

Hotel Review NLP Classifier for The Hilton
source link: https://towardsdatascience.com/hotel-review-nlp-classifier-for-the-hilton-7e2dd304f8e2?gi=b1924fb701ec
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Hotel Review NLP Classifier for The Hilton
Detailed project report following a CRISP-DM framework. Working Demo App Included.

Jul 11 ·7min read
In this blog I will go over how I improved my classifier by implementing a neural network model for my NLP project on Hilton Hotel reviews. My model aimed to use sentiment analytics that can classify a review with a score between 1 and 5.
Here is a link to the Github link for my project: www.github.com/awesomeahi95/Hotel_Review_NLP
I will go over the goal, the processes, and the result of my project.
Business case for my project:
In the modern day, public discussion and critiquing of products and services occurs beyond dedicated mediums, and now also takes place in the realm of social media, too.
Online Hilton Hotel reviews are currently found on tripadvisor, trustpilot, and expedia. The majority of reviewers gave a score between 3 and 5, so if a new customer browses online reviews on any of the previously mentioned review sites, they may consider booking a room at the Hilton.
What if they already made up there mind from hearing what a friend had to say? Potential customers, could have their hotel choice be influenced by a tweet. Opinions are shared constantly on social media platforms, and are read by their followers. The knowledge, of what these followers think about our hotel, from reading these online posts, could help us better understand the general public’s perception of our hotel.
By using sentiment analysis, on existing hotel reviews from Tripadvisor.com, I created a model that can quantify on a scale of 1–5, how the author of a tweet on twitter, or a post on a reddit thread, feels about our hotel, and as a result, also how the readers think about us. If a review classifies to be less than a score of 3, this post/tweet could be looked into, find out why they had a negative opinion of our hotel, and in return fix the problem.
Example of a review on Tripadvisor:

A human could relatively easily classify the score (to some degree) of the review above, by just reading the text. We are accustomed to understanding how another person feels about a topic, from the words they use, and the context around it.
For a computer to both interpret the opinion of a human and then understand the sentiment there a few stages:
- Breaking down words to their root form:

Using techniques like stemmation and lemmatisation, to break down words like disgusting and disgusted to a root word, disgust.
- Tokenisation:
Using regular expressions to break down the sentence to only words, and no punctuation.
- Removing Stopwords
Words like ‘I’, ‘he’, ‘and’, etc are the most frequent words and could impact the value of other words, so we remove these words. As for my project, that was orientated around hotels, I also removed frequent words such as ‘hotel’, ‘room’, and ‘airport’.
- Vectorisation
(THIS IS THE LEAST HUMAN STEP)
Prior to the initial phase of modelling, I had 2 choices: count vectorisation (bag of words) and TF-IDF vectorisation. Both of these methods consider frequency of words as the general metric, although TF-IDF also compares the frequency with the entire corpus for a more meaningful metric.
I decided to use TF-IDF vectorisation for my project. So my lemmatised review columns changed from this:
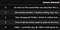
To this:

So, now a review was represented by a singular value associated to 138 of the most frequent words in my review corpus.
I wasn’t too happy about the number of zeros I saw, despite it making sense.
- Modelling and Testing
The machine learning phase. Here I experimented with 5 classification algorithms and 5 ensemble methods too, all with some hyperparameter tuning. For further detail please look at the 3rd Notebook in my Github Repo link I shared at the start of the blog.
These were my results:
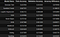

I chose the Stacking (ensemble of Adaboost of Logistic Regression and Logistic Regression) model, as it had a decent training accuracy, and a reasonable validation accuracy. You might be thinking, these accuracies are in the 0.5 to 0.6 range, surely that’s not great. Well, considering this was a 5 way multiclass classification, the odds of randomly choosing one and getting it right was 0.2. Also, these are subjective scores, it can be hard even for a human to be on the dot with choosing the right score. This is better demonstrated with a confusion matrix.
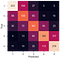
You can see most the time the model does predict the correct score, illustrated by the diagonal line. The majority of the error we saw (accuracy being in 50–60% range), you can see here, comes from the adjacent score, e.g. predicting a score of 1 but true score was 2. I was happy with this as the model would still be good enough to distinguish between great reviews, average reviews, and bad reviews.
At this point the computer could interpret the inputted the text, and somewhat understand the sentinment from it.
I wanted better.
Why not make it more human? Neural networks are designed like the functionality of neurons in our brains, so that was probably the change I could make to better my model.
- Neural Network
The preprocessing was a bit different before creating my neural network model.
I created a dictionary with keys that were words, all the unique words in the corpus, and values, a number associated with each unique word. I also added 4 special keys for padding, start of review, unknown words, and unused words. In total I had 17317 word entries in the dictionary. This comes from 9405 reviews.
word_index_dict['<PAD>'] = 0 word_index_dict['<START>'] = 1 word_index_dict['<UNK>'] = 2 word_index_dict['<UNUSED>'] = 3
Pre-Indexing:
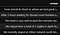
Post-Indexing:
As a final preprocessing step, I added a padding layer, with a max length of 250 words. Then I trained the model.
- Neural Network Architecture:

The special layer for NLP here is the Embedding Layer.
The words are mapped to vectors in a vector space, in my case 16 dimensional vectors. This time each word has a vector based on the words around it, the context. The vectorisation is different to the TF-IDF vectorisation from earlier, we aren’t just looking at frequency based metrics, but actually looking into the impact of each word, given the context.
This is starting to feel more human.
Now words like good, great, bad, and worse have some more meaningful numbers (vectors) associated with them. New reviews that the model can be tested on, won’t just contain some of these words, but also the words that surround it, that paint a better picture of what the writer of the review is trying to say. This picture could be better explained with more data but the current 9405 review will do a fine job.
- Testing Neural Network Model
The testing accuracy of the model came to 0.5710 which is better than our previous model’s accuracy of 0.5077. So we have an improvement of 7% which is quite significant, but again the best way to observe this 5 way multi-class classifcation is by looking at a confusion matrix.
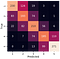
As you can see, the model didn’t predict a review with a score of 5 as a score of 1 once or vice versa. The other mis-classified scores have improved, and the majority of the predictions are closer to the middle diagonal.
- Application
I have designed a demo application of the model using Streamlit and Heroku, that you can try out here: www.hilton-hotel-app.herokuapp.com/
Improvements to be made:
- Use a bigger training dataset
- Try a deeper neural network
- Reduce complexity of classification to binary classification
- Implement other pre-made vectorisation methods — word2vec or GloVe
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK