

Indian Accent Speech Recognition
source link: https://towardsdatascience.com/indian-accent-speech-recognition-2d433eb7edac?gi=55c7ca460c01
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Traditional ASR (Signal Analysis, MFCC, DTW, HMM & Language Modelling) and DNNs (Custom Models & Baidu DeepSpeech Model) on Indian Accent Speech
Courtesy : Speech and Music Technology Lab, IIT Madras

Notwithstanding an approved Indian-English accent speech, accent-less enunciation is a myth. Irregardless of the racial stereotypes, our speech is naturally shaped by the vernacular we speak, and the Indian vernaculars are numerous! Then how does a computer decipher speech from different Indian states, which even Indians from other states, find ambiguous to understand?
ASR (Automatic Speech Recognition)takes any continuous audio speech and output the equivalent text . In this blog, we will explore some challenges in speech recognition with focus on the speaker-independent recognition, both in theory and practice.
The challenges in ASR include
- Variability of volume
- Variability of words speed
- Variability of Speaker
- Variability of pitch
- Word boundaries : we speak words without pause.
- Noises like background sound, audience talks etc.
Lets address each of the above problems in the sections discussed below.
The complete source code of the above studies can be found here .
Models in speech recognitioncan conceptually be divided into:
- Acoustic model: Turn sound signals into some kind of phonetic representation.
- Language model: houses domain knowledge of words, grammar, and sentence structure for the language .
Signal Analysis
When we speak we create sinusoidal vibrations in the air. Higher pitches vibrate faster with a higher frequency than lower pitches. A microphone transduce acoustical energy in vibrations to electrical energy.

If we say “ Hello World ’ then the corresponding signal would contain 2 blobs
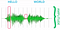
Our speech is made up of many frequencies at the same time, i.e. it is a sum of all those frequencies. To analyze the signal, we use the component frequencies as features. Fourier transform is used to break the signal into these components.

We can use this splitting technique to convert the sound to a Spectrogram , where frequency on the vertical axis is plotted against time . The intensity of shading indicates the amplitude of the signal.

To create a Spectrogram ,
- Divide the signal into time frames.
- Split each frame signal into frequency components with an FFT.
- Each time frame is now represented with a vector of amplitudes at each frequency.

If we line up the vectors again in their time series order , we can have a visual picture of the sound components, the Spectrogram .

Next, we’ll look at Feature Extraction techniques which would reduce the noise and dimensionality of our data.

Feature Extraction with MFCC
Mel Frequency Cepstrum Coefficient Analysisis the reduction of an audio signal to essential speech component features using both Mel frequency analysis and Cepstral analysis. The range of frequencies are reduced and binned into groups of frequencies that humans can distinguish. The signal is further separated into source and filter so that variations between speakers unrelated to articulation can be filtered away.
a) Mel Frequency Analysis
Only those frequencies humans can hear are important for recognizing speech. We can split the frequencies of the Spectrogram into bins relevant to our own ears and filter out sound that we can’t hear.

b) Cepstral Analysis
We also need to separate the elements of sound that are speaker-independent. We can think of a human voice production model as a combination of source and filter , where the source is unique to an individual and the filter is the articulation of words that we all use when speaking.

Cepstral analysisrelies on this model for separating the two. The cepstrum can be extracted from a signal with an algorithm. Thus, we drop the component of speech unique to individual vocal chords and preserving the shape of the sound made by the vocal tract.
Cepstral analysis combined with Mel frequency analysis get you 12 or 13 MFCC features related to speech. Delta and Delta-Delta MFCC features can optionally be appended to the feature set, effectively doubling (or tripling) the number of features, up to 39 features , but gives better results in ASR.

Thus MFCC (Mel-frequency cepstral coefficients) Features Extraction,
- Reduced the dimensionality of our data and
- We squeeze noise out of the system
So there are 2 Acoustic Features for Speech Recognition:
- Spectrograms
- Mel-Frequency Cepstral Coefficients (MFCCs):
When you construct your pipeline, you will be able to choose to use either spectrogram or MFCC features. Next, we’ll look at sound from a language perspective, i.e. the phonetics of the words we hear.
Phonetics
Phonetics is the study of sound in human speech. Linguistic analysis is used to break down human words into their smallest sound segments.

- Phoneme is the smallest sound segment that can be used to distinguish one word from another.
- Grapheme , in contrast, is the smallest distinct unit written in a language. Eg: English has 26 alphabets plus a space ( 27 graphemes ).
Unfortunately, we can’t map phonemes to grapheme , as some letters map to multiple phonemes & some phonemes map to many letters. For example, the C letter sounds different in cat, chat, and circle.

Phonemes are often a useful intermediary between speech and text. If we can successfully produce an acoustic model that decodes a sound signal into phonemes the remaining task would be to map those phonemes to their matching words . This step is called Lexical Decoding, named so as it is based on a lexicon or dictionary of the data set.
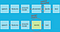
If we want to train a limited vocabulary of words we might just skip the phonemes. If we have a large vocabulary, then converting to smaller units first, reduces the total number of comparisons needed.
Acoustic Models and the Trouble with Time
With feature extraction, we’ve addressed noise problems as well as variability of speakers. But we still haven’t solved the problem of matching variable lengths of the same word.
Dynamic Time Warping (DTW) calculates the similarity between two signals, even if their time lengths differ.This can be used to align the sequence data of a new word to its most similar counterpart in a dictionary of word examples.

Hidden Markov Models (HMMs) in Speech
HMMs are useful for detecting patterns through time . HMMs can solve problem of time variability, i.e. the same word spoken at different speeds.

We could train an HMM with labelled time series sequences to create individual HMM models for each particular sound unit. The units could be phonemes, syllables, words, or even groups of words.

If we get a model for each word, then recognition of a single word comes down to scoring the new observation likelihood over each model.

To train continuous utterances, HMMs can be modelled for pairs . Eg: HER-BRICK. This will increase dimensionality. Not only will we need an HMM for each word, we need one for each possible work connection.
But if we use Phonemes, the dimensionality increase isn’t as profound as with words, for a large vocabulary. For 40 phonemes, we just need 1600 HMMs to account for the transitions.

Language Models
Language Modelinject language knowledge into the words to text step in speech recognition to solve ambiguities in spelling and context. i.e. which combinations of words are most reasonable.
For example, since an Acoustic Model is based on sound, we can’t distinguish similar sounding words, say, HERE or HEAR. The words produced by the Acoustic Model can be thought of as a probability distribution over many different words. Each possible sequence can be calculated as the likelihood that the particular word sequence could have been produced by the audio signal .
If we have both Acoustic Model and the Language Model, then the most likely sequence would be a combination over all these possibilities with the greatest likelihood score.

We want to calculate the probability that a particular sentence could occur in a corpus of text. We have seen the probability of a series of words can be calculated from the chained probabilities of its history. With N-grams we approximate the sequence probability with the chain rule.
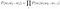

To address the problem of prohibitively huge calculations, we use the Markov Assumption to approximate a sequence probability with a shorter sequence.

We can calculate the probabilities by using counts of the bigrams and individual tokens.
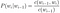
We can then score these probabilities along with the probabilities from the Acoustic Model to remove language ambiguities from the sequence options.
To summarize the above Speech-to-Text (STT) process,
1. We extract features from the audio speech signal with MFCC .
2. Use an HMM acoustic model to produce sound units, phonemes, words.
3. Uses statistical language models such as N-grams to straighten out language ambiguities and create the final text sequence. Using Neural Language Model trained on massive amounts of text, probabilities of spelling and context can be scored.
Traditional vs State-of-the-artASR
Traditional ASR solution uses feature extraction HMMs and language models. As RNNs can also track time series data through memory, Acoustic model can be replaced with a combination of RNN and Connectionist Temporal Classification (CTC) layers.
CTC layers solve the sequencing problemas audio signals of arbitrary length, need to be converted to text. If we use DNNs, we may not need feature extraction or separate language model at all.
According to by Baidu’s Adam Coates , additional training of a traditional ASR peaks at some accuracy. Meanwhile, DNN Solutions shine as we increase data and model size, though they are unimpressive with small data sets.

Let’s explore how to design Acoustic models with Deep Neural Networks and compare their performance.
Speech Recognition with Custom Models
Below is the gist of architecture considerations while designing a deep learning model for speech recognition.
- RNN Units: due to its effectiveness in modeling sequential data
- GRU Units: to solve exploding gradients problem while using simple RNN
- Batch Normalization: to reduce training times.
- TimeDistributed Layer: to find more complex patterns
- CNN Layer: 1D convolution layer adds an additional level of complexity
- Bidirectional RNNs: to exploit future context, process data in 2 directions
Model 1: CNN + RNN + TimeDistributed Dense


Model 2: Deeper RNN + TimeDistributed Dense


If you change the GRU units to SimpleRNN cells, then the loss can become undefined (NAN) due to the exploding gradients problem . To solve this, use gradient clipping (set ‘ clipnorm ’ argument to lower value in SGD optimizer)
Comparison of Model 1 & 2

CNN model has lower training loss but higher validation loss, which denotes overfitting. Deeper RNN performs better in validation loss as they help to better model sequential data. Bidirectional RNN may not help much as the length of sequential input is not much. We can give it a try though.
Model 3: Pooled CNN+Deep Bidirectional RNN +Time-distributed Dense
As we combine learning from both the models above, here we tie the CNNs with a deeper bidirectional RNN and add maxpooling to avoid overfitting.
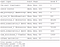
As you can see in the analysis here , Model 2 (Deep-RNN) performs the best among all 3 models. Logically hence, a better model architecture should contain deeper RNNs.
Let’s see the output of our custom model after training just 1–2 hours:
True transcription:
and of course i had my expectations and she had hers
Predicted transcription:
an do af cors i had moixitations and she had hers
True transcription:
the bogus legislature numbered thirty six members
Predicted transcription:
the bo os legeclejur nober thertysoxemers
After doing Lexical Decoding (phoneme to word) and Language Modelling the transcribed text can be made more meaningful. But to get state-of-the-art models, we need to train bigger, deeper models which would take 3–6 weeks on single GPU . Hence, it is prudent to take a pre-trained model & transfer learn to decipher multiple accents , which is the main focus of this blog.
Indian Accent Speech Recognition
Indians in different states speak English in different accents. To make the model recognize such accent variations, we can train a pre-trained speech model, on a voice dataset having spoken English recordings from many states. Here, we transfer-learn Baidu’s Deepspeech model and analyse the recognition improvement using test dataset.
- Downloaded 50+ GB of Indic TTS voice DB from IITM Speech Lab , which comprises of 10000+ spoken sentences from 20+ states (both Male and Female native speakers)
- The dataset contains the audio and its description. But to load the data to deep speech model, we need to generate CSV containing audio file path, its transcription and file size.
- Split the CSV file into 3 parts : test.csv,train.csv and valid.csv.
- Write a python program to set the frame rate for all audio files into 12000hz (deep speech model requirement)
- Clone the Baidu DeepSpeech Project 0.5.1 from here
- Execute DeepSpeech.py with appropriate parameters.

- Export_dir will contain output_graph.pbmm which you load in deepspeech.model() function.
- KenLM ToolKit is used to generate Trie file. It is required to pass in to deep speech decoder function.
- model. enableDecoderWithLM (lm_file,trie,0.75,1.85): lm_file is the .pbmm after training and trie is the output of KenLM Toolkit.
- Use deep speech decoder function to do STT.
Comparing Indian Accent English Model with Deepspeech model
To check accuracy, we used 3 metrics: WER , WACC and BLUE SCORE .

Lets plot above metrics, feeding Indian Accent Speech Data (Test Set) to both DeepSpeech pre-trained model and our trained model to compare. The 3 bins in graphs below represents low, medium and high accuracy, from left to right.
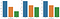
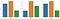
The above depiction proves that the trained model performs much better for Indian Accent Speech Recognition compared to DeepSpeech model.
- Indic TTS project is funded by DEITY, Ministry of Communication and Information Technology, GOI.
- Credits: Training DeepSpeech models using Indian voice dataset is done by my intern, Giridhar Kannappan
Conclusion
We have seen ‘Cepstral Analysis’ separate out the accent components in speech signals, while doing Feature Extraction (MFCC) in Traditional ASR. In state-of-the-art Deep Neural Networks , features are intrinsically learnt. Hence, we can transfer learn a pre-trained model with mutiple accents, to let the model learn the accent peculiarities on its own.
We have proved the case , by doing transfer learning Baidu’s DeepSpeech pre-trained model on Indian-English Speech data from multiple states. You can easily extend the approach for any root language or locale accent as well.
The complete source code of the above studies can be found here .
If you have any query or suggestion, you can reach me here
References
[1] https://www.iitm.ac.in/donlab/tts/database.php
[2] https://www.udacity.com/course/natural-language-processing-nanodegree--nd892
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK