

The streaming bridges — A Kafka, RabbitMQ, MQTT and CoAP example
source link: https://medium.com/swlh/the-streaming-bridges-a-kafka-rabbitmq-mqtt-and-coap-example-9077a598169
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Implementation
Let’s start by thinking about what we want for persistence. First, we look at the data we want to receive from IoT, and this would be the temperature and the humidity. These, in a real scenario would represent a tremendous amount of data. In this case we would be looking at some sort of big data mechanism. However, Big Data is the whole paradigm on its own. For this example our big data mechanism will be Cassandra. Another thing we need to think about is the passenger information. We want to send at periodic intervals the whole passenger data. Namely we are interested in registering their weight. It’s important to monitor that accurately as described above. This represents also a lot of information. In the same way as the meter’s information, it is also time-series data. We really aren’t that worried if in one of the periods some data is lost. We repeat sending the data of all the passengers periodically with a relatively high frequency and that information should not change that much. For this reason, we will also register the passenger information in a Big Data fashion.
Now it’s time to think about other data that we will receive with less frequency and where we actually don’t want to miss any message. Or at least, we just want more reliability. For this case we do want to benefit, mainly from transaction handling and message handling. Protocol mediation will still happen anyways, given that our messages need to go through AMQP, but this also ensures their reliability. In this article, we won’t discuss the creation of a website, but given that this would be the ultimate goal in a real-case scenario, we are going to keep that in mind. For a website, it can be better to have an ER database model implemented. For this reason we choose PostgreSQL.
To get the data to Cassandra we are going to use Apache Spark. This way we can connect Spark to our Kafka streams. We will have spark processes running in the central streaming service and we will have Kafka processes running in the train and in the bridge. We will have RabbitMQ brokers running in the bridge, the train and the vehicle to get the merchandise data where we need it to go. In the same way, we will have RabbitMQ brokers running on these last three players.
This is how this architecture looks like:
Overview of the implemented Bridge Logistics Architecture
In the following sub-chapters, we’ll go through all the relevant implementations. I will try not to repeat myself in the descriptions. This is in itself a bit of a challenge because there are very similar configurations spread around the different containers. We will go through a Top to Bottom explanation, which in other words will give us a feeling of peeling off the different layers of the different components of this architecture. This way I think we can better understand and discover how the system works and how all the moving parts are working together.
4.1. Before continuing
It is important to notice that although the implementation and the project overview looks very extended and complicated, the actual coding is actually quite far from being complicated. We will now take a dive into the code and go through every topic on by one.
4.2. Setting up RabbitMQ on the central streaming server
One of the major technological players in this architecture is RabbitMQ. We are using this technology to get the merchandise information and the sensor data. The merchandise information is of crucial importance and the rate of transmission is very low. In sensor data rate of transmission is even lower, because it only happens when trains cross the bridge. We also know that we won’t be needing to replay any of these messages. The reason being is that although we need to be sure that we load in the train gets entirely delivered at its destination, the mechanisms to prevent stealing are already in place. Containers are sealed and passengers cannot board or cross the merchandise carriages. We only need the merchandise information to have an idea of how its weight affects the bridge. In regards to the sensors, we also do not want to store the check-in/check-out data. One lost check-in/check-out data won’t make a difference between hundreds of them in the course of the day. Therefore none of this information is actually vita nor is its throughput very high.
Before configuring this, it’s important to know that we are not going to go very deep into the configuration of RabbitMQ. In spite of multiple possible configurations, we are going to keep it on a 1 to 1 basis as much as possible.
Let’s begin. In the bl-central-server/bl-central-streaming we find a Docker with the following definition:
FROM jesperancinha/je-streams:0.0.1WORKDIR /rootENV LANG=C.UTF-8RUN rabbitmq-plugins enable — offline rabbitmq_managementRUN rabbitmq-plugins enable rabbitmq_federationRUN rabbitmq-plugins enable rabbitmq_federation_managementRUN rabbitmq-plugins enable rabbitmq_shovel rabbitmq_shovel_managementCOPY entrypoint.sh /rootENTRYPOINT [“/root/entrypoint.sh”]# RabbitMQEXPOSE 5672 15672
We start off by using one image that I have created, which contains a raw installation of RabbitMQ. If you are interested in knowing more about it, then please check it out here. Before we continue, it is important to configure the management page. We will configure it offline and we will be able to do that via a webpage. Afterwards we are going to enable something called federation. This is simply said, just way of connecting two RabbitMQ brokers together. They can be close together or they can physically be located very far away. The idea behind this is that they end up working as a single broker. We need this in order to connect our RabbitMQ broker running in our train, bridge, and vehicle to our central server. We are also adding the Shovel management. This is very important because we want our messages to be exchanged automatically via our federation. Without this, messages will be stuck on the source RabbitMQ broker and will need yet another external interaction to move them to their destination RabbitMQ broker. Finally, in order to be able to visualize our webpage and allow other containers to find our broker in the central streaming service, we need to make two essential ports available. This is port 5672 and 15672. These are the RabbitMQ server port and the Web GUI (Graphic User Interface) respectively. The convention in RabbitMQ is that the relationship between these ports is a 10000 difference. In our example, if we say that our server port is 5672, then we are already implying that our GUI port is 10000 + 5672 = 15672 port.
Let’s now have a look at our entrypoint.sh. Our entry point file is very large and therefore It’s probably better to have a look at sections. First, we start our server:
#!/usr/bin/env bashrabbitmq-plugins enable rabbitmq_managementrabbitmq-server -detachedrabbitmqctl await_startup
After starting our service we still need to download a module called rabbitmqadmin. This module allows us to configure virtual-hosts, queues and exchanges, amongst other features, via the command line. Because rabbitmqadmin runs on python3, but looks for it in the /usr/bin/python, we need to create a symlink in this location to python3.
curl -S http://localhost:15672/cli/rabbitmqadmin > /usr/local/bin/rabbitmqadminchmod +x /usr/local/bin/rabbitmqadminln -s /usr/bin/python3 /usr/bin/python
We now need to think about general configurations for our RabbitMQ server. We only need to create our user. We add a test user with test as password. Then we give our user the administrator profile. Finally we set permissions to everything from the root to our newly created user.
rabbitmqctl add_user test testrabbitmqctl set_user_tags test administratorrabbitmqctl set_permissions -p / test “.*” “.*” “.*”
We will need to create federated queues. The order in which we create them doesn’t really matter. They do, however need to be running at the same time in order to be accessible. As we have seen in the general overview, we need to create 5 federations. We will create them all in the same way. In this way, we can benefit from creating a bash function to help us create the different federations. What we are going to do is to create a virtual host. Then we’ll set all permissions to it on our test user. RabbitMQ needs an exchange to receive messages. Exchanges in RabbitMQ are messages routers that distribute messages to queues via bindings and routing keys. There are many types of exchanges. For our example we will use fanout. This type of exchange only means that no routing key is actually used. This means if more queues are bound to this exchange, they will each get copy of every message delivered to the exchange. Now we can create our queue. Then we bind the queue with the exchange. Afterward we federate this queue with the upstream in the remote service. Finally, we set up the federation policy.
federate(){rabbitmqctl add_vhost bl_$1_vhrabbitmqctl set_permissions -p bl_$1_vh test “.*” “.*” “.*”rabbitmqadmin -u test -p test -V bl_$1_vh declare exchange name=bl_$1_exchange type=fanoutrabbitmqadmin -u test -p test -V bl_$1_vh declare queue name=bl_$1_queuerabbitmqadmin -u test -p test -V bl_$1_vh declare binding source=bl_$1_exchange destination=bl_$1_queuerabbitmqctl set_parameter -p bl_$1_vh federation-upstream bl_$1_upstream ‘{“uri”:”amqp://test:test@bl_’$2'_server:5672/bl_’$1'_vh”,”expires”:3600000}’rabbitmqctl set_policy -p bl_$1_vh — apply-to all bl_$1_policy “.*$1.*” ‘{“federation-upstream-set”:”all”}’}
At last, we call our function for every federation we want to create. In this case we create 5 virtual hosts, 5 exchanges, 5 queues, 5 federations and 5 federation policies.
federate train_01_merchandise train_01federate train_01_sensor train_01federate vehicle_01_sensor vehicle_01federate vehicle_01_merchandise vehicle_01federate bridge_01_sensor bridge_01tail -f /dev/null
The creation of virtual hosts, exchanges and queues are the same for the train, vehicle and bridge servers. The only difference is that in these last 3, no federation is created. Therefore, no federation policy needs to be created too.
This is how it looks for one of these federations. In this case, this is a federation for the bridge service to get the data from the presence sensor to register check-in and check-out:
RabbitMQ — Federation in detail
4.3. Setting up Kafka, MQTT and CoAP on bridge-server
In our Kafka setup we have discussed that we want to get all the meters data and the passenger data. These are high volumes of information, with very high throughput and considered to be of critical value. The meter data is critical because we want to evaluate how the weather conditions affect the bridge, and the passenger data is also critical because we want to make sure we keep track of movements in the train. The latter is critical to keep record for criminal investigation purposes or to understand how the complete weight per carriage affects the carriage itself and the train composition.
Just as in the case of our previous RabbitMQ implementation, our Kafka implementation doesn’t differ that much between the train-server and the bridge server. These are the only servers that contain running Kafka buses.
Let’s thus, dive in the Kafka implementation on the bridge server side. In folder bl-bridge-server we find our Docker file. Let’s have a look at it per subject:
FROM jesperancinha/je-streams:0.0.1WORKDIR /rootENV LANG=C.UTF-8RUN rabbitmq-plugins enable — offline rabbitmq_managementRUN rabbitmq-plugins enable rabbitmq_federationRUN rabbitmq-plugins enable rabbitmq_federation_managementRUN rabbitmq-plugins enable rabbitmq_shovel rabbitmq_shovel_management
The RabbitMQ implementation is exactly the same and we discussed it already above. This way, we can move to the following steps.
COPY bl-bridge-temperature-coap/dist /root/bl-bridge-temperature-coap/distCOPY bl-bridge-temperature-coap/node_modules /root/bl-bridge-temperature-coap/node_modulesCOPY bl-bridge-humidity-mqtt/dist /root/bl-bridge-humidity-mqtt/distCOPY bl-bridge-humidity-mqtt/node_modules /root/bl-bridge-humidity-mqtt/node_modulesCOPY entrypoint.sh /root
In these steps, we are making copies of files needed to run the humidity and temperature meter services. We’ll talk about this further in this article.
We can now finally have a look at how Kafka is being installed.
RUN rm /usr/local/etc/kafka/config/server.propertiesCOPY kafka/*.* /usr/local/etc/kafka/config/COPY zookeeper/*.* /usr/local/etc/kafka/config/COPY startKafka.sh /rootCOPY startZookeeper.sh /root
Just like before, this image is built upon an image I already made at https://bitbucket.org/jesperancinha/docker-images/src/je-streams-0.0.1/je-streams/. In this case we already have Kafka and Zookeeper installed for us. What we are doing now is just copying the configuration files for Kafka and Zookeeper to their respective setup folders. Finally we copy the startup scripts to the entry point folder.
In our final steps, we define our entry point file and make the necessary ports available.
ENTRYPOINT [“/root/entrypoint.sh”]#RabbitMQEXPOSE 5674 15674#CoAPEXPOSE 5683#MosquitttoEXPOSE 1883#KafkaEXPOSE 9090 9091 9092
This is the breakdown of all of the ports being used:
- 5674 — The communication port used to access the RabbitMQ server
- 15674 — The GUI port
- 5683 — The CoAP port. This is the entry point to a small service we are using to receive messages using CoAP protocol
- 1883 — MQTT port. In our server, we have an MQTT service. The implementation we are using is from MOSQUITTO.
- 9090, 9091 and 9092 — All Kafka brokers being used. The more we have, the more we can take advantage of the replication factor.
We have now concluded our Docker file setup. Let’s now go through our entrypoint.sh file. For the train-server, the beginning of this file doesn’t differ that much from the central stream service file, as described before. Therefore, let’s now look at how we start all our installed services:
mosquitto &node bl-bridge-temperature-coap/dist/app.js &node bl-bridge-humidity-mqtt/dist/app.js &./startZookeeper.sh &sleep 5./startKafka.sh &tail -f /dev/null
We first start Mosquitto, then the temperature service followed by the humidity service and then Zookeeper. We wait 5 seconds before starting Kaka. We can also see that startZookeeper.sh and startKafka.sh are custom scripts. Let’s now look inside of them.
First, let’s look into the zookeeper start up script:
#!/usr/bin/env bash/usr/local/etc/kafka/bin/zookeeper-server-start.sh /usr/local/etc/kafka/config/zookeeper.properties
This just means that we will start the zookeeper script with our configuration file. We’ll look into this file afterward.
Now let’s see what is happening in the startKafka.sh script:
#!/usr/bin/env bash/usr/local/etc/kafka/bin/kafka-server-start.sh /usr/local/etc/kafka/config/server0.properties &/usr/local/etc/kafka/bin/kafka-server-start.sh /usr/local/etc/kafka/config/server1.properties &/usr/local/etc/kafka/bin/kafka-server-start.sh /usr/local/etc/kafka/config/server2.properties &echo -e ‘\e[32m’Sleeping…’\e[39m’sleep 4/usr/local/etc/kafka/bin/kafka-topics.sh — create — zookeeper localhost:2181 — replication-factor 2 — partitions 3 — topic TEMPERATURE/usr/local/etc/kafka/bin/kafka-topics.sh — create — zookeeper localhost:2181 — replication-factor 2 — partitions 3 — topic HUMIDITY/usr/local/etc/kafka/bin/kafka-topics.sh — create — zookeeper localhost:2181 — replication-factor 2 — partitions 3 — topic WINDSPEED/usr/local/etc/kafka/bin/kafka-topics.sh — create — zookeeper localhost:2181 — replication-factor 2 — partitions 3 — topic WINDDIRECTION
In the first part of this script, we are starting our 3 brokers which we defined as necessary for sending Temperature and Humidity data. We then sleep for 4 seconds to allow Kafka to start. Once they are started, we can create our topics using the already started zookeeper service. We create four: TEMPERATURE, HUMIDITY, WINDSPEED, WINDDIRECTION. For this article we will only use the first two.
In the zookeeper folder we find file log4j.properties. This is just an optional configuration file necessary if we want to see and examine zookeeper logs:
log4j.rootCategory=WARN, zklog, INFOlog4j.appender.zklog=org.apache.log4j.RollingFileAppenderlog4j.appender.zklog.File=/usr/local/var/log/zookeeper/zookeeper.loglog4j.appender.zklog.Append=truelog4j.appender.zklog.layout=org.apache.log4j.PatternLayoutlog4j.appender.zklog.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %c{1} [%p] %m%n
In the kafka folder, we have another zookeeper file which is mandatory in order for zookeeper to keep its store:
dataDir=/tmp/zookeeper# the port at which the clients will connectclientPort=2181# disable the per-ip limit on the number of connections since this is a non-production configmaxClientCnxns=0
We are basically defining that zookeeper will be running on port 2181. The maxClientCnxns isn’t in use in our case, but we need to define it with value 0. This is because, since we are not using a production environment, we don’t need to limit the connection number.
Let’s now have a look at one of the Kafka broker configuration files. Please note that I’m only showing the changed and important lines of the file and not the complete file:
broker.id=0port=9092zookeeper.connect=localhost:2181zookeeper.connection.timeout.ms=6000
Here is a breakdown of these properties:
- broker.id — In the general overview, we have seen some numbers associated with the Kafka brokers. These are the broker id’s. We have to define them and we have to make sure they are unique.
- port — We need to define a port to make sure they are accessible from the outside.
- zookeeper.connect — In order to make our Kafka brokers be aware of Topics, they must connect to Zookeeper and that is specified in this file via property.
- zookeeper.connection.timeout.ms — It’s also important to configure a timeout for the zookeeper connection. By default that is 6 seconds or, as it needs to be specified in milliseconds, 6000 milliseconds.
This is how this part of the architecture looks like:
Let’s just scratch the surface on another important part of using Kafka. At this point, I’m referring to the consumer groups. Let’s have a look at how this works and how in this implementation, all of these moving parts are working together. First, we look at the following representation:
Kafka — Spark interactions in detail
In our implementation and for demo purposes, we are only using one client per Kafka cluster. Our Kafka clients are Apache Spark processes, whose main goal is to collect data. The important thing to notice in this last diagram is that we can only have one client assigned to one partition in the same consumer group. In our example we only have one consumer. Image that we had more spark replicas running at the same time. Kafka, would then assign in an evenly balanced fashion each partition to its matching consumer of the same group. A partition can have multiple consumers assigned to it, just as long as they don’t belong to the same consumer group. Our consumer group in our example is group 0.
Database ER model (PostgreSQL)
Now that we have a good understanding of how we send messages around through our architecture, it’s now time to think about what sort of data format do we want for our data exchanges? Our ER model is relatively complicated, but it’s still important to have a good grasp of it.
Bridge Logistics ER Database model for PostgreSQL
What we need to know out of this model is a few important things:
- A train is composed of different carriages
- A vehicle is composed of different containers
- A train can carry passenger and merchandise carriages
- Each passenger has weight
- The train has a weight
- Vehicle, Train and Bridge logs are registered with types INTRANSIT, CHECKIN, CHECKOUT
- A product contains data about package size and weight-
- Locations are given in precise details of longitude and latitude
Database model (Cassandra NoSQL)
For our big data model, we are taking a much simpler approach, because we just want to store data as fast as possible:
Database model for keyspace readings in Cassandra NoSQL
Data Collectors implementation
There is a lot of code involved in the implementation of the Apache Spark Data Collector Processes and the implementation of the Spring Boot Data Collector processes. At this point, I am assuming that you know enough about Spring Boot and Spring. Based on this we will go through the code implementation related to collecting the data via Apache Spark and RabbitMQ.
Let’s look at project bl-sensor-data-collector and its dependencies:
pom.xml for bl-sensor-data-collector
In here we see a very important dependency we need. This is the spring-boot-starter-amqp. With this dependency we can create configurations for RabbitMQ. It provides a seamless way to configure one rabbitMQ virtual server. In our case we are using 5. To get around this problem let’s first create a virtual abstract class common to all of these configurations and name it CollectorConfiguration.
CollectorConfiguration.java
In this class, we’ll find the common properties for all our virtual hosts. These are the username and the password. Evidently we also need to provide the username and password.
VehicleSensorCollectorConfiguration.java
Demo implementation
The actual demo is implemented with a handful of python scripts. The images at the bottom give us a representation of how this actually works in practice.
This is what the demo does. It simulates an environment where a train is running through a bridge and a bus is running through another.
- It simulates the train leaving a central station.
- It simulates a truck leaving the distribution center.
- Until they get to their respective bridge, both the train and the truck will be emitting their contents.
- The train will emit the contents of its merchandise.
- The train will also emit all the passenger information
- The bus will emit its contents as well.
- In the meantime, the bridge will be constantly emitting the data of the temperature and humidity sensors.
- The moment the truck arrives at the bridge, it won’t move if the bridge is closed.
- The truck continues its path if the train is open.
- When the bus or the train cross the place where the check-in sensors are located, they will send the location sensor information. This will be just check-in and their GPS location.
- The bridge will also send the same information. In this case it won’t send any data about the train. Only that has been a check-in.
- In the same way, the checkout will be registered for the train and the bus in the check-out location sensors.
In order to get the Demo running, please run the build.sh script. After the script finished running we should get a screen like this:

A successful build
Then, if we have Docker desktop installed and Docker running, we should be able to start our docker-compose environment with the startContainers.sh script. We should then get this result:
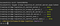
Starting docker-compose
Now let’s have look at how everything will play out when we start running our python demo scripts:
Demo implementation
At this point, we already know that Cassandra won’t be running in our docker-compose environment. We also know why. This is also the reason why we have to run our spark process from the outside. At this point at least 2 minutes should have already passed. In order to start the spark processes, let’s run the script startSpark.sh. This will start our spark collectors. Alternatively we can start these projects via Intellij. It’s easier to debug and if we want to understand everything that’s happening in more detail, maybe this could be a better option. Let’s now wait for these collectors to connect to our Kafka brokers. We know this happens when Spark lets us know that the group has joined and that the partitions have been assigned:

Connection from Spark to Kafka streams successfully made.
Let’s check that everything is running correctly. First we go to:
http://localhost:15672/#/
This is the homepage of the RabbitMQ server located in the central streaming service. We log in with username test and password test. We should get a screen like this:
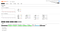
RabbitMQ homepage
If we go to Admin, we can check the status of the federations:

Federation status in the central streaming server
Now let’s try one of the other services. Let’s go to the vehicle server on:
http://localhost:15675/#/queues
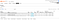
Vehicle server federations
As we can see, the queues are federated! This means that all messages coming into these queues, will be automatically sent to the central server.
Now let’s have a look at what is happening to our Spark cluster. Let’s check at that one the Spark GUI on:
http://localhost:4040/jobs/
Because we actually have two spark processes running the port allocation will be random. One GUI will be allocated on port 4040 and another one on port 4041:
http://localhost:4040/jobs/
Either way, when the jobs are running and we are retrieving our data, we should be getting the following:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK