

紫金山沈洋:基于可编程交换机和智能网卡的四层负载均衡器
source link: https://www.sdnlab.com/24264.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在2020网络数据平面峰会上,来自紫金山实验室未来网络中心的研究员——沈洋给我们带来了《基于可编程交换机和智能网卡的四层负载均衡器》的主题演讲。
本次演讲主要包括三个部分:L4负载均衡器的现状调研,可编程交换机的LB卸载,以及智能网卡+OVS的LB卸载。
L4负载均衡器的现状调研
首先,来了解下什么是四层负载均衡器。
什么是L4负载均衡器?
比如,在云数据中心里部署一组服务,以HTTP方式对外提供API接口,可以看到,HTTP API URL主要由两部分组成,一个是IP地址+四层端口号,另一个是path路径,二者组成api的唯一标识。为了考虑大连接并发,通常部署多服务实例进行负载分担,每个实例以容器POD或者虚机形式部署,拥有属于自己的后端IP地址。
那么问题来了,用户如何找到这些成千上万的后端IP地址?
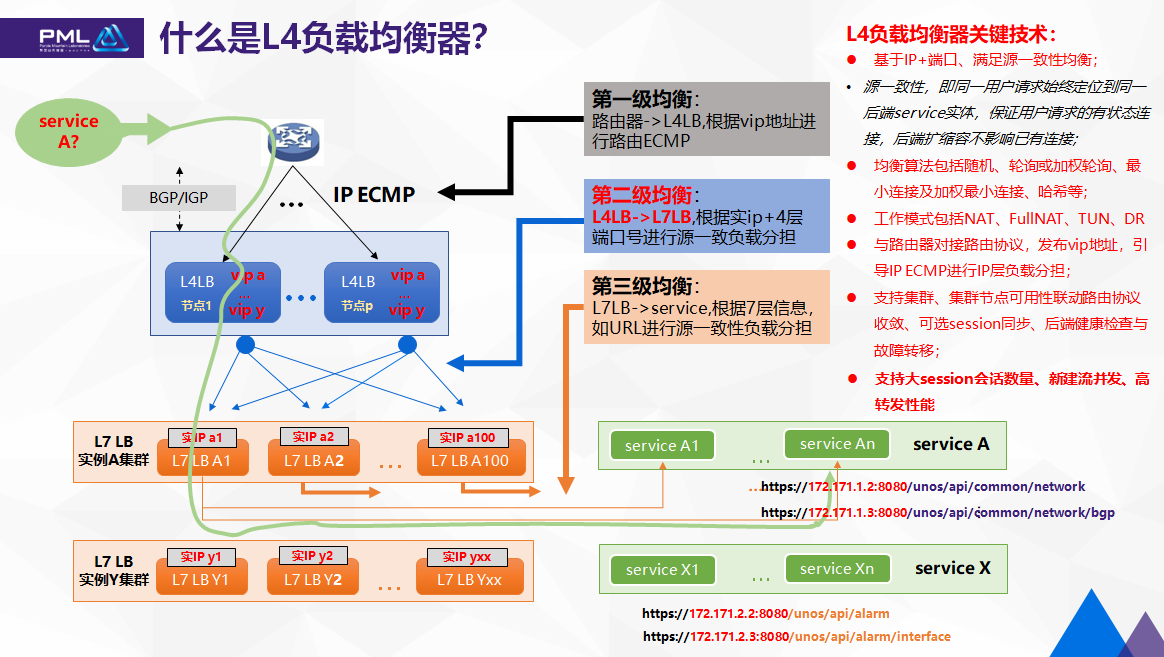
业界通用的解决方案是对外仅暴露一个或少量VIP地址,通过层层负载均衡器来实现后端分担和定位。比如,最接近service的是7层负载均衡器,它识别到URL path信息,实现服务发现和负载均衡,常见的有nigix;接着通过4层负载均衡器,实现对nigix集群负载分担;再通过BGP/IGP路由协议,实现对L4负载均衡器的集群的负载分担。当然,这还没完,比如还会有DNS等。
简单总结一下,这张图中,存在三级均衡策略,包括:
- 第一级均衡,在路由器到L4LB之间,根据VIP地址进行路由ECMP;
- 第二级均衡,在L4LB到L7LB之间,根据实IP+4层端口号进行源一致性负载分担。
- 第三级均衡,在L7LB到service之间,根据7层信息,如URL进行源一致性负载分担。
由于4层以上都是有状态连接,只有确保源一致性,才能保证服务不中断,
所以这里强调L4、L7层要求源一致性。
针对负载均衡器的一些关键技术,总结如下:
- 基于IP+端口、满足源一致性均衡;
- 源一致性,即同一用户请求始终定位到同一后端service实体,保证用户请求的有状态连接,后端扩缩容不影响已有连接;
- 均衡算法包括随机、轮询或加权轮询、最小连接及加权最小连接、哈希等;
- 工作模式包括NAT、FullNAT、TUN、DR
- 与路由器对接路由协议,发布vip地址,引导IP ECMP进行IP层负载分担;
- 支持集群、集群节点可用性联动路由协议收敛、可选session同步、后端健康检查与故障转移;
沈洋认为,考验一个负载均衡器产品最核心水平的三点包括:是否支持大session会话数量、新建流并发能力、以及转发性能。
业界情况
Linux:LVS
Linux内核的LVS,也就是IPVS。它是很多互联网公司构建负载均衡的首选,大致总结一下它的特点:
- 支持丰富的调度算法和工作模式;
- 仅支持主备模式,且基于namespace粒度;
- 配合用户态IPVSADM、keepalived程序实现配置管理、主备选举、real server健康检查
- 但很不幸的是,没有实现connet表的netlink notify接口,也缺乏对多租户的支持
阿里巴巴:SLB
阿里巴巴的SLB,开始时基于LVS,做了大量扩展和优化,包括以下4点:
1、LVS-FULLNAT转发模式:提出了TOA的概念解决RealServer无法获得用户IP。主要原理是:将client address放到了TCP Option里面带给后端RealServer,RealServer上通过toa内核模块hack了getname函数,给用户态返回TCP Option中的client ip。
2、LVS-SYNPROXY主要原理:参照linux tcp协议栈中syncookies的思想,LVS-构造特殊seq的synack包,验证ack包中ack_seq是否合法-实现了TCP三次握手代理。也就是client和LVS间建立3次握手,成功后,LVS再和RS建立3次握手;
3、LVS-集群:通过OSPF ECMP + seesion全局同步,来实现集群化;
4、性能优化:第一,多队列网卡,绑核;或使用google提供的软多队列-RPS;第二,对keepalived进行了优化,主要将网络模式从select改为了epool;第三,关闭网卡LRO、GRO功能关掉,尤其是broadcom的网卡。
爱奇艺:DPVS
爱奇艺的DPVS,源于阿里巴巴LVS,主要实现了DPDK的转发加速,相关的源码可以在github上找到,不过很久不更新了。
京东:SKYLB
京东 skylb,依靠路由协议来实现IP层ECMP,也就是的第一级负载均衡,设计实现一套高可靠、高性能、易维护及性价比高的L4负载均衡系统。
美团:MGW
美团 MGW,有三个显著的技术特征:
关键技术1:利用网卡的RSS和flow director特性实现无锁编程
关键技术2:利用IP ECMP+全局有状态连接表实现集群高扩展和高可用
关键技术3:利用Google Maglev实现源一致性Hash
总结一下美团MGW的特点:
1、利用DPDK实现kernel bypass;
2、为了获得较强的网络环境适应性,选择FULLNAT,牺牲一定的性能;
3、session全局同步,复杂度高;
github:GLB-director
GLB-director的亮点:
- L4 LB集群+BGP ECMP,实现director节点线性扩展;
- director群集节点独立生成静态转发表,director节点增减时保证连接一致性;
- 利用proxy节点iptable提供二次调度,服务器节点增减时保证连接一致性;
- 转发面DPDK加速,利用Flow Bifurcation实现Linux用户态和内核态流量分配;
从通用性的角度来看,GLB-director有一些不足:
- 仅支持TCP业务;
- GUE隧道封装解封装,增加CPU负担;
- 涉及服务器侧修改,耦合大、侵入式;
- 无状态实现有利有弊,弊端是无法做到连接数均衡、连接数限流等
Github glb-director最大的技术特点是利用GUE隧道,实现无状态连接一致性。相关代码也可以在githhub上可以下载,建议有兴趣的同学读下它的源码
F5:BIG-IP
商用负载均衡器产品F5 BIG-IP,这里取了它的两款高端产品,列举核心指标。它的i15800系列最大吞吐可以做到320G,基本算是业界最强了。需要提及的是,nigix在19年3月份被F5以6.7亿美金收购,F5宣称会继续在nigix开源社区投入,此刻你是否想到了JDK8?

小结与展望
- 控制平面或多或少参考linux LVS实现,有的公司是将LVS移植到用户态;
- 出于部署通用性考虑,云公司自研L4 LB大多采用FULLNAT或某种隧道技术;
- 转发面大多基于通用CPU+DPDK加速,为了提升整体转发性能,需要部署大规模集群,进一步带来成本、session同步难度、整体控制难度提升;即便如此,集群化横向扩展的方案也越发难以满足当下互联网业务爆发式增长带来的高带宽转发性能诉求,所以如何量级式提升转发能力将成为发展下一代L4LB技术的变革理由。
- 随着可编程ASCI交换机芯片、智能网卡出现,将基于CPU转发的L4LB转发面功能卸载到硬件中,以获取高转发性能、低成本的4层负载均衡产品将成为可能,也是当下的工程和研究热点。为此,紫金山实验室也投入相关研究和实践,下面章节将做简单汇报。
下面沈洋讲述了紫金山实验室相关的一些工作进展情况
可编程交换机的LB卸载
P4可编程芯片
首先来看看基于批复可编程的芯片当前业界的一些情况:
- 2019,Barefoot发布了采用7nm制程的Tofino2芯片,采用50Gb/sec信号和PAM-4编码,总带宽达到12.8Tb/sec。
- 2019,Mellanox推出了Spectrum-2芯片,该芯片具有完全共享的单一数据包缓冲区,最多提供16个400 GbitE端口,并支持P4编程语言。
- 2019年12月13日,思科打破自己长久以来的传统,宣布推出了花五年时间打造的Silicon One可编程芯片,该芯片支持P4语言,具备10.8T转发能力。
- 同时,思科还宣布了“面向未来的互联网”战略,提供业界首款设计可同时满足电信运营商和互联网运营商需求的网络芯片,并开始为微软、Facebook 等公司网络设备提供交换机芯片。
- 此外,Intel、Xilinx等也推出了支持P4语言的可编程FPGA与100G智能网卡。
L4 LB(NAT模式)
随着转发面可编程语言和芯片可扩展流水技术的涌现,使用交换芯片实现负载均衡器将成为可能。紫金山实验室当前主要研究了主要NAT模式的4层负载均衡器的实现,然后用可编程交换机进行卸载。先来看一看什么是NAT模式。

看上图,从用户侧去访问后端的服务,经过4层负载均衡器处理的时候,用户看到的目的IP是VIP,也就是暴露了虚拟IP的地址,然后在负载均衡器上,目的IP被替换成某个后端的的地址,叫RIP,比如,当前连接选择的后端是RS2,那就替换成RIP2地址转发到后端,回程的报文在经过轮番处理的时候,把原IP地址再替换回Vip,然后转发到用户端,当然在NAT转换的过程中,四层端口号也可能会做相应转换。可以看到,从用户侧到服务侧,这条路线在均负载均衡器上做了一次DNAT的转换,回程的报文做了一次SNAT的转换,这就是所谓的NAT模式。
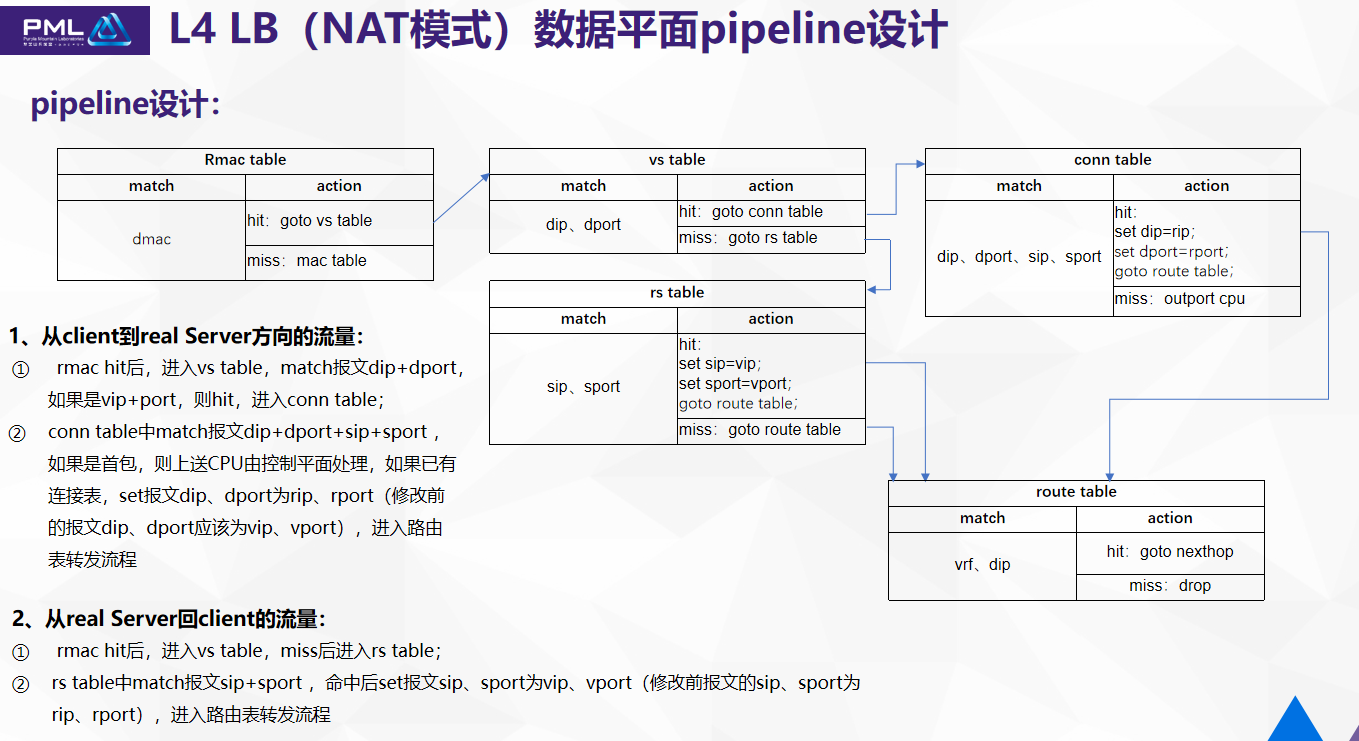
在实现的过程中有三张关键的表,这三张表来指导4层负载均衡器业务逻辑的实现:
第一张是虚拟服务的表,主要有后端提供服务的列表。另一张是后端的真实服务的表,主要信息包含后端的Rip、Rport的信息。还有一张是连接表,连接表是动态生成的,主要信息有用户的IP、用户的port、以及选择哪个后端的地址和Port的信息。
NAT模式的4层负载均衡器,它的数据平面pipeline如何设计?刚才提到的三张表,用p4的语言来插入到现有的二三层功能,再到pipeline,这三张表第一张是 vs table,放在RMac之后,如果命中,再走连接表,运动后修改目的地和目的端口号,放在route表处理。即便交换机是可编程,回程的流量走的流程还是固定的,要先经过vs table去处理,这种情况回程是不会命中的,miss会走到rs table。如果命中,要修改原端口号,再到route表处理;如果miss,那不做修改,正常走route表处理。
控制平面与数据平面API接口
再来看看那上行和下行两个方向的流量,在负载均衡器上进行的一些查表的动作以及修改报文的动作。
- SAI LB API扩展
- 定义vs、rs、connet三个object,相关attribute,以及create、remove、set、get方法;
- connet table设计超时时间,参考dmac表;
-
connet table引用count进行必要的报文统计计数。
-
首包miss上送
参考smac学习流程,首包通过摘要(Digest)上报,摘要信息包括新连接必要的信息,由ifindex、vlan、dip、dport信息,通过SAI callback上送到用户态控制面程序。 -
控制面安全
为防止大量miss报文集中上送冲击CPU,影响控制平面安全,我们进行限速、重复包丢弃等手段进行保护。
典型应用:L4LB与DCgw合一的云数据中心组网方案
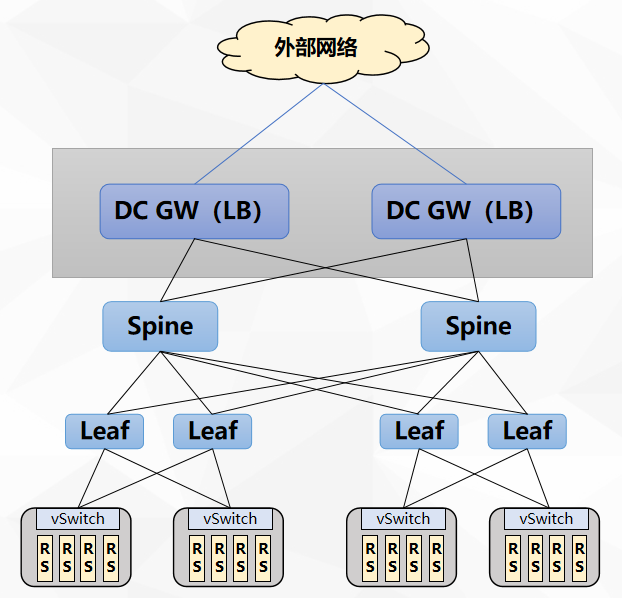
- 嵌入进已有的DC GW Group模型中,多个GW首先在IP层形成保护和分担,GW之间利用BGP EVPN type5路由,实现通过vxlan隧道对GW与外部网络间的链路保护。
- LB VIP地址通过BGP路由发布到外部网络,进行第一级IP ECMP负载分担;
- LB实现第二级IP+port的四层负载分担
- 去除L4 LB专用设备,简化组网和流量模型
- 通过可编程流水,获得单芯片高达10T级别的线速转发性能
需要进一步完善:
- 后端的健康检查;
- 新建流的并发性能提升;
- 限速功能;
在研究和落地的过程中遇到的最大的一个问题:ASCI芯片表容量非常有限,无法满足LB大连接表需求。
智能网卡+OVS的LB卸载
由于硬件交换机表容量受限,我们接着想到能否利用可编程智能网卡来卸载L 4LB功能?
有三个问题等待研究:
①智能网卡能否提供大容量表项?
②数据平面性能如何, pipeline应该如何设计?
③控制平面应该如何设计? 应该选择怎样的offload接口?
先来看看目前智能网卡的主流方案有哪些,以及各自优缺点。通过综合比较,紫金山倾向于优先考虑基于FPGA和可编程ASCI的smart nic。
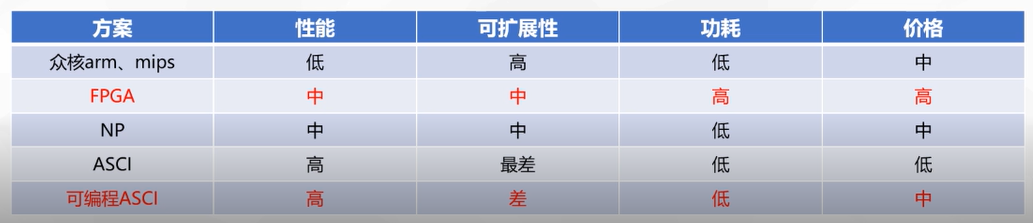
智能网卡能否提供大容量LB表项?
通过和一些厂家接触了解到,网卡可以外挂memory来存储转发表,如此一来,表容量问题将有可能得到解决;但是,吞吐、时延、表容量能否鱼和熊掌兼得?这个问题还在需验证。
基于L4LB控制平面与数据平面设计
先看一下开源的云平台对load Balancers接口的一些定义。
openstack LBaas2.0
- neutron定义了Load Balancers、Listeners、Pools、Members、Health Monitor等几个对象
- vip、vport、protocol以及rip、rport等信息在这几个对象中描述出来
K8s Service
- 基本通过Service object描述服务与Load Balancing
- 一般CNI plugin通过IPVS来实现负载均衡
OVN+OVS的L4LB功能
- OVN作为openstack而生的轻量级SDN控制器,自然是要支持neutron定义的网络功能,包括LB;
- 在OVN NB中定义了Load_Balancer table,非常简单,基本只包含vip、vport与rip、rport地址对关系,protocol、health_check等几个字段;
- 结合OVS openflow控制通道,简单实现了基本的L4LB能力
智能网卡offload驱动接口
- 内核态tc flow
- 内核态switch dev
- 用户态dpdk rte flow
紫金山的目标是将vxlan/geneve隧道、L4LB offload到智能网卡,实现host overlay、L4LB硬化。关于技术选型,紫金山最终选择OVN+OVS,借助开源社区,快速构建能力;offload接口选择overlay tc flow + underlay switch dev,简化数据平面pipeline。
可编程交换机与智能网卡的组合拳
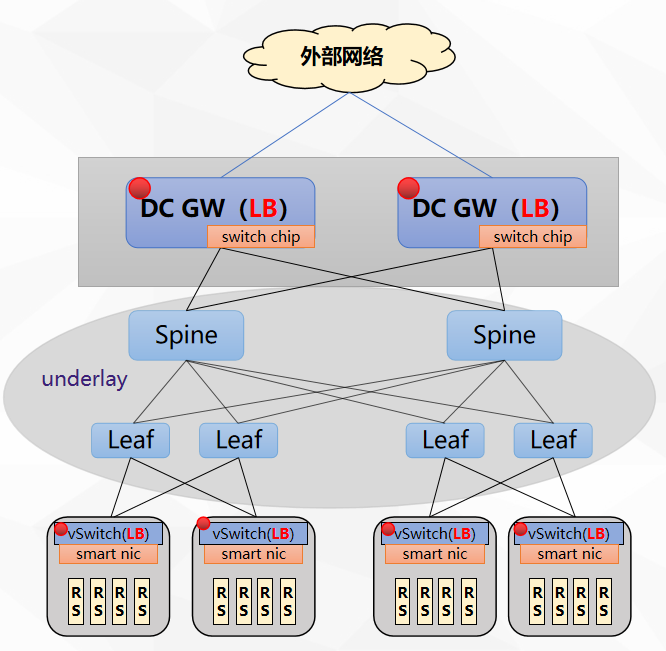
通过实现可编程交换机和智能网卡来硬化LB功能,在云数据中心里,也需要一个组合方案,可以从上图看到,DC GW的点可以兼做LB,另外,在服务器侧,通过vSwitch和智能网卡来卸载vxlan隧道,加上4层负载均衡的功能,实现从服务器侧到GW都能提供LB功能。
如此组合有一些优势和弊端,交换机上明显的弊端是其表容量有限,不过其转发性能较高,那我们如何扬长避短,发挥各自优势?如何识别大象老鼠流,大象流引导到交换机,老鼠流引导到服务器上处理?硬件表容量超标时,如何进行冷热分离、软硬结合?如何将LB服务能力池化管理,支持服务自动感知、故障转移、按需扩缩容?如何进行流量模型调度,即业务链自动编排和管理?如何与openstack、k8s以及一些商用云平台自动化对接?
答案都是通过SDN控制器解决上述问题。
总结
事物的发展总是螺旋式上升,网络通信数据平面在追求高性能和扩展性道路上一直孜孜不倦,相信未来总有一天能找到像CPU指令的自由、ASCI芯片高性能的结合体,为人们提供廉价、便捷、高效的通信载体。
以上就是沈洋分享的全部内容。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK