

k8s中安装部署alertmanager-姜伯洋的博客
source link: https://blog.51cto.com/13520772/2485126
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

k8s中安装部署alertmanager
准备镜像:
[root@hdss7-200 ~]# docker pull docker.io/prom/alertmanager:v0.19.0
v0.19.0: Pulling from prom/alertmanager
8e674ad76dce: Already exists
e77d2419d1c2: Already exists
fc0b06cce5a2: Pull complete
1cc6eb76696f: Pull complete
c4b97307695d: Pull complete
d49e70084386: Pull complete
Digest: sha256:7dbf4949a317a056d11ed8f379826b04d0665fad5b9334e1d69b23e946056cd3
Status: Downloaded newer image for prom/alertmanager:v0.19.0
docker.io/prom/alertmanager:v0.19.0
[root@hdss7-200 ~]# docker images|grep alert
prom/alertmanager v0.19.0 30594e96cbe8 7 months ago 53.2MB
[root@hdss7-200 ~]# docker tag 30594e96cbe8 harbor.od.com/infra/alertmanager:v0.19.0
[root@hdss7-200 ~]# docker push harbor.od.com/infra/alertmanager:v0.19.0
The push refers to repository [harbor.od.com/infra/alertmanager]
bb7386721ef9: Pushed
13b4609b0c95: Pushed
ba550e698377: Pushed
fa5b6d2332d5: Pushed
3163e6173fcc: Mounted from infra/prometheus
6194458b07fc: Mounted from infra/prometheus
v0.19.0: digest: sha256:8088fac0a74480912fbb76088247d0c4e934f1dd2bd199b52c40c1e9dba69917 size: 1575准备资源配置清单:
[root@hdss7-200 alertmanager]# cat cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: infra
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxx'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '[email protected]'
send_resolved: true
[root@hdss7-200 alertmanager]# cat dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: alertmanager
namespace: infra
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com/infra/alertmanager:v0.19.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
imagePullSecrets:
- name: harbor
[root@hdss7-200 alertmanager]# cat svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: infra
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 9093配置告警规则:
[root@hdss7-200 alertmanager]# cat /data/nfs-volume/prometheus/etc/rules.yml
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"应用资源配置清单:
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/cm.yaml
configmap/alertmanager-config created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/dp.yaml
deployment.extensions/alertmanager created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/svc.yaml
service/alertmanager created容器启动报错:
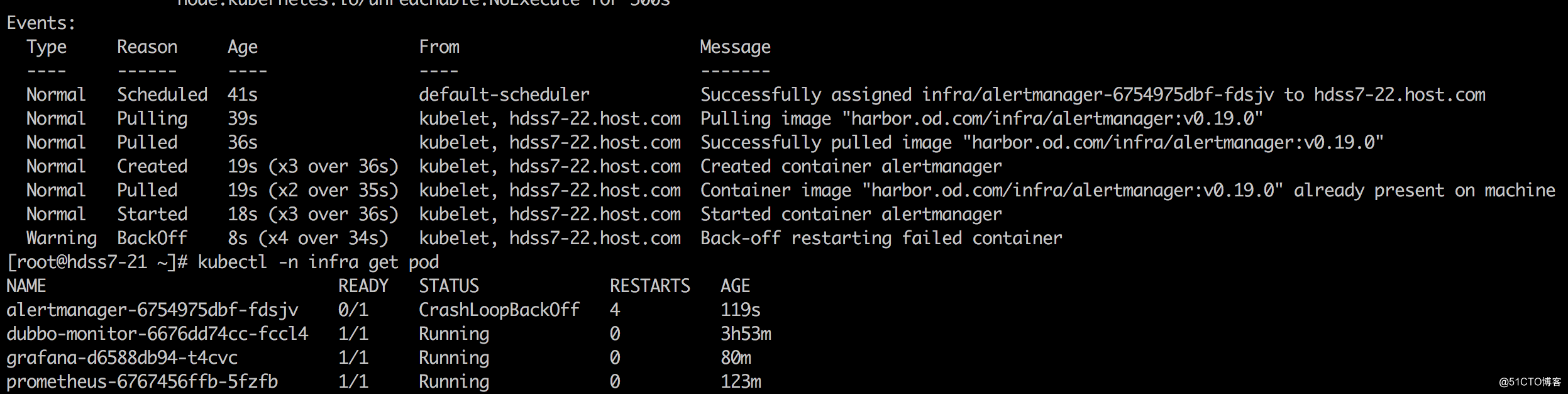
容器的logs:
[root@hdss7-21 ~]# kubectl logs -f alertmanager-6754975dbf-mjgb8 -n infra
level=info ts=2020-04-06T08:13:43.280Z caller=main.go:217 msg="Starting Alertmanager" version="(version=0.19.0, branch=HEAD, revision=7aa5d19fea3f58e3d27dbdeb0f2883037168914a)"
level=info ts=2020-04-06T08:13:43.281Z caller=main.go:218 build_context="(go=go1.12.8, user=root@587d0268f963, date=20190903-15:01:40)"
level=warn ts=2020-04-06T08:13:43.282Z caller=cluster.go:154 component=cluster err="couldn't deduce an advertise address: no private IP found, explicit advertise addr not provided"
level=error ts=2020-04-06T08:13:43.284Z caller=main.go:242 msg="unable to initialize gossip mesh" err="create memberlist: Failed to get final advertise address: No private IP address found, and explicit IP not provided"0.19.0版本的可能存在一些问题,将镜像版本回退至0.14.0,启动正常:
[root@hdss7-200 alertmanager]# docker pull docker.io/prom/alertmanager:v0.14.0
v0.14.0: Pulling from prom/alertmanager
Image docker.io/prom/alertmanager:v0.14.0 uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/
65fc92611f38: Pull complete
439b527af350: Pull complete
a3ed95caeb02: Pull complete
f65042d2fee2: Pull complete
282a28c3341d: Pull complete
f36e0769f073: Pull complete
Digest: sha256:2ff45fb2704a387347aa34f154f450d4ad86a8f47bcf72437761267ebdf45efb
Status: Downloaded newer image for prom/alertmanager:v0.14.0
docker.io/prom/alertmanager:v0.14.0
[root@hdss7-200 alertmanager]#
[root@hdss7-200 alertmanager]#
[root@hdss7-200 alertmanager]# docker images|grep alert
prom/alertmanager v0.19.0 30594e96cbe8 7 months ago 53.2MB
harbor.od.com/infra/alertmanager v0.19.0 30594e96cbe8 7 months ago 53.2MB
prom/alertmanager v0.14.0 23744b2d645c 2 years ago 31.9MB
[root@hdss7-200 alertmanager]# docker tag 23744b2d645c harbor.od.com/infra/alertmanager:v0.14.0
[root@hdss7-200 alertmanager]# docker push harbor.od.com/infra/alertmanager:v0.14.0
The push refers to repository [harbor.od.com/infra/alertmanager]
5f70bf18a086: Mounted from infra/dubbo-monitor
b5abc4736d3f: Pushed
6b961451fcb0: Pushed
30d4e7b232e4: Pushed
68d1a8b41cc0: Pushed
4febd3792a1f: Pushed
v0.14.0: digest: sha256:77a5439a03d76ba275b9a6e004113252ec4ce3336cf850a274a637090858a5ed size: 2603
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/dp.yaml
deployment.extensions/alertmanager configured
[root@hdss7-21 ~]# kubectl -n infra get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-5d46bdc7b4-mpwd9 1/1 Running 0 16s 172.7.21.7 hdss7-21.host.com <none> <none>
dubbo-monitor-6676dd74cc-fccl4 1/1 Running 0 4h6m 172.7.21.14 hdss7-21.host.com <none> <none>
grafana-d6588db94-t4cvc 1/1 Running 0 93m 172.7.22.7 hdss7-22.host.com <none> <none>
prometheus-6767456ffb-5fzfb 1/1 Running 0 136m 172.7.21.3 hdss7-21.host.com <none> <none>在prometheus配置文件中追加配置:
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"值得注意的是,prometheus在实际生产中,我们能不重启POD则不重启,因为占用资源较多,容易拖垮集群,所以我们可以这样平滑加载:
[root@hdss7-21 ~]# kubectl -n infra get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-5d46bdc7b4-mpwd9 1/1 Running 0 16s 172.7.21.7 hdss7-21.host.com <none> <none>
dubbo-monitor-6676dd74cc-fccl4 1/1 Running 0 4h6m 172.7.21.14 hdss7-21.host.com <none> <none>
grafana-d6588db94-t4cvc 1/1 Running 0 93m 172.7.22.7 hdss7-22.host.com <none> <none>
prometheus-6767456ffb-5fzfb 1/1 Running 0 136m 172.7.21.3 hdss7-21.host.com <none> <none>
[root@hdss7-21 ~]# ps -ef |grep prometheus
root 7292 22343 0 16:30 pts/0 00:00:00 grep --color=auto prometheus
root 12367 12349 6 14:09 ? 00:09:26 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.min-block-duration=10m --storage.tsdb.retention=72h
root 24205 24186 1 15:35 ? 00:00:47 traefik traefik --api --kubernetes --logLevel=INFO --insecureskipverify=true --kubernetes.endpoint=https://10.4.7.11:7443 --accesslog --accesslog.filepath=/var/log/traefik_access.log --traefiklog --traefiklog.filepath=/var/log/traefik.log --metrics.prometheus
[root@hdss7-21 ~]# kill -SIGHUP 12367
[root@hdss7-21 ~]# ps -ef |grep prometheus
root 7855 22343 0 16:30 pts/0 00:00:00 grep --color=auto prometheus
root 12367 12349 6 14:09 ? 00:09:29 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.min-block-duration=10m --storage.tsdb.retention=72h
root 24205 24186 1 15:35 ? 00:00:47 traefik traefik --api --kubernetes --logLevel=INFO --insecureskipverify=true --kubernetes.endpoint=https://10.4.7.11:7443 --accesslog --accesslog.filepath=/var/log/traefik_access.log --traefiklog --traefiklog.filepath=/var/log/traefik.log --metrics.prometheus查看alert:
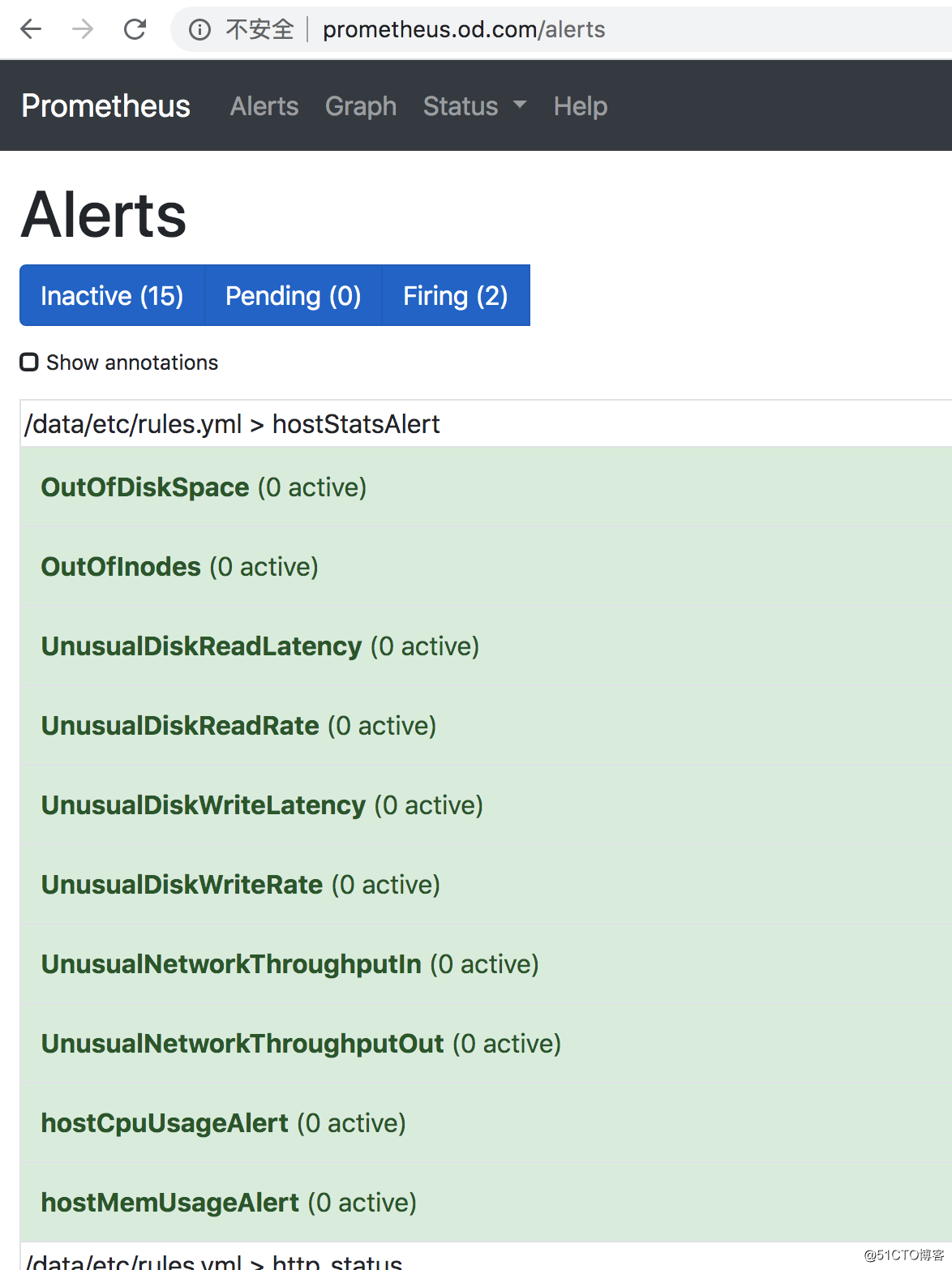
Recommend
-
137
在前面一文Kubernetes使用Prometheus搭建监控平台中我们知道了怎么使用Prometheus来搭建监控平台,也了解了grafana的使用。这篇文章就来说说报警系统的搭建,有人说报警用grafana就行了,实际上grafana对报警的支持真的很弱,而Prometheus提供的报警系统就强大很多...
-
60
企业中,rsync+inotify实现实时同步备份的部署流程
-
72
haproxy对于大型web网站的高并发负载均衡支持的非常好,而且支持从4层到7层的网络交换
-
80
docker容器虚拟化技术相对于KVM这种平台化虚拟技术更加轻量级,同时也更加高效,具有很强的移植性,对于大量密集部署应用有着非常高的效率
-
41
-
37
Promethous+Alertmanager+Grafana监控技术栈如下:Prometheus(最新版):基于TSDB的微服务指标采集&报警;Alertmanager:报警服务;Grafana(>=5.x):监控报表展示。一、软件部署1.1Prometheus安装#wgethttps://github.com/prometheus/prometheus/releases/...
-
23
zookeeper管理平台
-
3
Promethues官网:Prometheus介绍一、Prometheus介绍Prometheus是一个开源的系统监控和报警系统...
-
7
获取yaml文件 # 由已经启动的StatefulSet获取出的yaml文件: # kubectl get statefulsets.apps -n elastic-system lit-es-lit -o yaml apiVersion: apps/v1 kind: StatefulSet metadata: creationTimestamp: "2022-08-...
-
7
1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64 硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘30GB或更多 可以访问外网,需要拉取镜...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK