

我们需要什么样的数据库
source link: https://zhuanlan.zhihu.com/p/31380698?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
我们需要什么样的数据库
解决什么问题
数据库的问题从来就不是数据库自身的问题。从能存取数据的角度,所有的数据库都是合格的。关键的问题是,我们用数据库去满足什么样的业务需求。不同的数据模型,会对上层的业务代码的风格产生非常深远的影响。从开发效率,开发体验的角度,从运行时性能的角度,从数据正确性的角度,从数据安全性的角度,可以解读出非常多元和丰富的信息。对一个数据库来说不能简单地用好或者不好来评价。另外过去的经验也会成为一种束缚,从解决的业务问题本身,到实际使用MySQL,中间是有很多种可能的。当我们习惯了一种现有的开发风格之后,思路很容易被限制在原有的领域里。如果仅仅从问题的本质出发去推导一个解决方案,会发现更广阔的可能性。
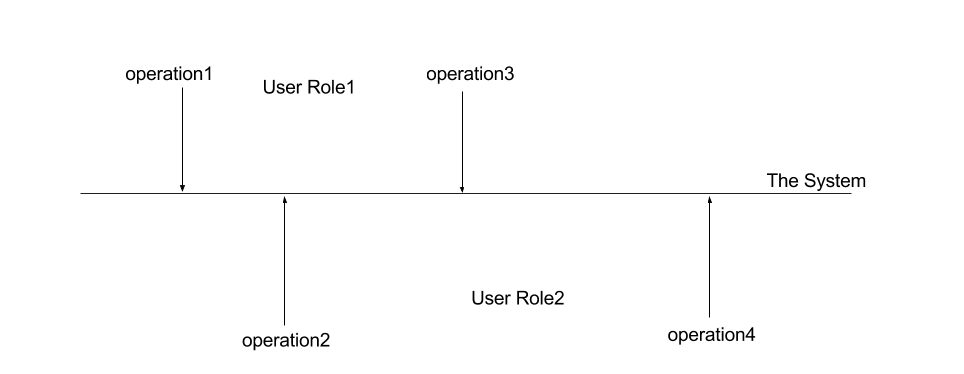
所有的信息系统的起点都是数据的写入。无论是一个电子商务系统,需要交易多方进行信息的录入。还是一个简单的内容管理系统需要编辑上传内容。所有的业务系统的起点必然是交易数据的产生或者数据的录入。所以我们会有一个类型的存储叫“主存储”,它保存了source system of record。
主存储的作用是协作的沟通桥梁。多个用户角色在一个系统上进行协作,通过把过去达成的协议记录成一条主存储的记录,从而影响后续的行为的履约。我们可以把主存储的数据想象成线下多方交易里的纸质单据。做一次存储就是相当于线下一次合同的签署。这个步骤签署的协议,决定了后续多方的行为。这里有两种细微地不同地主存储:
- 交易发生在线下:比如线下已经签约了合同了。线上的电子化档案只是一份信息的拷贝。这个时候过去发生了什么,就应该是什么。扩大一点范围,对自然现象的采集,比如温度传感器,也是类似的。某时某分是多少度,这个是自然发生的,采集虽然是数字化的第一手数据,但是采集本身并不能决定这个值是什么。
- 线上交易:签约的行为放在了线上。比如审批一个用户是否合法,比如发单。这些操作是否能够通过,也就是操作的结果是由线上系统来决定的。这种人与人之间,人与平台(其实也是人,只是平台代表了具体的人格)之间完全通过线上进行协作,以数字化记录的方式签订“合同”的方式,对于主存储就提出了非常高的要求。
主存储的职责
所以我们可以归纳出,如果主存储要支持好用户们在线上进行协议,需要具备四个基本职责:
- 支持线上交易,主要的体现就是强制执行业务规则,让参与协作的主体对接下来要发生的事情达成一致,用于指导后续的行为(线上或者线下的行为)。简单的可能只是一个非空的校验,复杂的牵涉到并发情况下状态机的约束保证。
- 处理并发:这个其实还是强制执行业务规则,只是实现难度更高一点,被单独提出来。当多人同时操作的时候,我们要做到言而有信。答应了的事情(比如请求的响应是success),就要做到(比如实际的数据库里的记录不对)。这种不一致,可以理解为商业上的违约行为。
- 保存过去真实发生的事情,保存多方什么时候达成过什么样的协议。这个主要体现为单据可以查询上。甚至是可以按历史时间进行回溯查询。
- 做为其他视图的数据源。比如搜索,可以查询到商家上架的商品。并不代表商品上架要直接写入到搜索引擎里,而是先做为一个商业上的契约落到主存储里。再做为数据源复制到搜索引擎。当然如果主存储也能支持各种各样的检索,承担部分视图的功能也是可以的。但是能够支持与其他存储系统集成,应该是主存储的一个基本职责。
接下来我们以扣费业务为例,来看一下不同的数据库当主存储这个角色的时候,遇到的一些挑战
MySQL
扣费的业务需求如下:
- 扣费不能把余额扣成负数
- 同一个单号的扣费不能重复扣。第一次扣成功了,第二次再扣还是返回成功,但是余额不再变化。
- 要能够让用户查看账户的今日不同类型交易引起的余额变化情况
- 扣费不单单是直接把钱扣了,得记录为什么订单扣的等其他信息,以用于后续流程的开展,以及对账需求。即使帐这边不记录,订单系统那边也得记录,要不然流程串 不起来。
MySQL 在处理这些需求的时候,遇到哪些挑战呢?
- 并发修改余额的时候,要保证余额不变成负数。需要把业务逻辑写成SQL,通过单条SQL的原子性来保证并发下的“规则检查”与“实际扣费”这两个操作是原子的。也就是需要把业务逻辑下推到数据库去做。然后数据库的查询语言的能力就限制了业务逻辑的表达能力了。
- 同一个单号不能重复扣,这个就必须把扣款单给保存起来了。但是余额也要存啊,因为前面还有第一条的业务规则摆在那呢。当需要既更新余额,又保存扣款单的情况下,怎么保证这两个的更新是原子的呢?就必须使用mysql的多表事务了,一方面降低了吞吐,另外一方面也给分库分表带来了挑战。
- 需要统计今日的余额变化,还要分类型,这个拿主表来做显然是不合适的。但是引入其他的存储去做实时聚合,又会有数据库之间的同步机制问题,可靠性问题和延迟问题。
- 因为扣费单不仅仅是有扣费相关的字段,还得附加其他的信息,这些信息和上游的交易流程还有关系。这样三天两头就要加字段。而每次加字段都要在半夜避开业务高峰期进行。当分库分表比较多的时候,需要加字段的实例多了,这个过程就更加漫长。导致新需求轻易是不加字段,能用“其他存储”解决就用“其他存储”解决。这样就会导致很多应该进主存储的信息,被放到了其他的地方。给数据的一致性,安全性和可靠性都带来了风险。
另外因为MySQL提供了开放性的读写接口。为了保证数据安全,一般还要再封装一层数据服务。让底层数据库只能由数据服务读写(比如ip白名单),然后把业务规则写到这个数据服务里。再由这个数据服务去提供给更多样化的业务系统使用。这种数据服务的封装往往引起了重复代码,以及多了一层延迟。但是开发者相比存储过程更喜欢自己封装一层。因为数据服务自身无状态,方便扩容。另外可以拿任意自己喜欢的语言来写,不一定要用SQL。
MongoDB
和 MySQL 的情况是非常类似的
- 余额不能为负通过把操作下推到db来解决。需要组合findAndModify与$inc来完成。同样需要使用数据库的查询语言来表达业务逻辑。同时因为MongoDB相对小众,使得这个限制变得更加痛苦。
- 不能重复扣这个MongoDB里没有直接的解法,因为不支持多行事务。如果直接把流水和余额存到一个document里来保证一致性,在流水不断增长的情况就会超过上限。
- 数据同步方面MongoDB还不如MySQL。MySQL基于binlog,canal和kafka也算有一套相对完善的开源方案。相比之下基于 oplog 的方案没有那么成熟。
- 加字段方面,MongoDB比MySQL强。因为MySQL改表结构要重写已有的行,而MongoDB加字段不需要动到现有的数据。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK