

IM服务器设计-网关接入层 - codedump的网络日志
source link: https://www.codedump.info/post/20190818-im-msg-gate/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
IM服务系列文章:
网关接入层负责维护与客户端之间的长连接,由于它是唯一一个与客户端进行直接通信的服务入口,维护着大量的客户端连接,其设计原则应该满足:
具体来说,需要考虑不少的问题:
- 用什么数据结构保存与客户端的连接?
- 如何清除死链?
- 在网关宕机的情况下如何容错?
- 服务如何降级?
以下具体展开。
简而言之,网关内部维护着一个map,其中保存着客户端相关的ID与对应连接的映射关系。
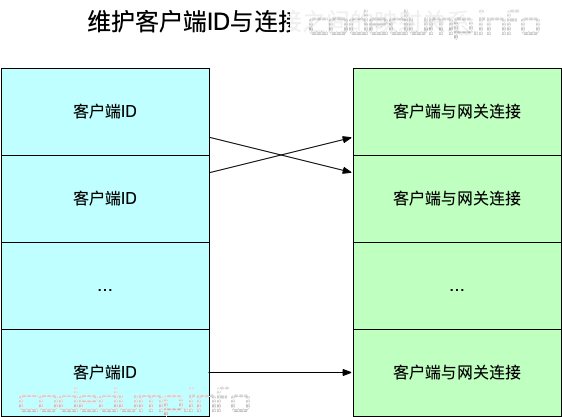
内部服务需要应答客户端时,经历如下步骤:
- 到redis中查询路由信息,即客户端连接到了哪个网关,将消息发送给该网关。
- 网关服务在上面的map中找到对应的客户端连接,将消息发送给客户端。
死链的处理
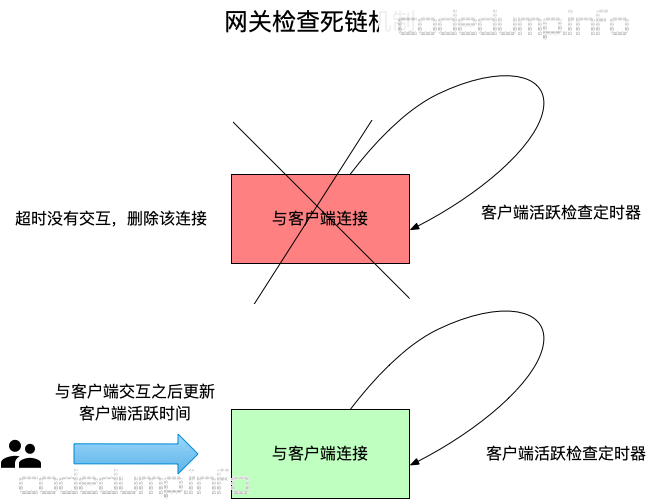
由于网关上维护着大量的客户端连接,需要通过收发心跳报的方式检查死链,具体做法是:
- 网关针对每个连上的连接,都创建一个定时器。
- 网关跟客户端的每次交互之后,网关都对应的更新一下该客户端的心跳时间为当前时间。
- 客户端内部同样也维护一个定时器,每次定时器超时时,判断当前是否已经有一段时间没有跟网关通信了,此时将发出心跳消息进行保活。
- 当该每个定时器到期时,检查客户端的心跳时间距离当前时间已经超过一个阈值了,那么将认为该客户端已经失连,将清除掉该连接。
需要注意的是,客户端的定时器应该小于网关层给每个连接加上的定时器。
网关有可能宕机,此时要考虑到这种情况下的容错处理。
这里的原则有两条:
- 客户端一旦发现前面连接的网关宕机,将尝试重连。
- 内部服务要通过网关层应答给客户端的消息,一旦发现由于网关宕机而无法发出,将直接丢弃,由客户端重新尝试重连。
以下来详细解释一下这两个原则。
客户端重连
客户端内部维护着一个发出消息的消息队列,仅在收到服务器的处理应答之后才可以从其中清除相应的消息。注意,这里每个客户端的消息ID需要做到严格递增。
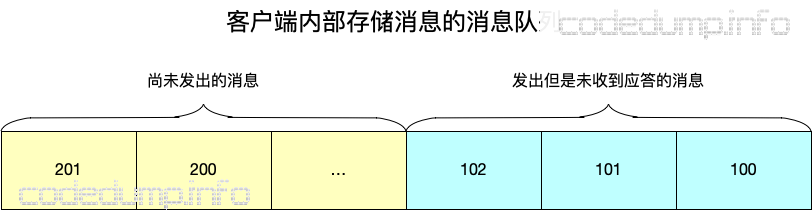
比如,上图中发出但是未收到应答的消息有三条,消息ID依次递增,分别是100、101、102。此时如果收到服务器应答消息101已经被确认处理,那么在这个序号之前的消息100以及101都可以被认为已经被服务器正常接收并且处理完毕,此时可以从消息队列中删除掉序号101之前的消息了。
反之,客户端同时还维护另外一个定时器,一段时间没有收到连接的网关消息时,将向网关发出心跳消息,如果仍然没有回复则认为网关出现异常,将重新走正常的登录流程尝试选择另外一台网关登录。重连之后,将重新发送消息队列中已经存在的消息。
当一台网关出现问题需要客户端进行重连时,还需要考虑到不要因为重连问题导致了其他网关服务器也受影响,产生雪崩效应,此时还需要考虑以下几点:
- 打散重连时间:需要进行重连的客户端,在一个时间范围内选择一个随机的时间,这样将这些客户端的重连时间打散,不至于一下子都连接上来。
- 指数退避:一次重连不上时,客户端还需要再次尝试进行多次重连,然而重连的时间需要像TCP协议那样在阻塞恢复时做指数退避,即第一次重连时间是1秒后,第二次2秒后,第三次4秒后,等等。这个策略也是为了避免由于重连导致的服务雪崩。
- 服务器保护:上面两条是客户端的重连策略,然而服务器自身也需要进行保护,当服务器判断自己当前的负载到一定程度时,将拒绝客户端的连接请求。
内部服务丢弃应答消息
同样的,内部服务也只是通过网关层与客户端进行通信,当处理了一些消息之后需要应答客户端,此时发现对应的网关已经宕机,那么应该丢弃掉这些应答消息,等待客户端重连之后重新将前面没有收到应答的消息发出来。
如果是这个处理原则的话,对应的就需要服务器的逻辑中做到“幂等性(idempotent)”了,即同一个操作,一次请求与多次请求的结果是一样的。比如,逻辑服务器可以通过客户端的消息ID来判断这条消息之前是否已经被处理过,如果是的话可以直接忽略处理应答处理即可。
每个网关服务器可以容纳的长连接总数是固定的,到了一定程度系统资源就消耗的差不多了,应答的延迟也提高了。所以,网关层还需要考虑到服务的可用性。
比如,可以向管理网关的服务器上报如下数据:
- 当前维护的连接数量。
- 当前应答延迟指标,90%的延迟到多少,99%的应答延迟到多少,等等。
- 当前系统资源的消耗情况,比如CPU占用、内存占用等等。
这样,可以有依据来判断该网关是否还能继续接收新的连接,如果不能接收连接可以返回一批当前可用的其他网关服务列表给客户端重新发起连接,同时将当前不可用的网关从返回给客户端的网关列表中删除,这样下次就不会再来这个网关进行连接。
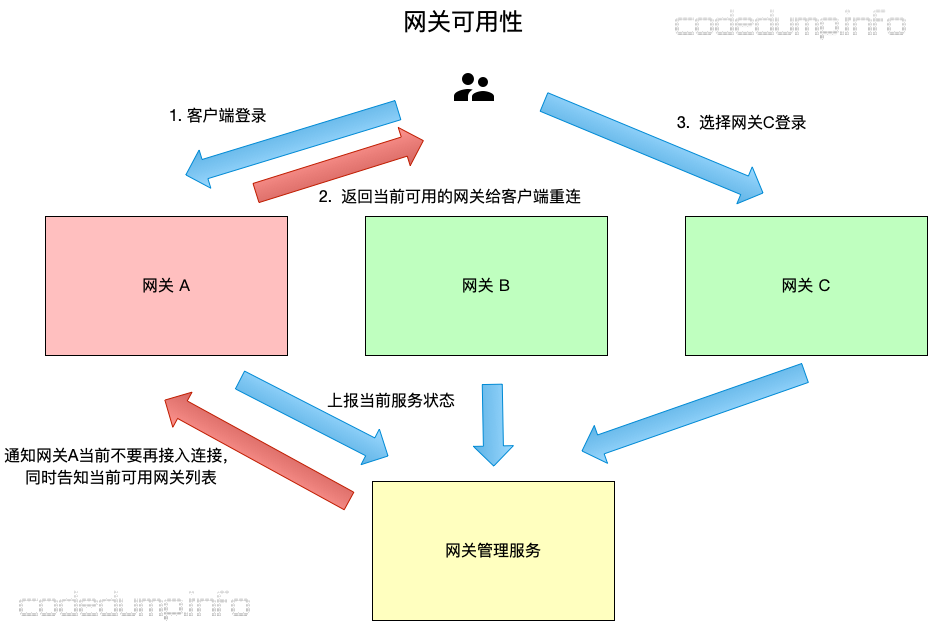
如上图中,有如下步骤:
- 网关都向网关管理服务上报自己当前的服务状态,管理服务发现网关A已经接近服务极限,此时将通知网关A此时不能再接收新的连接,同时还告知当前可用的网关B和C地址。
- 客户端向网关A发起请求,此时网关A拒绝该连接请求,并且返回网关B和C的服务列表给客户端。
- 客户端选择网关C进行连接。
可以看到,这实际上是“服务降级”的一种做法。
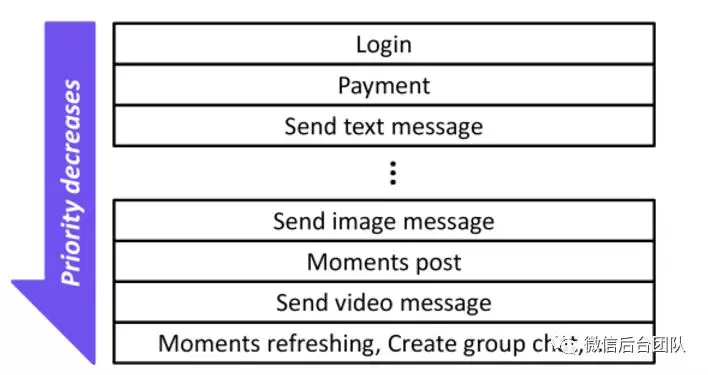
在某台网关服务降级之后,还可以针对具体的服务来进行优先级排列,即在当前负载的情况下,优先处理哪一类的客户端请求,而更低优先级的请求可以先不处理,比如微信在DAGOR论文中阐述了微信内部的服务优先级:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK