

Convolutional Neural Networks(CNN’s) — A practical perspective
source link: https://towardsdatascience.com/convolutional-neural-networks-cnns-a-practical-perspective-c7b3b2091aa8?gi=2e4c1206e4f7
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Hello everyone,
Hoping that everyone is safe and doing well. In this blog, we will look into some concepts of CNN’s for image classification that are often missed or misunderstood by beginners (including me till some time back). This blog requires the reader to have some basic idea of how CNN’s work. However, we will cover the important aspects of CNN’s before getting deeper into advanced topics.
After this, we will look at a machine learning technique called Transfer learning and how it is useful in training a model with less data on a deep learning framework. We will train an image classification model on top of resnet34 architecture using the data that contains digitally recorded heartbeats of human beings in the form of audio (.wav) files. In the process, we will convert each of these audio files into an image by converting them to spectrograms using a popular python audio library called Librosa. In the end, we will examine the model with popular error metrics and check its performance.
CNN’s for image classification:
Neural networks with more than 1 convolution operations are called convolutional neural networks (CNN). Input of a CNN contains images with numerical values in each pixel arranged spatially along the width, height and depth (channels). The goal of the total architecture is to get a probability score of an image belonging to a certain class by learning from these numerical values arranged spatially. In the process, we perform operations like pooling and convolutions on these numerical values to squeeze and stretch them along the depth.
An image typically contains three layers namely RGB (Red, Green, Blue).
Main operations in CNN’s
Convolution operation
Convolution operation is ( w.x+b) applied to all the different spatial localities in the input volume. Using more number of convolution operations helps to learn a particular shape even if its location in the image is changed.
Mathematical Expression: x_new = w.x + b where w is the filter/kernel, b is the bias and x is part of a hidden layer output. Both w and b are different for every convolution operation applied on different hidden layers.
Example: Generally clouds are present on the top of a landscape image. If an inverted image is fed into a CNN, more number of convolutional operations makes sure that the model identifies the cloud portion even if it is inverted.
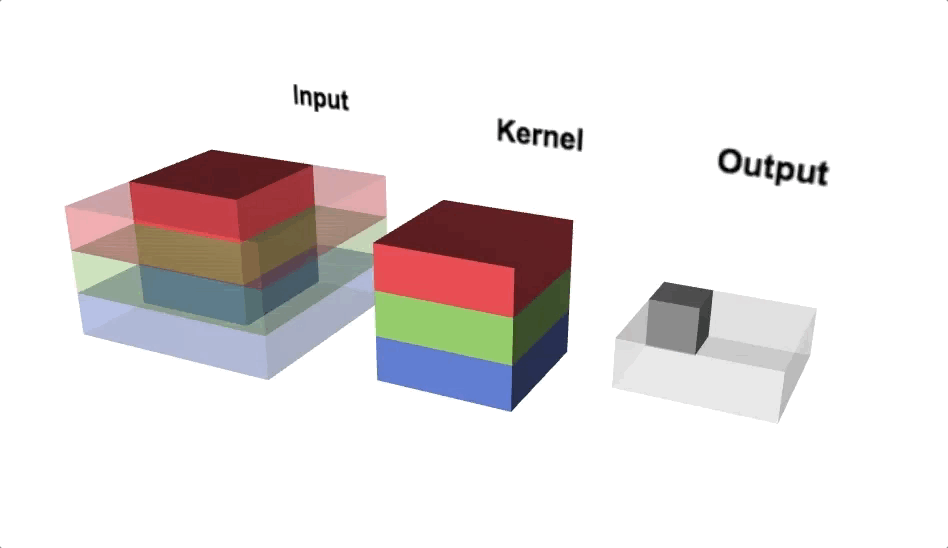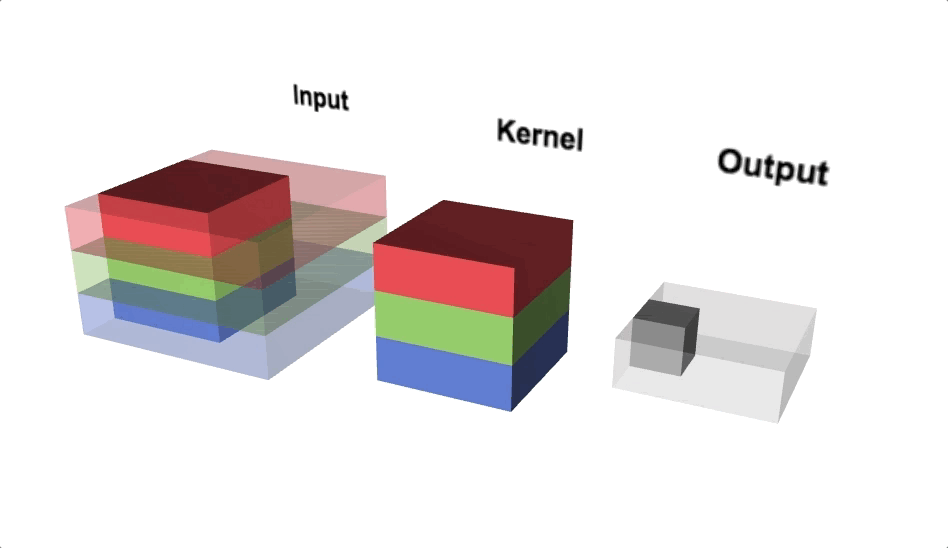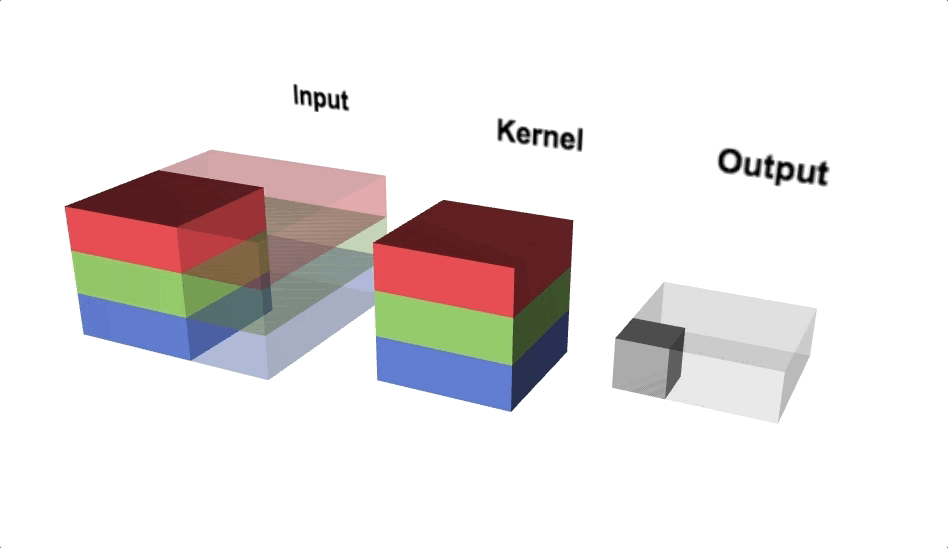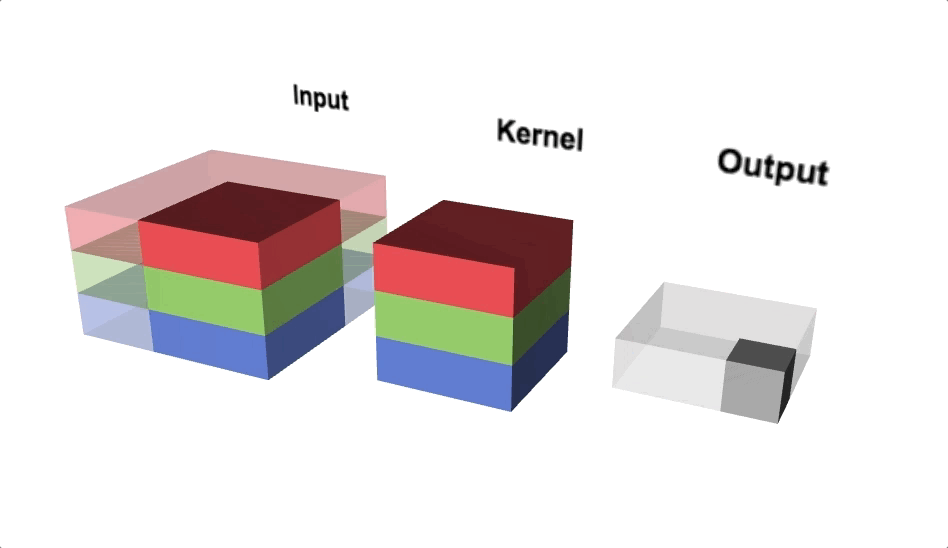
Pooling
Pooling reduces the spatial dimensions of each activation map (output after convolution operation) while aggregating the localised spatial information. Pooling helps to squeeze the output from hidden layers along height and width. If we consider maximum value within the non-overlapping sub-regions then it is called Max-pooling. Max-pooling also adds non-linearity to the model.
Activation functions
For CNN’s, ReLU is always preferred as activation function because of its simple differentiability and fastness compared to other activation functions like tanh and sigmoid. ReLU is typically followed after convolution operation.
Let’s check the time taken to calculate the gradient for each activation function:

Sometimes padding is also used in between these operations when edges of an image constitute important aspects that might be helpful while training the model. It can also be used to contain the shrinkage along height and width due to operations like pooling.
Generally, the depth of hidden layers are high as the number of filters used in a convolution operation are of high number. Number of filters are maintained high as each filter learns new features or new shapes.
Example:

Here, we have used two filters to perform convolution operation and the depth of the output is also 2. Suppose, if we are using 3 filters/kernels, one kernel might learn to identify vertical edges as initial layers can’t learn features larger than the filter size (3*3 here). Second filter might learn to identify horizontal edges and 3rd filter might learn to identify curved edges in the image.
Backpropagation
The weights (w) of every convolution operation are updated using backpropagation. Backpropagation involves calculation of gradients which in turn helps w to reach an ideal state where the error rate (or any other loss metric) is very less. In Pytorch, backpropagation is performed using torch.backward function. Mathematically, we can say that this function does something similar to operation J.v, where J is Jacobian matrix and v, is the gradient of loss w.r.t next layer. Jacobian matrix consists of partial derivatives and can be considered as a local gradient.
For a function, y = f(x) where y and x are vectors, J.v is
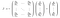
Where l is the loss function.
Batch Normalization
Batch Normalization (BN) is performed to address the issues of Internal Covariate Shift (ICF). Because of different distributions of weights in each operation, hidden layers take more time to adjust to these changes. Batch Normalization technique makes the weights of the deeper layer, learned by the neural net less dependent on the weights learned on the shallower layer and thus avoids ICF.
It is carried out at the pixel level on the outputs from hidden layers. The below diagram is an example of batch size= 3 with hidden layers of size 4*4. Originally, the batch normalization was said to be performed before applying ReLU (activation function) but later results were found that the model performs better when it was done after the activation step.

Pytorch, during training a batch of hidden layers keeps running estimates of its computed mean and variance, which are later used for normalization during evaluation/testing in that particular layer.

By default, the elements of γ are set to 1 and the elements of β are set to 0
Regularization
Regularization is introduced to keep the elements in weight matrix (w) in check and to avoid overfitting. Generally, we perform L2-Regularization in CNN’s. Dropouts are also helpful in regularizing the outputs of hidden layers by simply dropping some fully connected layer connections with some probability p. Pytorch implements this by randomly assigning zero to entire channels in a hidden layer in a batch.
Mini batches
Group of images (batches) (generally powers of 2 like 8, 16, 32) are passed into the architecture by using the power of GPU’s to run the model on top of these images independently but in parallel. Mini batches help us to minimize the number of times we are updating the weight vector without compromising on the results. Mini batches are useful to achieve faster convergence.
Mini-batch gradient descent
Weight vectors are updated after every batch using Mini-batch gradient descent. We take the average of all the gradients at the pixel level and subtract it from the weight vector to get the updated weight vector after every epoch.
There are also some gradient optimization techniques to make the process faster. ADAM is one such gradient descent optimization technique that is often used. Here, we will use ADAM optimization technique (although it is not specifically mentioned in the code below).
Transfer learning
Transfer learning is a machine learning technique in which a model uses pre-trained parameters/weights that are trained on large datasets. Transfer learning decreases the need for collecting more data and helps to run a deep learning model on small datasets.
As discussed in the earlier parts, initial layers of CNN’s are good at capturing simple and universal features (like edges, curves etc.) and deeper layers are good at complex features. So, it makes more sense to train only the parameters (weights) in the deeper layers without updating the parameters in other layers. We will follow this technique on a ResNet-34 model and check its performance.
ResNet-34 architecture:
{kind=link}
Understanding data:
The given data contains 313 audio files of digitally recorded heartbeats of human beings in .wav format. The labels of these audio files are provided in the set_b.csv file. In order to use CNN’s, we have to convert these audio files to an image format.
Fourier Transform applied on an audio signal output a signal in the time domain as input and outputs its decomposition into frequencies. Spectrograms are the visual representation of signals after Fourier transform is applied. Mel spectrograms are spectrograms with the Mel Scale as its y-axis.
Audio file:
Mel Spectrogram representation of the above audio file:

Code:
Importing necessary modules for this task
Creating a python function that creates a mel-spectrogram of every audio file and saves it in a directory
Looking at labels data
Preparing the data for classification and transformed each image to 512*512. Data is split into train and validation in 70:30 ratio. Batch size of 4 is used to parallelize the task in GPU.
Selecting the architecture to use
Defining the model and setting ‘error_rate’ as error metric. ‘error_rate’ is ( 1-accuracy)
Choosing the correct learning rate for our model
After choosing the correct learning rate we can choose to train the model using the pre-trained parameters/weights using learn.freeze() command
Updating the model using cyclical learning rate 5 times (i.e., 5 epochs)
Results on a batch of the validated set. In this batch, all our predictions are correct.
Plotting the confusion matrix

Our model performs very well in identifying murmurs and normal heartbeats. The final accuracy of the model is approximately 70% (sum of diagonal elements/sum of all the elements in the confusion matrix) which is very good in this case as the given data is imbalanced and noisy in some cases. You can find the whole code here .
Conclusion:
In this blog, we have learnt the practical aspects of building blocks of Convolutional Neural Networks (CNN’s) and why they are used. We used these concepts and built an image classification model to classify Mel-spectrograms to 3 classes (murmur, extrasystole and normal). In the end, we have analyzed the performance using the confusion matrix.
If you found this blog of any help, do share it and clap down here. It encourages me to write more blogs like this.
Thank you !!!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK