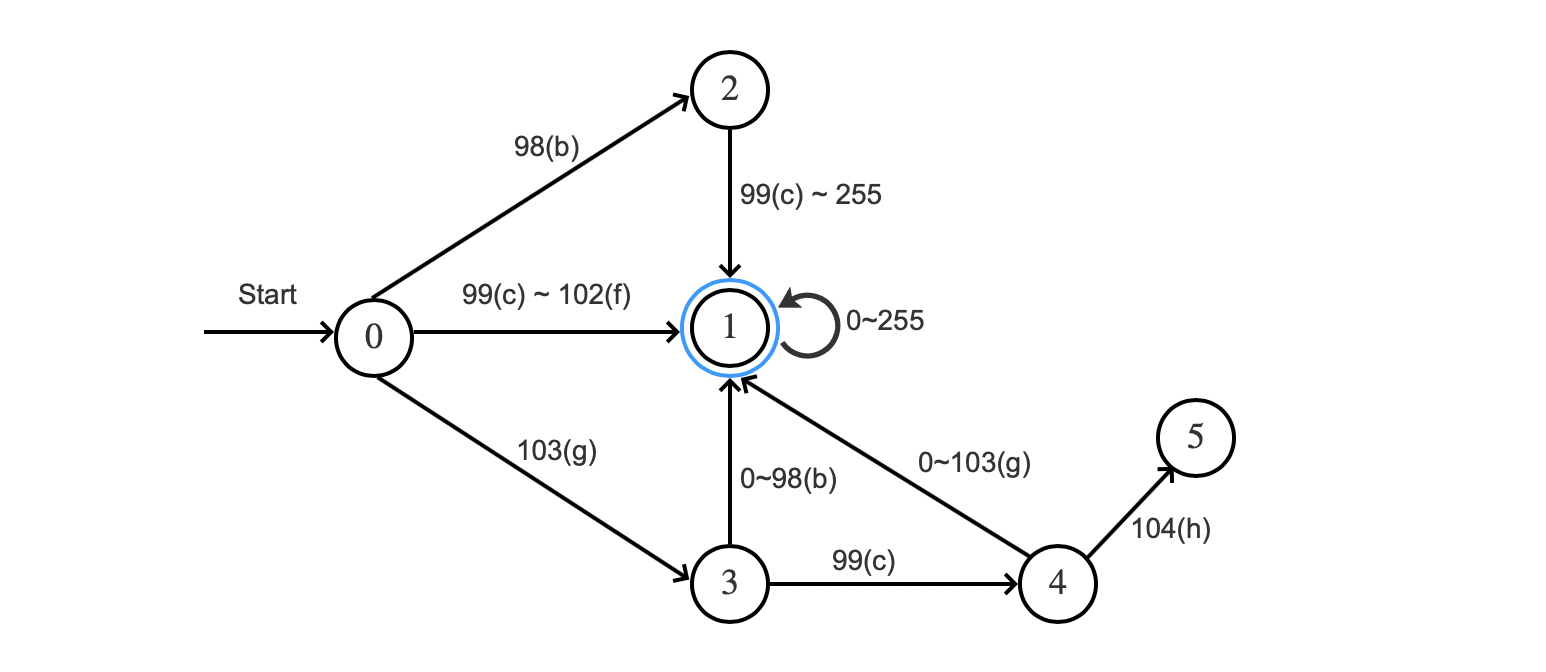
图2中,接受语言L完整描述是 A = ({0,1,2,3,4,5}, {0,… ,255}, ,0,{1,3,4,5}):
- {0,1,2,3,4,5}:描述的是有穷的状态(State)集合,即有0~5共6个状态
- {0,… ,255}:描述的是有穷的输入符号集合,即输入的符号是256种ASCII码
- :描述的是转移函数,Lucene中用两个int类型的数组transitions、states描述,下文会展开介绍
- 0:描述的是初始状态,即状态0
- {1,3,4,5}:描述的是可接受状态或终结状态
上述内容如果没看明白请先阅读文章Automaton。
构建DFA的流程图
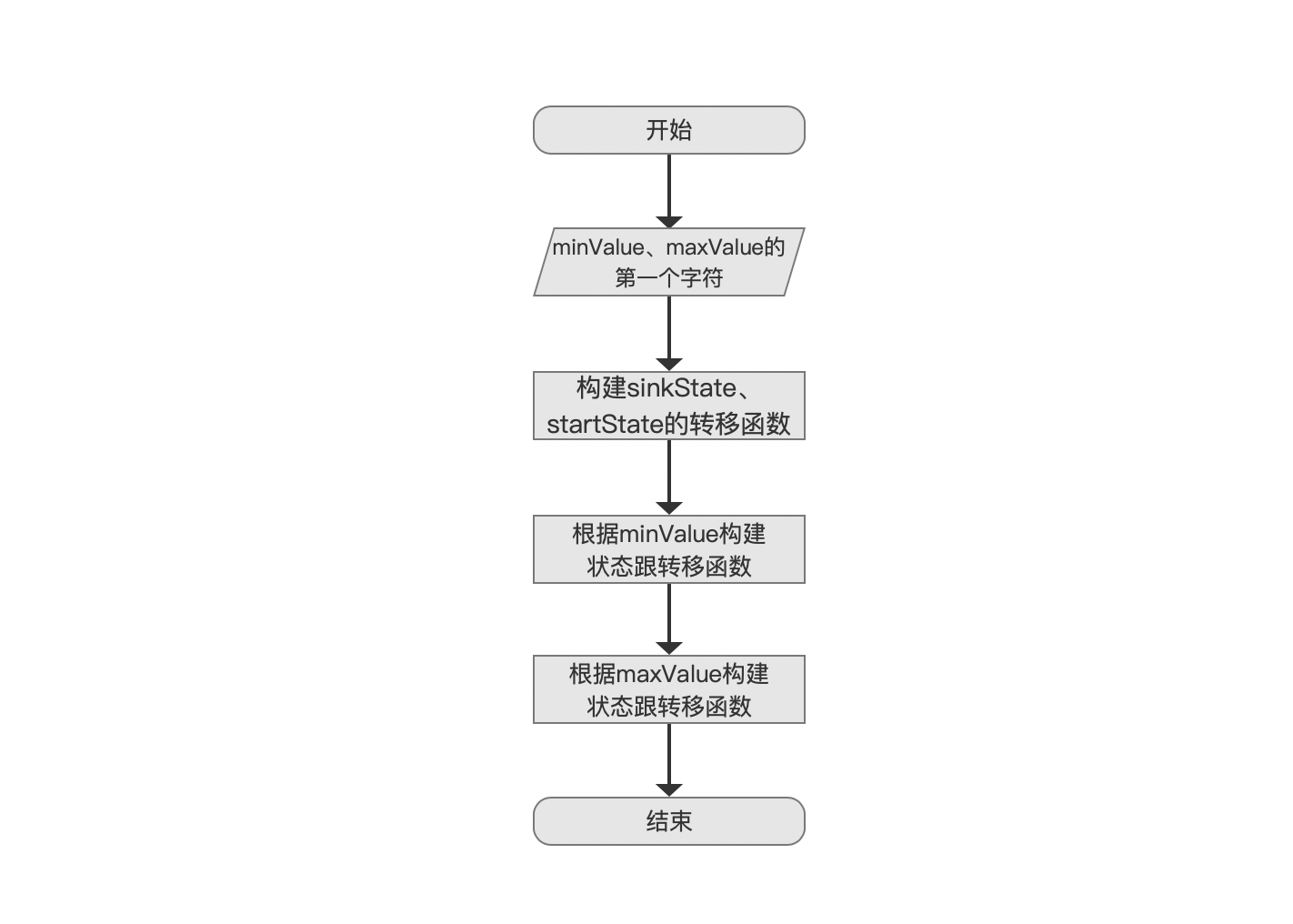
为了便于介绍Lucene中构建DFA的流程,图3中描述的流程是根据图1的例子给出的,即一个特例DFA的构建过程,实际的构建流程基于边界问题(例如maxValue的值为null、minValue的值跟maxValue是相等),非确定性(non-deterministic)自动机等一些条件会导致相当复杂的分支流程,故无法一一列出,不过在掌握了图3的流程实现后,再根据源码来了解全面的构建流程就变得十分简单了。
在介绍图3的流程之前,我们先介绍下Lucene是如何描述(存储)转移函数的。
Lucene通过两个int类型的数组transitions、states来描述转移函数:
transitions数组:数组中使用固定的连续的三个数组元素来描述一个转移函数的三个信息
- 目标状态dest,描述的是当前状态转移到下一个状态,该状态即目标状态dest
- 输入符号的最小值min,描述的是当前转移可接受的最小输入符号
- 输入符号的最大值max,描述的是当前转移可接受的最大输入符号
states数组:数组中使用固定的连续的两个数组元素来描述当前状态的两个信息
- 第一个信息:当前状态的第一个转移函数信息在transitions数组中的起始位置
- 第二个信息:当前状态的转移函数的数量
我们以状态0为例,由图2可知,它包含了三个转移函数,如下所示:
上述公式是如何得出见文章Automaton中的介绍,该公式的转移函数信息用transitions、states数组存储如下所示:
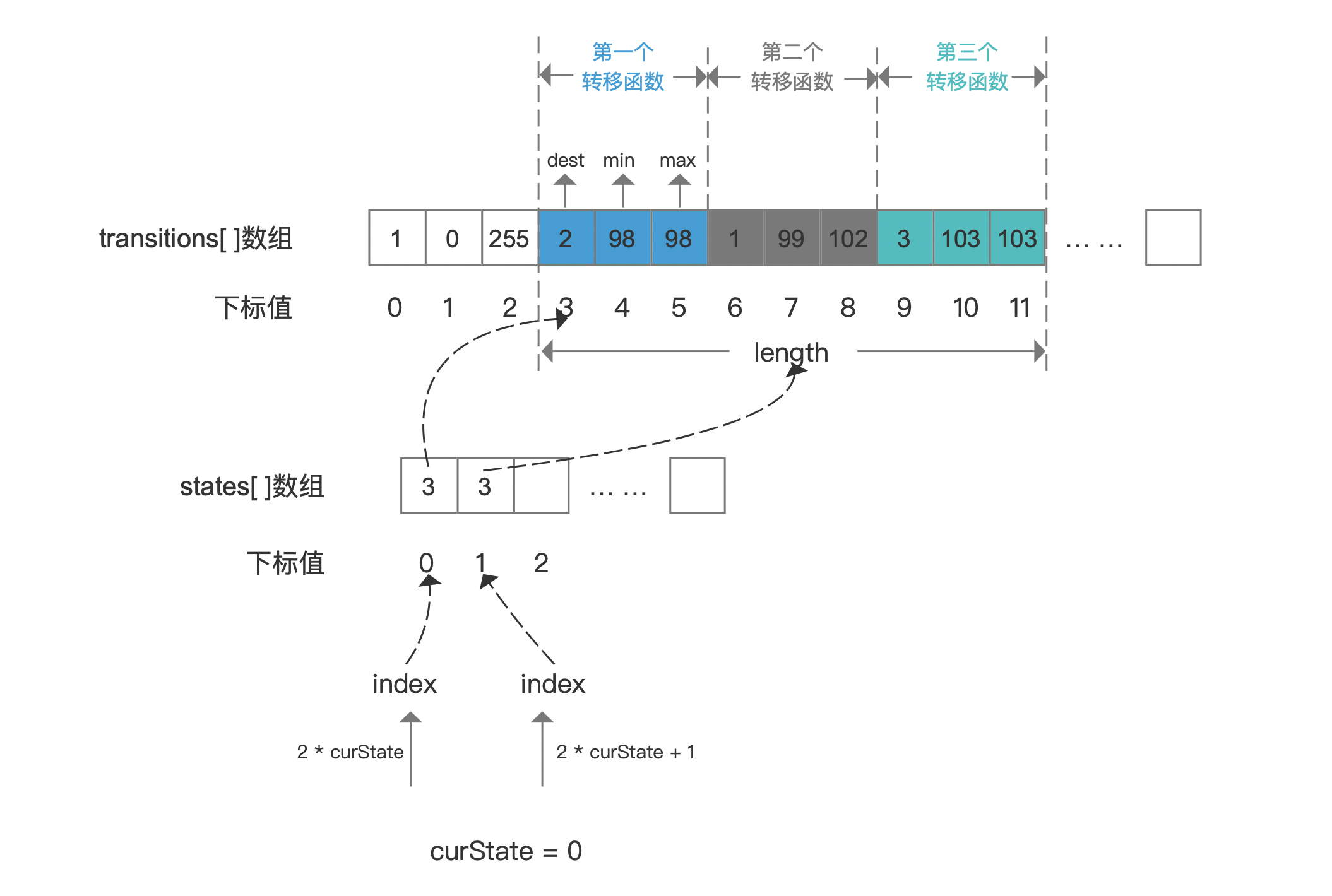
图4中,状态0的状态值为0,即curState = 0,根据公式 跟分别获得states[ ]数组的两个下标值,这两个下标值对应的数组元素分别描述了状态0的第一个转移函数信息在transitions数组中的起始位置,以及状态0的转移函数的数量,由于transitions数组中用固定数量的数组元素描述一个转移函数的信息,故length的值为 ;对于状态0的第一个转移函数,dest描述了转移到下一个状态的状态值,即状态2,并且接受最小值min为98(ASCII码,对应字符"b")、最大值max为98的输入符号,也就说状态0到状态2的转移只接受字符"b"。
另外状态0的三个转移函数是根据min值进行排序的,其目的是在读取阶段能更快的判断term是否在查询条件范围内,具体过程在介绍TermRangeQuery时再展开。
构建sinkState、startState的转移函数
sinkState为可接受状态,即图1中的状态1,由于我们处理的term是ASCII码,所以该状态可接受的输入符号为0~255,即所有的ASCII码,startState为初始化状态,即图1中的状态0,由于查询条件的上下界minValue、maxValue分别为"bc"、"gch",根据这两个值的第一个字符"b"、"g",那么我们需要创建三个转移函数:
- 第一个转移函数:只接受"b"的输入字符
- 第二个转移函数:接受"c" ~ "f"范围的输入字符
- 第三个转移函数:只接受"g"的输入字符
这两个状态构建后,transitions、states数组如下所示:
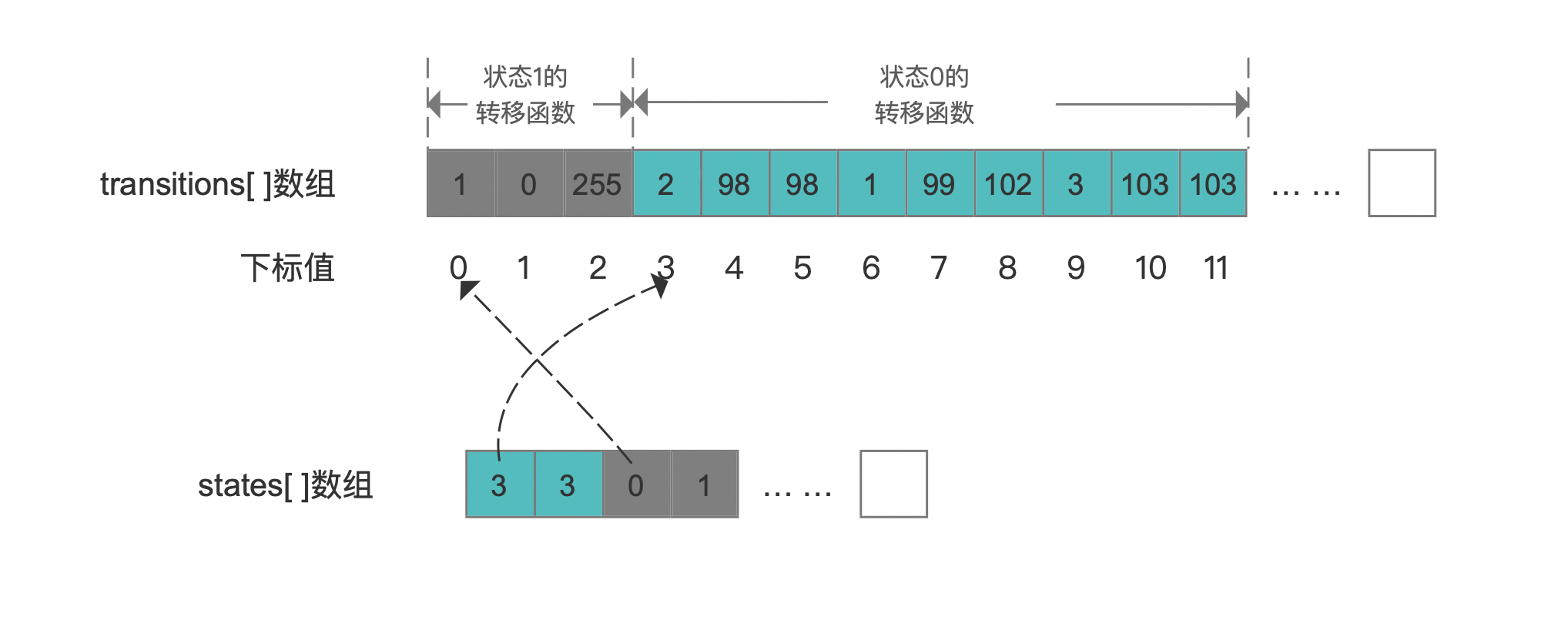
图6中状态1的下一个转移为自己本身,并且min跟max分别为0、255,即所有的ASCii,意味着随后的输入符号都能被接受。
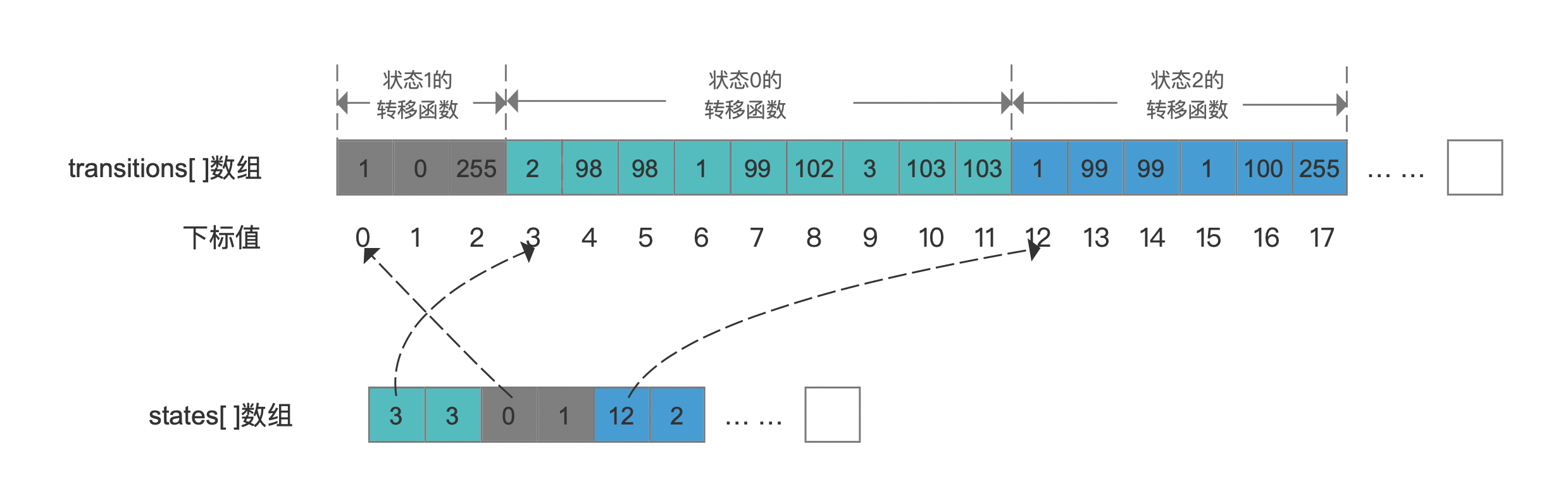
根据minValue构建状态跟转移函数

由于在图5的流程中,minValue的第一个字符已经作为输入符号,并且构建了状态2,故只剩下输入符号"c"待处理,那么此时需要构建状态2的两个转移函数:
- 第一个转移函数:只接受"c"的输入字符
- 第二个转移函数:接受"d" ~ 255(ASCII码表示)
这两个状态构建后,transitions、states数组如下所示:
对于状态2的转移函数,由于他们的目标状态都是状态1,那么可以尝试合并转移函数,可见如果合并后仍然是一个连续的输入符号区间,那么就可以合并,故在合并后,transitions、states数组如下所示:
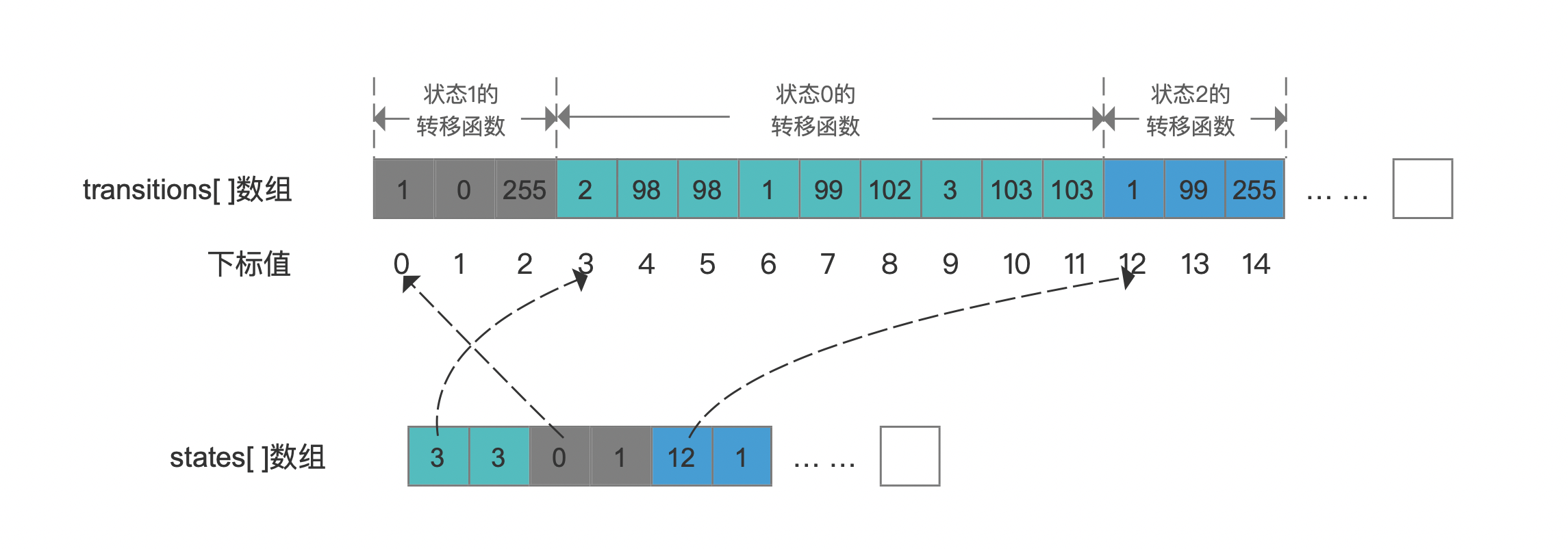
详细的合并逻辑见 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-8.4.0/lucene/core/src/java/org/apache/lucene/util/automaton/Automaton.java 中的finishCurrentState()方法。
根据maxValue构建状态跟转移函数

由于在图5的流程中,maxValue的第一个字符"g"已经作为输入符号,并且构建了状态3,故只剩下输入字符"c"、"h",他们将分别构建状态4、5以及对应的转移函数,逻辑跟上文是类似的,故不赘述,直接给出最终的transitions、states数组:
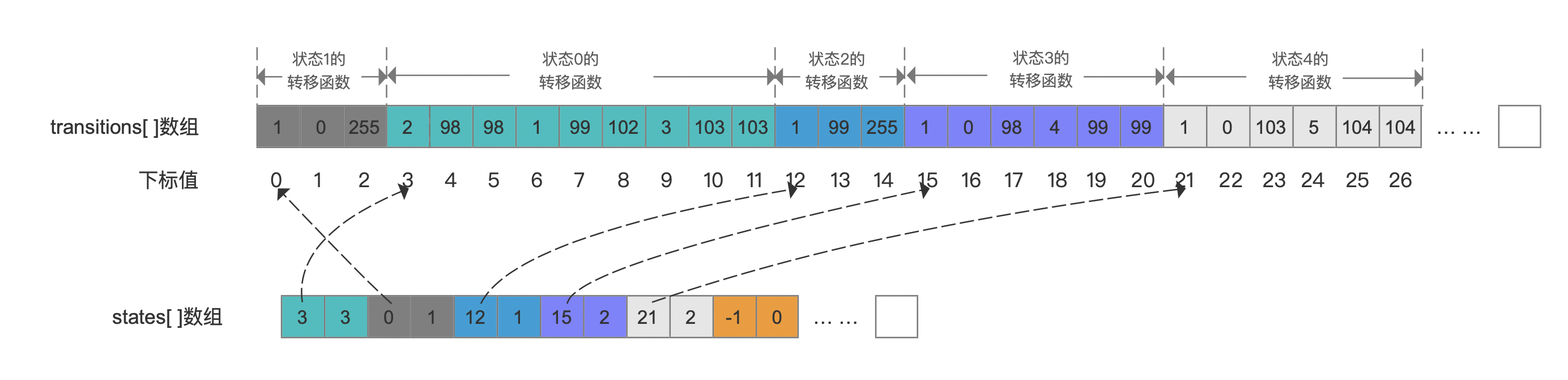
图11中,状态5没有转移函数,故它在states[ ]数组中用 -1 描述。
本文介绍了Lucene生成DFS的流程以及存储结构,在以后介绍TermRangeQuery中会介绍如何通过transitions、states数组来实现范围查找。
点击下载附件
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK