

计算广告面面观(5):DSSN
source link: http://freewill.top/2020/03/28/AD-RS-5/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
在搜索广告的场景中,query 和 document 使用不同的单词、同一个单词的不同形态(如:缩写、时态、单复数)来表达同一个概念。如果简单的通过文本的单词匹配来计算 query 和 document 的相似性,则效果不好。
一种解决方式是:利用潜在语义模型latent semantic model (如:LSA),将 query 和 document 都降维到低维语义空间,然后根据二者在低维空间的距离来计算二者相似度。
论文 “Learning Deep Structured Semantic Models for Web Search using Clickthrough Data” 提出 Deep Structured Semantic Model:DSSM 模型,该模型也是将 query 和 document 降维到公共的低维空间。在该低维空间中,query 和 document 的相似性也是通过二者的距离来衡量。
其中LSA 的低维空间是通过无监督学习,利用单词的共现规律来训练;而DSSM的低维空间是通过有监督学习,利用 (query,document) pair 对的点击规律来训练。最终实验表明:DSSM 模型要优于 LSA 模型。
为解决搜索广告中词汇量大的问题(即:词汇表过于庞大),DSSN模型采用了 word hash 技术。
一、模型
DSSM 模型将原始的文本特征映射到低维的语义空间。
首先将 query 和 document 表示为词频向量,该向量由每个单词出现的词频组成。如:query = 苹果手机 / 价格, document = Iphone / Xs / 最低 / 售价 / 11399 / 元 / Iphone / X / 价格 / 6999 元 。
构建词汇表:
苹果手机 Iphone x Xs 价格 最低 售价 6999 11399 元
则得到 query 向量和 document 向量为:

然后将$\overrightarrow { q } $和 $\overrightarrow { d } $ 映射到低维语义空间,得到 query 语义向量 和 document 语义向量 。
计算$\overrightarrow { { y }_{ q } } $和 $\overrightarrow { { y }_{ d } } $ 的相似度:
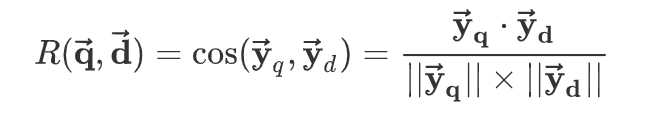
给定 query i ,计算所有document 与它的相似度,并截取 top K 个 document 即可得到排序结果:
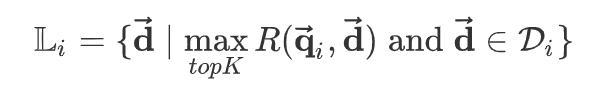
其中$L_i$是 query i 的排序结果(根据相似度降序排列),$D_i$是所有与 query i 有关的文档。
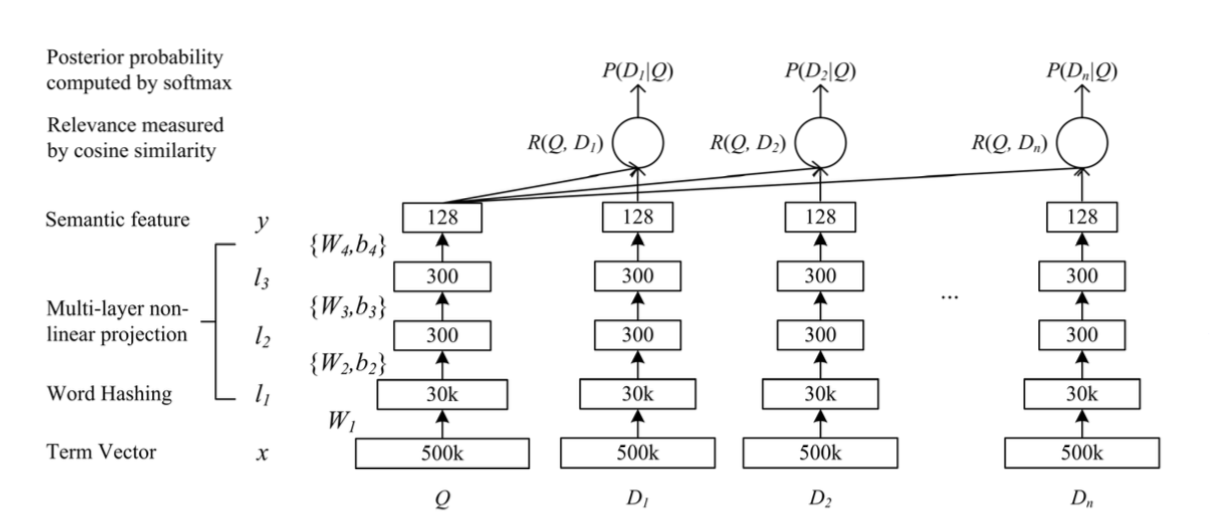
隐藏层的处理:
假设输入向量为$\overrightarrow { x }$,输出向量为 $\overrightarrow { y }$ ,网络一共有$L$层。对于 query,输入就是$\overrightarrow { q }$,输出就是$\overrightarrow { y_q}$ ;对于 document,输入就是$\overrightarrow { d }$ ,输出就是 $\overrightarrow { y_d }$
第$l$层的隐向量为:
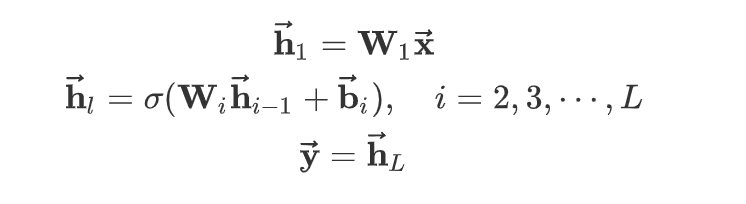
其中:$\sigma(·)$为激活函数。论文(2013年)采用 tanh 激活函数,但是现在推荐 relu 激活函数。$W_i$,$\overrightarrow { b_i }$为待学习的网络参数。
训练过程
给定 query $\overrightarrow { q }$ 和 document $\overrightarrow { d }$ ,用户点击该文档的概率为:
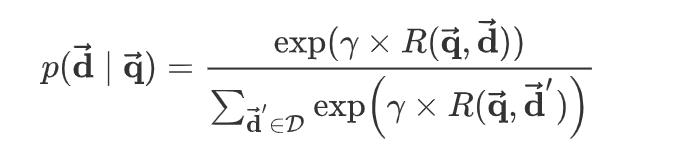
其中$\gamma$为平滑因子,它是一个超参数,需要根据验证集来执行超参数搜索;$D$是候选的文档集合。
实际应用中,给定一对点击样本$(\overrightarrow { q },\overrightarrow { d }^+)$,我们从曝光但是未点击的文档中随机选择K篇文档作为负样本$(\overrightarrow { q },\overrightarrow { d_k }^-),k=1,2,···,K$ ,则$D =\{\overrightarrow { d^+ },\overrightarrow { d_1 }^-,\overrightarrow { d_2 }^-···\overrightarrow { d_K }^-\}$
论文中选择K=4,并且论文表示:K不同的负采样策略对结果没有显著影响。
模型训练的目标是:最大化点击样本的对数似然:
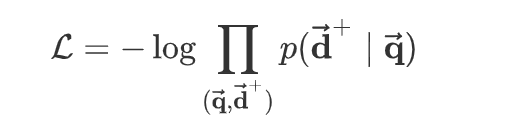
然后基于随机梯度下降优化算法来求解该最优化问题。
注意:这里并没有计算负样本的概率$p(\overrightarrow { d_k }^-|\overrightarrow { q })$,负样本的信息在计算概率$p(\overrightarrow { d_k }^+|\overrightarrow { q })$时被使用。
二、word hash
在将 query/document 的文本转化为输入向量的过程中,输入向量的维度等于词表的大小。由于实际 web search 任务中的词汇表非常庞大,这导致 DSSM 网络的输入层的参数太多,模型难以训练。
假设词汇表有50万,经过 embedding 之后的维度为300维,则输入层权重为
$W\in R^{50w·300}$万,一共1.5亿参数。为解决该问题,DSSM 模型在第一层引入 word hash 技术。该层是一个线性映射,虽然参数非常多,但是这些参数不需要更新和学习。
word hash 技术用于降低输入向量的维度。给定一个单词,如:good,word hash 的步骤为:
- 首先添加开始标记、结束标记:#good#
- 然后将其分解为字符级的 n-gram 格式:#go,goo,ood,od# (n=3 时)
- 最后将文本中的单词 good 用一组 char-level n-gram 替代。
虽然英语词汇的数量可以是无限的(可以出现大量的、新的合成词),但是英语(或其它类似语言)的字符n-gram 数量通常是有限的。因此word hash 能够大幅降低词汇表的大小。
50万规模的词汇表经过 word hash 之后降低到3万规模,这使得输入层的参数降低到 900万(假设 embedding 维度为 300 维)。相比较于原始的1.5亿,参数降低到原始数量的 1/16 。
除此之外,word-hash 技术还有以下优点:
- 它能够将同一个单词的不同形态变化映射到 char-level n-gram 空间中彼此接近的点。
- 它能够有效缓解 out-of-vocabulary:OOV 问题。在推断期间,虽然有些词汇未出现在训练集中(未登陆词),但是当拆解未 char-level n-gram 之后,每个 n-gram 都在训练集中出现过。
- 从单词到 char-level n-gram 的映射关系是固定的线性映射,不需要学习。
char-level n-gram 可以视作 word 的一个简单的 representation,而 word-hash 技术就是得到这个 representation 。
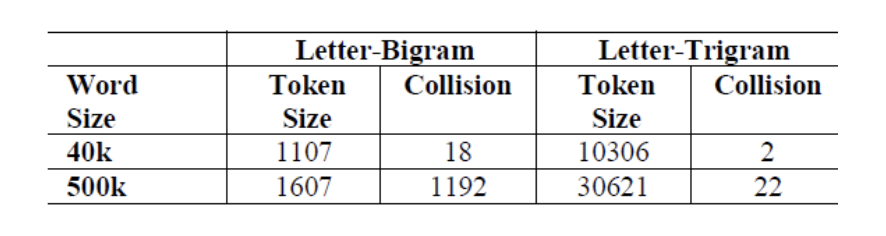
word-hash 一个潜在的问题是冲突 collision:两个不同的单词可能具有相同的 char-level n-gram 表示。下表中统计了两个词汇表中的冲突统计信息。可以看到,当采用 3-gram 表示时,冲突的占比小于千分之一。
三、实验
论文实现的 DSSM 模型,包含四层:
- 第一层为 word hash 层,它将 word 映射为 char-level 3-gram 。其映射规则是固定的,不需要学习参数。
- 第二层、第三层为中间层,每层输出为 300维。
- 最后一层为输出层,输出 128维向量。
权重初始化:权重通过在$\left[ -\sqrt { \frac { 6 }{ { fan }_{ in }+fan_{ out } } } ,\sqrt { \frac { 6 }{ { fan }_{ in }+fan_{ out } } } , \right] $之间均匀分布的随机变量来初始化。其中$ { fan }_{ in }$,$ { fan }_{ out }$ 表示输入单元数量和输出单元数量。
模型通过 mini-batch 随机梯度下降法优化,每个 batch 包含 1024个样本,一共训练 20 个 epoch 。
模型原始词汇表为 50万(即:保留常见的50万词汇),经过 word hash 之后降低到 3万。
实验数据集:数据集是从商业搜索引擎的 1年 query 日志文件中采样的 16510 个 query,平均每个 query 有 15 个相关的 document。
每对 (query,document) 都有人工标注的标签。标签一共5个等级 0-4,0 表示无关,4 表示最相关。
DSSM 模型和其它模型的比较结果如图所示,其中模型的评估指标为 NDCG 。
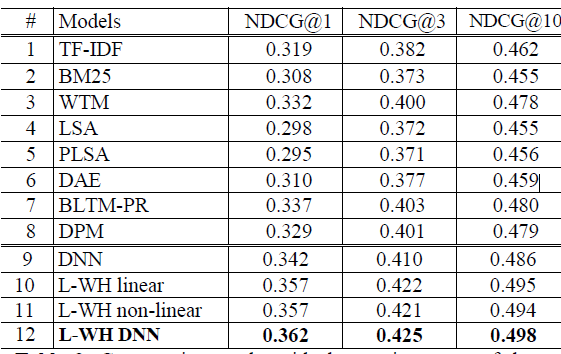
9~12 行给出了不同的 DSSM 变化:
DNN:没有采用 word-hash 的 DSSM 。它和第六行的DAE 结构相同,但是DAE 采用无监督学习训练,而DNN 采用有监督学习训练。为了能够训练DNN 模型,我们采用4万规模的词汇表(即:保留常见的4万词汇)。
L-WH linear:线性的 word hash 模型。在经过 word hash 之后,直接连接到输出层,且输出层不采用任何非线性函数。因此整个模型都是线性的。
L-WH non-linear:非线性的 word hash 模型。在经过 word hash 之后,直接连接到输出层,但是输出层采用非线性函数。
L-WH DNN:标准的 DSSM 模型。
结论:
- 从 DNN 和 DAE 的比较结果发现:监督学习普遍比无监督学习效果好
- word hash 允许我们使用更大规模的词汇表。如 L-WH-DNN 采用 50万规模的词汇表,而 DNN 采用 4万规模的词汇表,但是 L-WH-DNN 的模型参数反而更少。词汇表越小,则未登陆词越多,这导致文本被丢弃的信息越多。模型的效果越差。因此 word hash 技术既可以减少模型参数,又能提升模型效果。
-
深层网络强于浅层网络。
- 无监督学习: LSA 可以看作浅层网络。深层网络的 DAE 效果强于浅层网络 LSA 。
- 监督学习:L-WH non-linear 可以视为 L-WH DNN 的浅层版本,实验结果表明后者效果更好。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK