

基于 B+ Tree 的索引实现 | CS Pro
source link: https://cspro.xyz/database/2/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Mar 26, 2020
基于 B+ Tree 的索引实现
大量的数据在磁盘中存储后,如何高效地对部分数据进行检索,此时就必须要用到索引了。就像翻阅一本书时,通过目录就可以定位到要查阅的内容在书中的哪一页,这里的目录就相当于数据库中的索引。如何实现数据库索引,选用怎样的数据结构,直接影响着数据库的查询效率。本文会通过介绍 B Tree 的实现,来引出数据库索引最广泛采用的数据结构 B+ Tree。
在数据库中,索引大体上分分为两类,基于值的顺序排序的顺序索引和散列索引,关于散列索引后续文章将会进行介绍。顺序索引大体上会有聚簇索引和辅助索引两种:
- 聚簇索引:包含记录的文件按照某个 key 制定的顺序排序,这个 key 就是聚簇索引,也被称为主索引,也就是通常所说的主键。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚集索引。
- 辅助索引:某个 key 指定的顺序与文件记录的物理顺序不同,这个 key 就是辅助索引,物理顺序是按照聚簇索引的顺序排列的。不同的数据库的辅助索引实现方式略有不同,比如 InnoDB 中的辅助索引在叶子节点中并不存储实际的数据,只会包含主索引的值。
不管是聚簇索引还是辅助索引,它们的数据结构都是使用 B+ Tree 进行管理。我们先来介绍 B Tree,以便于更好地理解 B+ Tree 的原理。
B Tree
B Tree 是一种树状结构,所以它肯定存在根节点、子节点和叶子节点。B Tree 作为一种自平衡的树状结构,它的根节点到每个叶子节点的高度都是一致的,也就意味着它所有的叶子节点都处于相同的高度。
在 B Tree 中,我们假设它的度(degree)为 n,也就是说它的一个节点中最多可以有 n 个子节点,那么它的一个节点中最多的元素个数为 n - 1 。为了保证 B Tree 的平衡性,B Tree 中每个节点的个数是有限制的。最多的元素限制刚刚说过为 n - 1,而对于根节点的话,要求其中的元素个数最少为 1 个(这个当然要这么规定…),而非根节点的元素个数最少要为 ⎡n/2⎤- 1,即 n / 2 的向上取整结果再减 1。为了满足元素个数的限制,在插入或者删除数据时,B Tree 可能会不断进行节点的合并和分裂。一棵完整的 B Tree 可能如下图所示,它的 degree 为 3,即每个节点最多可以容纳 2 个元素,最少需要 1 个元素:
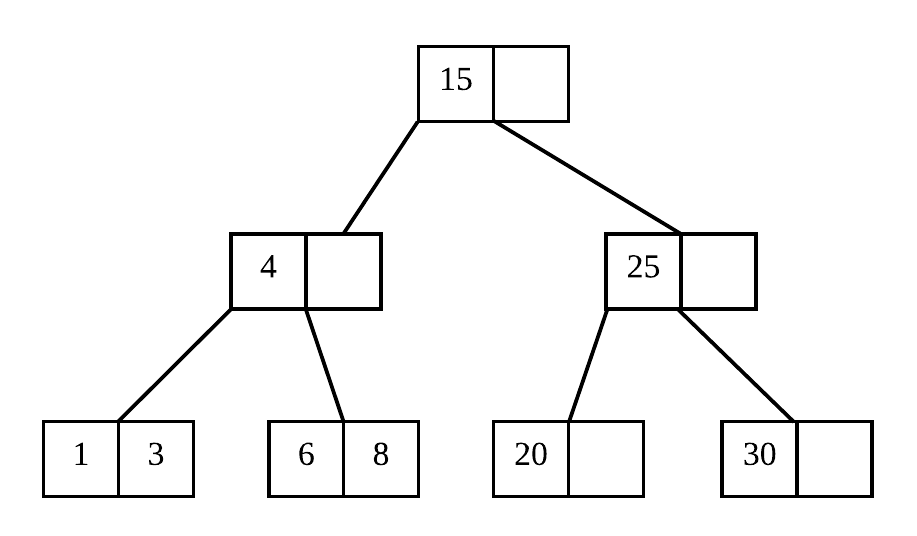
如果我们要在 B Tree 上查找某个元素,从 B Tree 的根节点开始,先在节点内部查找,节点中若没有找到的话,则根据元素所在的范围定位到子节点,然后重复以上步骤,直到找到所需元素或者查找结束。由于 B Tree 到每个根节点的高度都是一致的,因此在 B Tree 上查找的平均复杂度为 O(log(n)x),其中 n 为 B Tree 的 degree(即节点最多的子节点个数),x 为 B Tree 总元素个数。
在某一个节点内查找元素的话,可以顺序查找,也可以采用二分法进行查找。由于在实际数据库中映射到每一个节点是一个 page 单位(可以参考文章数据库中数据的组织形式),因此在一个 page 内做顺序查找的效率相比二分查找的效率并不会降低很多。
我们直接以一个例子来演示一下 B Tree 是如何插入数据的。比如上图中的 B Tree,degree 为 3,即每个节点最多允许有 3 个元素,非根节点和根节点最少要求 1 个元素。此时,我们需要插入数据 41,那么先按照上文所述的查找方法查找到要插入的节点位置(图片中标注的节点),我们发现该节点依然有剩余空间,那么直接将数据 41 插入即可。
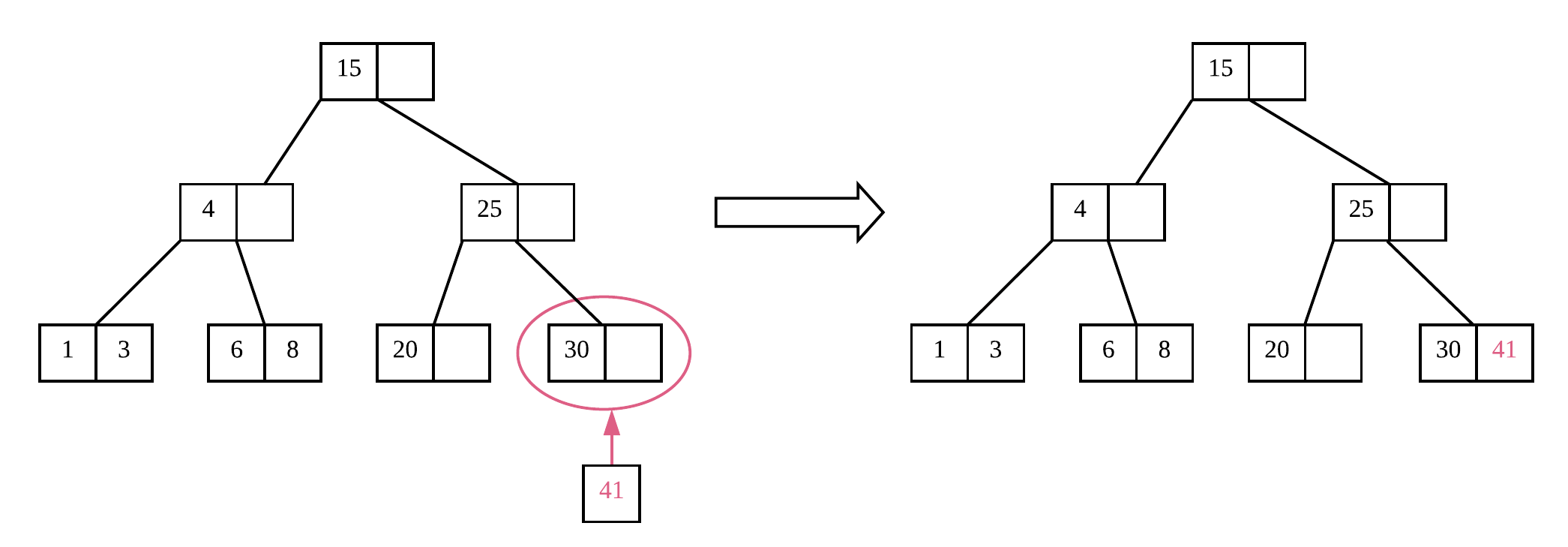
紧接着,我们要继续插入数据 45,按照如下方法:
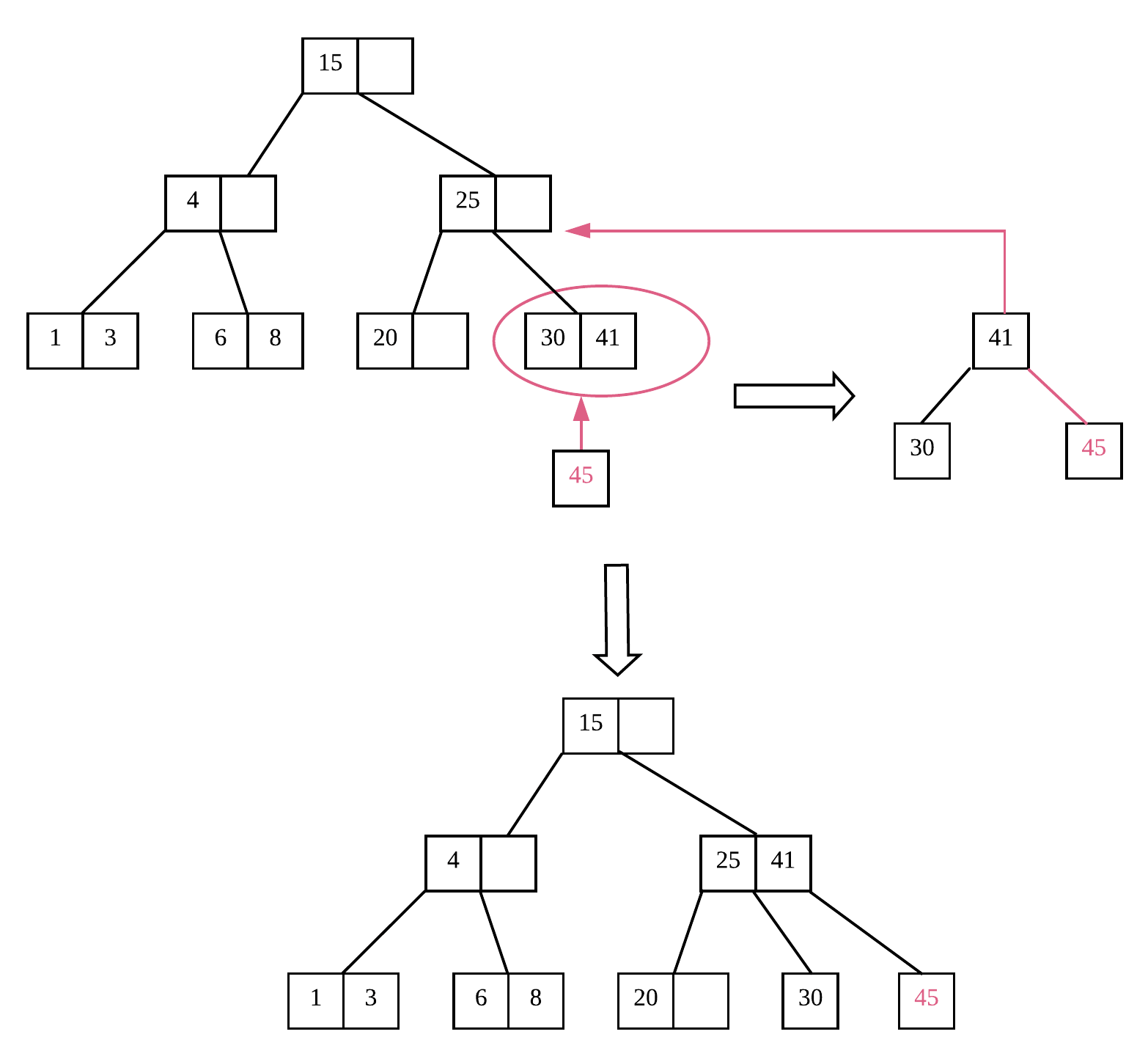
- 依然进行查找操作,找到了要插入的节点位置(下图中标注的节点);
- 我们发现该节点空间已满,不再允许继续插入数据,此时要发生节点分裂;
- 要插入的节点按照排序以中间元素均等分为两个节点,比如节点内元素为 n,中间元素为 k,则分为 (0, k-1) 即 (k+1, n) 两个节点,再将 k 上溢与父节点合并。如上图所示,原节点分为两个节点,并同时发生上溢操作;
- 将数据 41 向上与父节点进行合并,此时发现父节点依然有空余的空间,则直接插入父节点,至此插入结束。
我们发现在插入数据过程中,将某个节点分裂为了两个节点,而要插入的数据发生了上溢插入到了父节点。假设,此时父节点也已达元素个数上限,那么同样,该父节点也要进行分裂,再次发生上溢,直到将数据插入成功为止。因此我们可以想象,如果上溢行为一直发生,直接到达根节点,将根节点一分为二并继续上溢,此时整个 B Tree 就会发生变化,整个树的高度因为上溢的行为而加 1。
在 B Tree 中删除数据比较复杂,但是原理也很好理解,结合 B Tree 节点元素个数的限制,当删除节点内数据之后不满足条件的话,进行节点的合并直到满足元素个数限制为止。在这里分为两种情况:
若该元素处于非叶子节点中:
- 找到该元素的先驱元素或者后继元素,也就是找到整颗树中比该元素小或者大的最近的一个元素,用该元素直接覆盖要删除元素的位置;
- 将该先驱元素或者后继元素从之前的位置中删去即可,删除操作结束。在这里要知道的一点就是先驱元素或者后继元素肯定是位于叶子节点之上的。
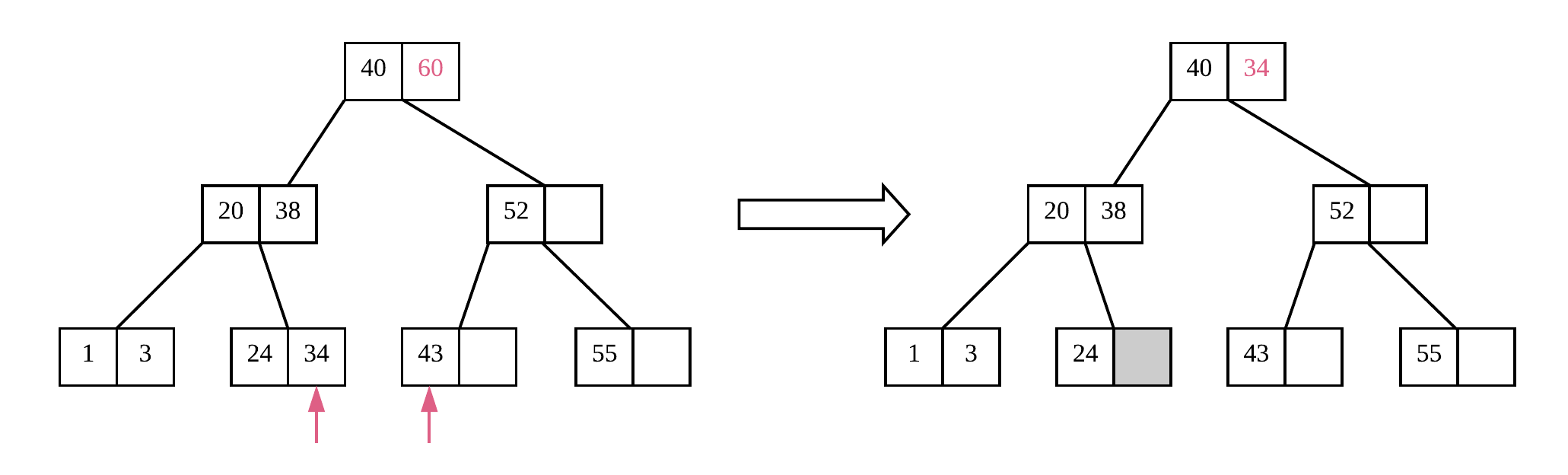
比如上图中,我们需要删除元素 60,它位于非叶子节点。我们找出它的前驱节点 34 或者后继节点 43,用其中之一覆盖要删除元素的位置(这里我们选择了 34),然后再删除 34 原本的位置即可。
若该元素处于叶子节点中,且该节点删除一个元素后,依然能满足元素最少个数的限制,那么直接删除即可:
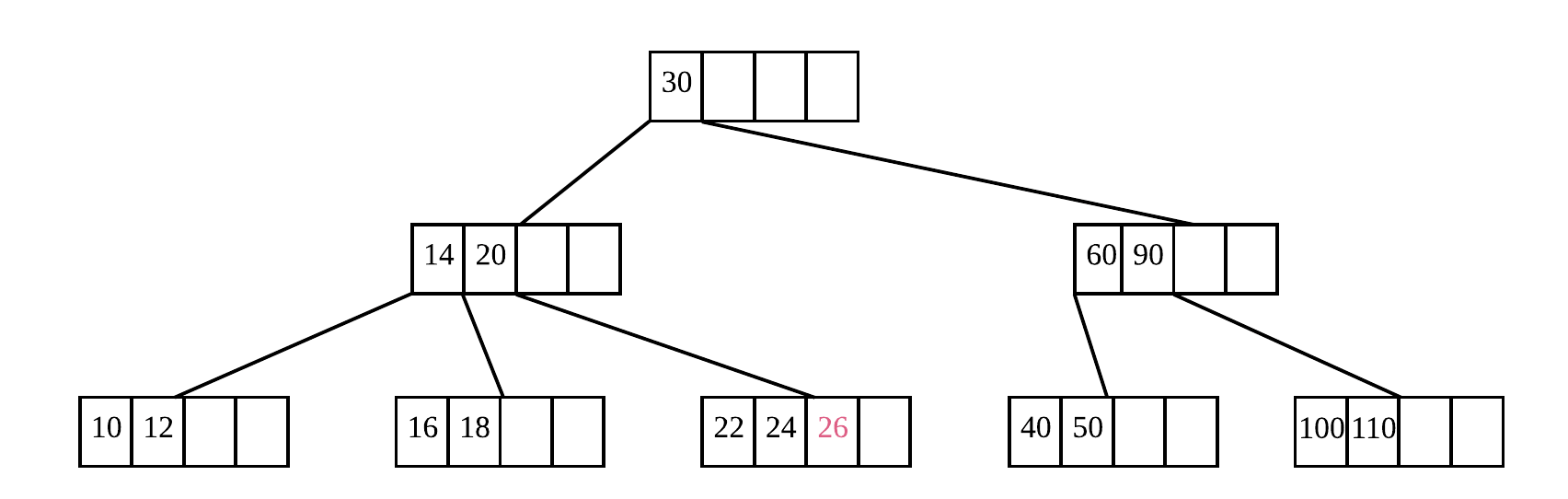
比如上图中,数的 degree 为 5,也就是说每个节点内的最少元素个数为 2,因此删除 26 之后不影响元素数量限制,直接删除。
若直接删除该元素会导致不满足节点内元素限制,那么继续继续执行以下判断。
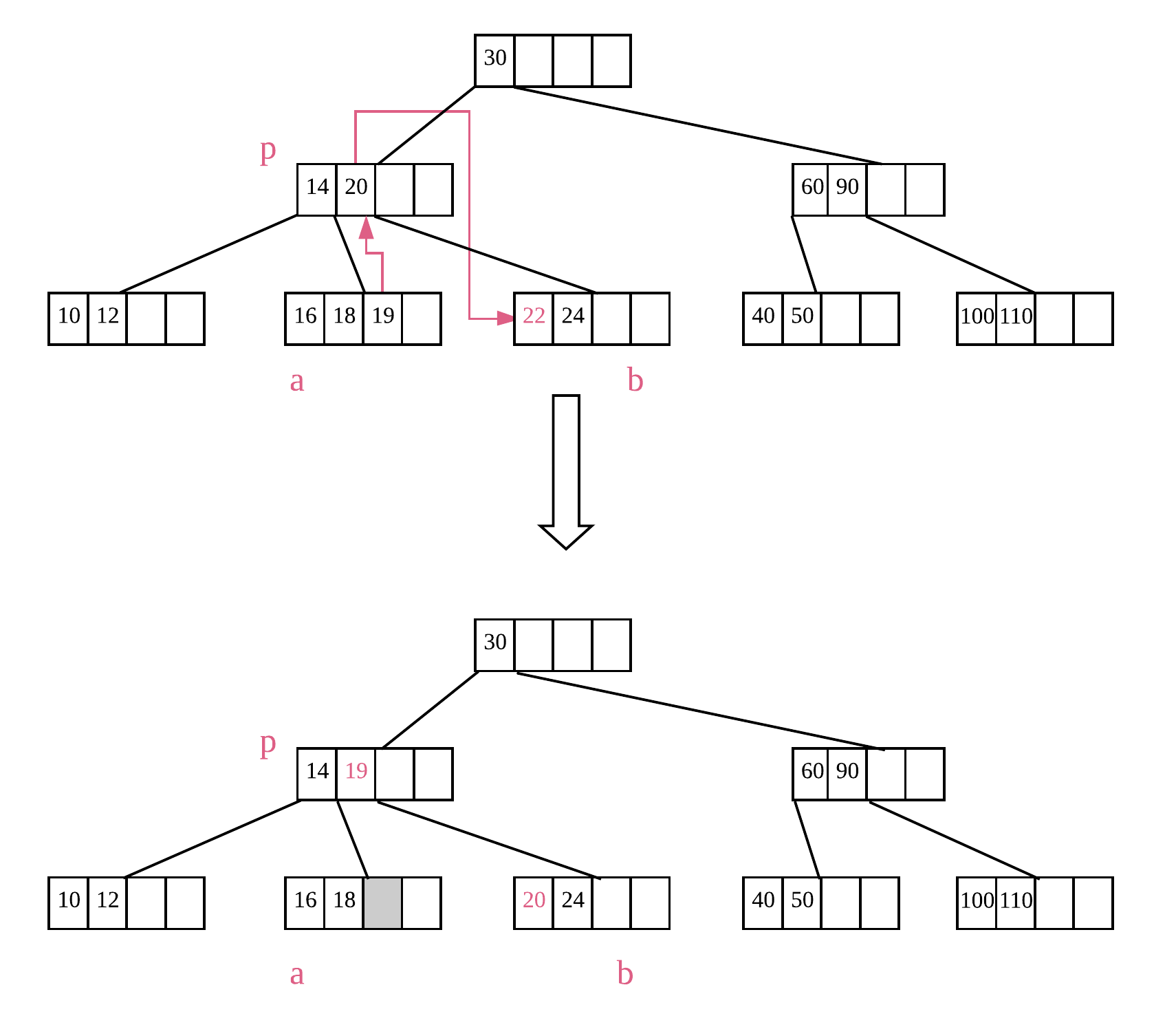
查找该叶子节点相邻的兄弟节点是否可以删除一个元素之后仍然满足节点元素个数的限制,满足的话则向父节点借一个元素。比如上图中要删除 22,其左边的兄弟节点在移出一个元素后的元素个数为2,仍然满足要求。此时,将父节点 p 中的中间位置元素 20 借下来放置于节点 b 中删除 22 之后的位置,然后用兄弟节点 a 中的元素 19 填充父节点 p 中空余的位置,即可完成删除,结果如上图所示。
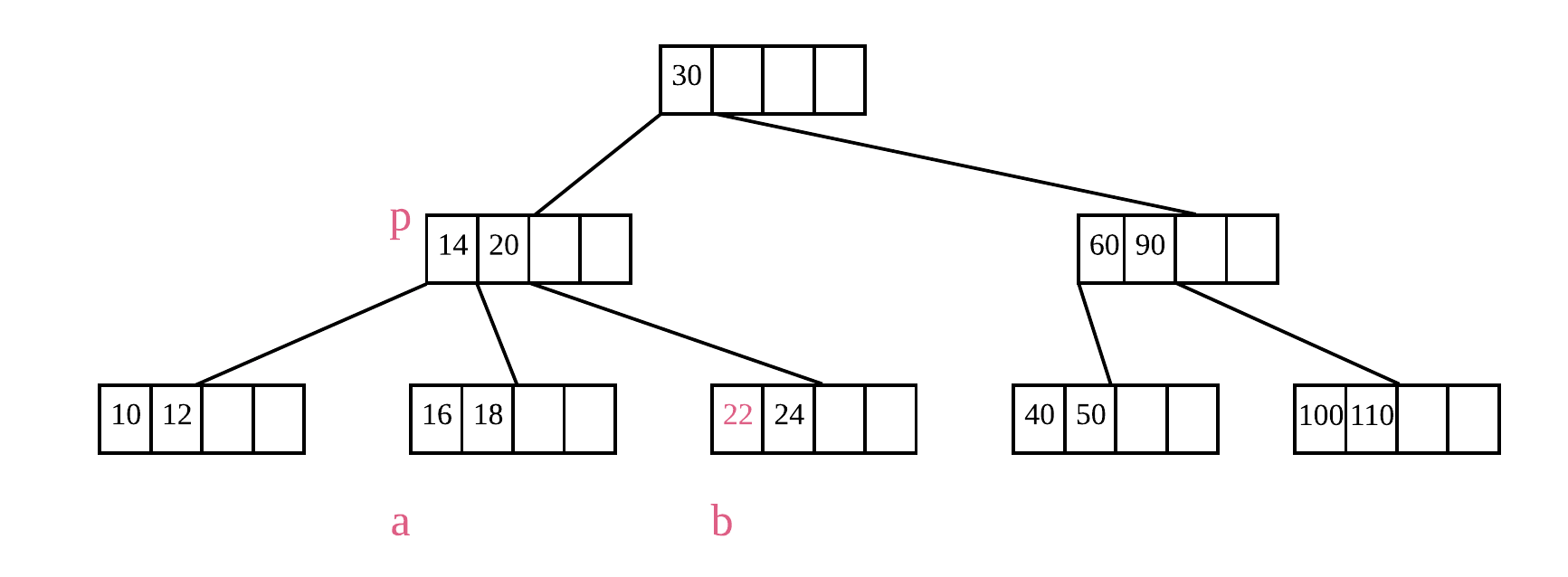
如果要删除的节点的兄弟节点不能够继续减少元素,那就需要对节点进行合并操作了。比如上图中,要删除 b 节点中的 22,而其兄弟节点 a 无法继续减少元素,因此要将节点 a 和 b 进行合并,并将父节点 p 中位于节点 a 和 b 中间的元素移下来,也就是删除 b 中的 22,将 p 中的 20 移动到 22 原本的位置,再将 a 和 b 合并,结果如下图所示:
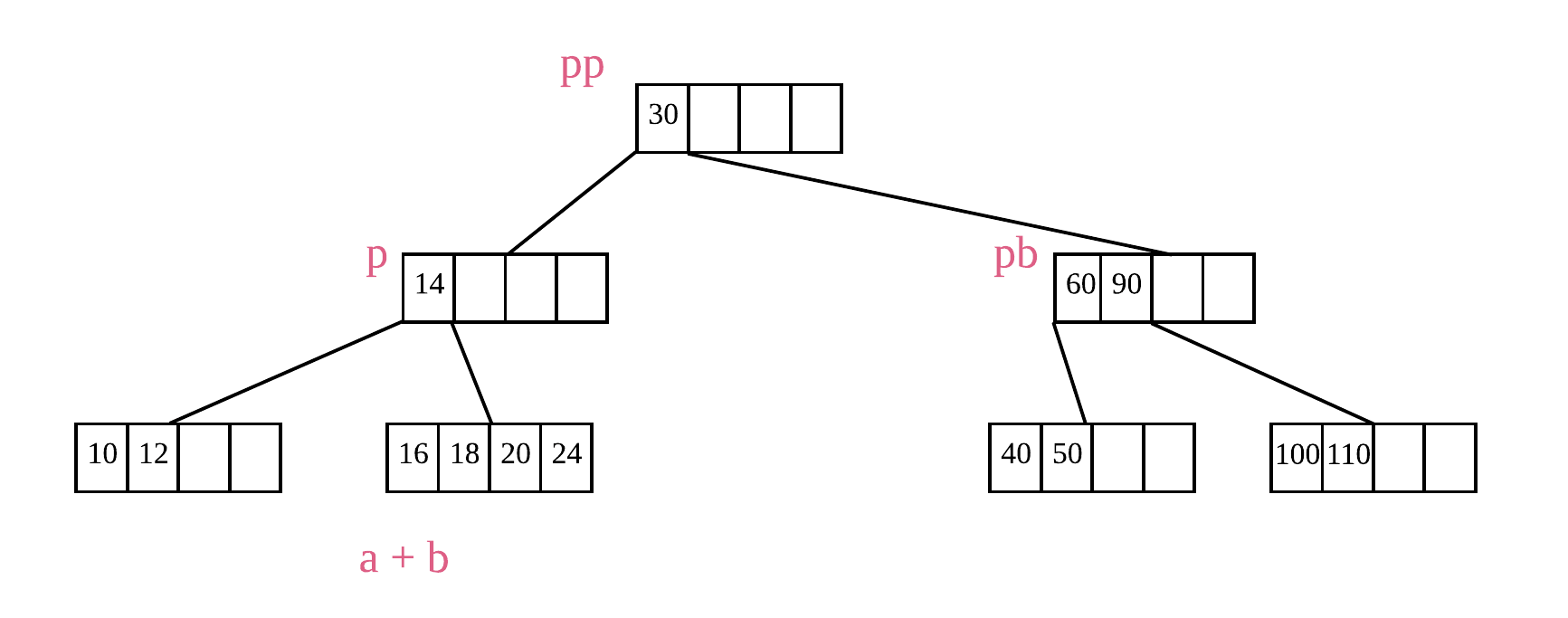
但此时并不意味着完成所有操作了,因为父节点 p 只剩下一个元素,不满足最少元素个数限制。因此,重复上述步骤,节点 p 先看其兄弟节点 pb 能不能减少一个元素,发现不行,那就进行 p 与 pb 的合并,将父节点 pp 中的元素下移。但是 pp 节点只有一个元素,下移之后整棵树的高度直接减少 1,结果如下图所示:
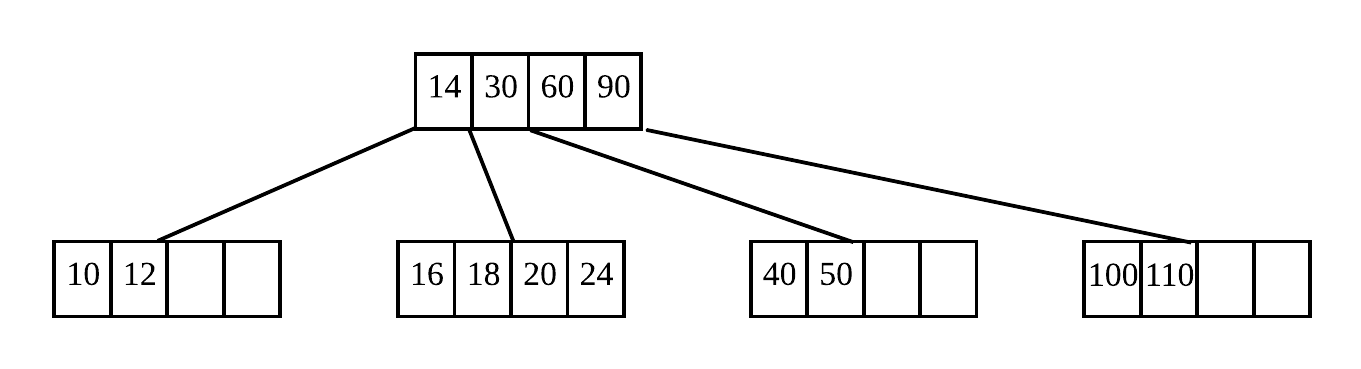
综上我们可以发现,B Tree 为了维持自己的平衡,在发生数据更新时,不断进行着节点的分裂与合并操作,分裂与合并伴随着上溢和下溢的情况发生,并直接可能影响整个数的高度发生改变。
B+ Tree
以上是关于 B Tree 的实现逻辑,但是在关系型数据库中并不会直接使用 B Tree,而是使用它的另外一种结构 B+ Tree,它同 B Tree 的平衡逻辑以及节点更新逻辑基本一致,都是不断通过节点的分裂与合并维持着自身的平衡,但是,它们仍然有一些不同之处:
- B Tree 中所有节点,包括叶子节点和非叶子节点,包含了全部的数据信息。也就是说,在 B Tree 上查找某条数据,这条数据可能会位于整个树中的各个节点中。而 B+ Tree 不同,B+ Tree 中的叶子节点就包含了全部的数据信息,也就是说在 B+ Tree 中查找某条数据,这条数据可能会在叶子节点和非叶子节点中重复存储,但是最终一定会在叶子节点中找到它。
- B+ Tree 的所有叶子节点是有序的,且叶子节点按照从小到大的排序顺序构成了一个链表结构(一般都是双向链表),结合上一条,按照链表遍历完所有叶子节点也就能够完成顺序遍历整棵树中包含的数据。
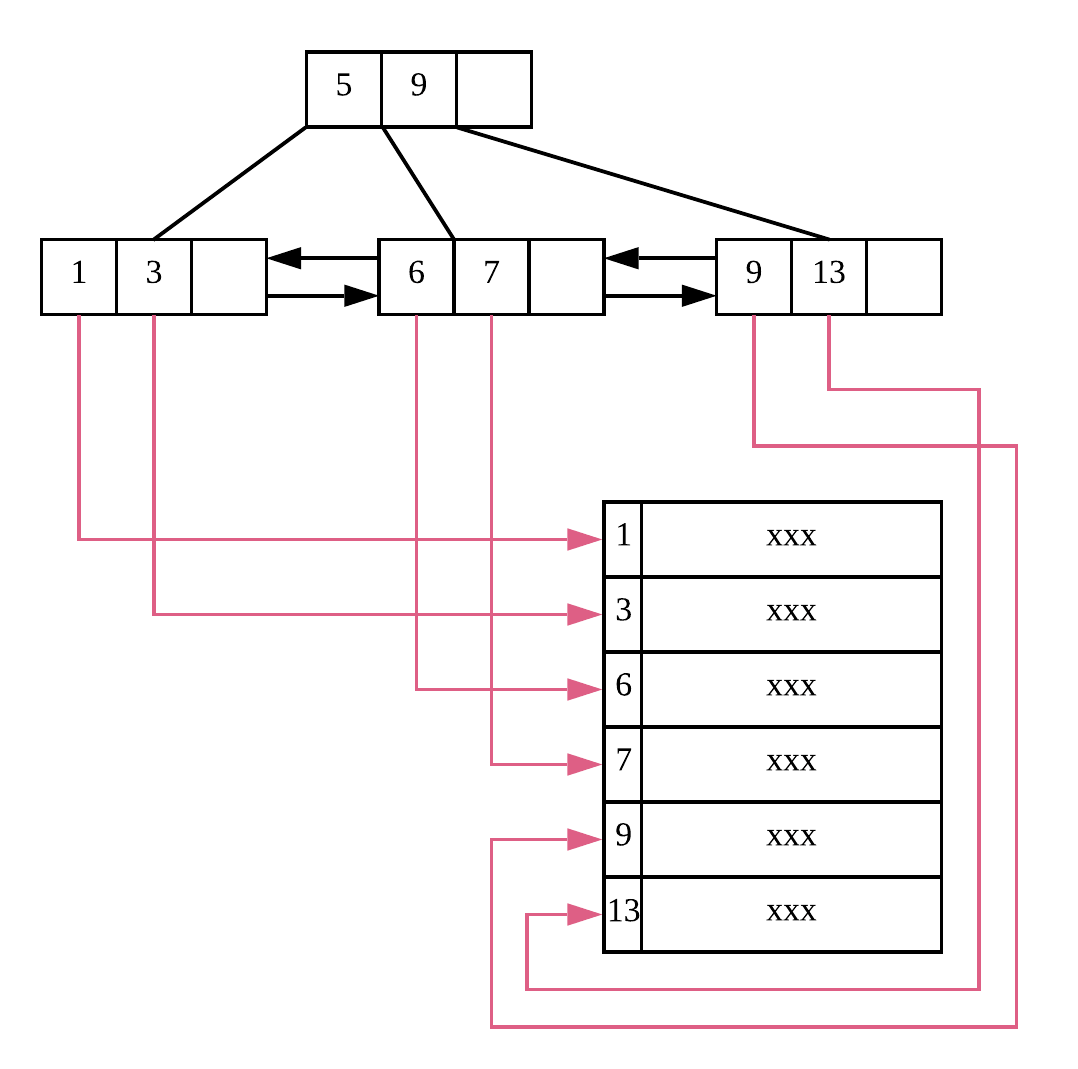
所以一棵简单的 B+ Tree 可能如上图所示,非叶子节点只是负责定位出最终的叶子节点位置,并不存储任何索引关键字的具体信息。而叶子节点额外会存储指向最终索引关键字具体信息的指针。这样的结构,让 B+ Tree 的内部节点所占用的空间更小,一次性读入内存中的内部节点个数越多,意味着可以较少 IO 次数从而更快定位出所要查找数据的具体位置。
由于 B+ Tree 中在叶子节点中包含了所有数据,所以查找任何一条数据,都需要从根节点最终查找到叶子节点,也就意味着 B+ Tree 的查找效率相比较 B Tree 来说更加稳定。
另外,B+ Tree 的所有叶子节点构成一个排序的链表结构,在使用诸如 SELECT field_1 FROM table_name WHERE field1 > xxx 这样的范围查询时,直接能够将此范围查询转变为磁盘的顺序查询,提高查询效率。
虽说 B Tree 相对于 B+ Tree 占有一定的存储空间优势,毕竟 B Tree 中的元素不会进行重复存储,但在实际的应用中,索引所占用的空间都比较大,因此 B Tree 所带来的存储空间的节省并没有占据很好的优势,因此 B+ Tree 的使用更为广泛。希望本文能够帮助你更好理解 B/B+ Tree 的原理,并能够更好理解为什么数据库管理系统中会使用这种结构当作索引实现。下一篇文章并发下的 B+ Tree,会向你介绍 B+ Tree 是如何获取读写锁来应对并发情况下的竞争问题的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK