

决策树的构建及可视化——帮自己配副隐形眼镜-奶糖猫
source link: https://blog.51cto.com/14746554/2480243
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
机器学习笔记(四)——决策树的构建及可视化
上一篇文章中主要介绍了以下几方面:
- 决策树的简介
- 决策树的流程
- 熵的定义及如何计算熵
- 信息增益的定义及如何计算信息增益
- 依据信息增益划分数据集
本文以一个新的数据集(隐形眼镜数据集)为基础实现构建决策树、决策树的保存与加载、利用决策树分类、决策树的可视化,前文的知识不在过多概述,着重介绍这四个方面。
先大致了解一下数据集:
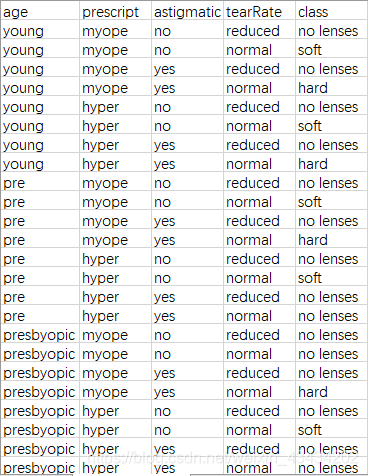
这份数据源至UCI数据库,其共有4个特征分别为age(年龄)、prescript(症状)、astigmatic(闪光)、tearRate(泪液产生率)以及一个分类标签class,该分类包含硬材质、软材质和不应配带三种。
为了方便处理,对样本做以下处理:
- age:young—>0、pre—>1、presbyopic—>2
- prescript:myope—>0、hyper—>1
- astigmatic:no—>0、yes—>1
- tearRate:reduced—>0、normal—>1
四、决策树的构建
在构造决策树之前,先回顾一下前几个子模块的工作原理:先获取原始数据集,然后基于最优特征划分数据集,当数据集特征大于两个时,第一次划分之后,数据将被向下传递至树的下一个节点,在这个节点上,在此划分数据,此过程是利用递归原理处理数据集。
什么时候划分结束呢?当程序遍历完所有划分数据集的属性,或者每个分支下所有实例分类一致时代表划分数据集结束。
而构造决策树的过程就是将每一次划分出的数据填入一个字典中,当数据集划分结束时,向字典中填充数据也结束,此过程也是一个递归过程,至此决策树的构造完成。
代码如下:
def CreateTree(DataSet):
#获取所有特征标签
index_list = list(DataSet.columns)
#获取最后一列(分类标签)的类别
label_series = DataSet.iloc[:,-1].value_counts()
#判断类别标签最多一个是否等于数据样本数、或者数据集是否只有一列
if label_series[0]==DataSet.shape[0] or DataSet.shape[1] == 1:
return label_series.index[0] #返回类标签
# 获取最优特征列索引
col = ChooseBF(DataSet)
# 获取最优特征
BestFeature = index_list[col]
#将最优特征依次填入字典中
TheTree = {BestFeature:{}}
# 从标签列表中删去该特征标签
del index_list[col]
#提取最佳切分列的所有属性值
value_list = set(DataSet.iloc[:,col])
#利用递归方法建树,每次对象为当前最优特征
for value in value_list:
TheTree[BeatFeature][value] = CreateTree(splitSet(DataSet,col,value))
return TheTree递归函数的第一个停止条件是所有的类标签都相同,递归函数第二个停止条件是使用完数据集中所有的特征,即数据集不能继续划分;字典变量TheTree储存了树的所有信息,BestFeature则是当前最优特征。
最后代码遍历当前最优特征的所有属性值,在每个数据集划分上递归调用函数CreateTree(),并且传入的参数是每次划分之后的数据集,得到的返回值都会被插入字典TheTree中,递归结束后,字典中将会嵌套很多代表叶子节点信息的数据。
得到TheTree字典如下:
{'tearRate': {0: 'no lenses', 1: {'astigmatic': {0: {'age': {0: 'soft', 1: 'soft', 2: {'prescript': {0: 'no lenses', 1: 'soft'}}}}, 1: {'prescript': {0: 'hard', 1: {'age': {0: 'hard', 1: 'no lenses', 2: 'no lenses'}}}}}}}}从左边开始,第一个关键字key为tearRate,这代表在所有特征中,tearRate特征的信息增益最大,在此特征下,数据下降(划分)最快,该关键字的值也是一个字典。第二个关键字是依据tearRate特征划分的数据集,这些关键字的值就是tearRate节点的子节点。
这些值可能是类标签,也可能是另一个字典。如果值是类标签,则该子节点为叶子节点;如果值是另一个字典,则该子节点是一个判断节点,通过这类格式不断重复就构成了一棵决策树。
五、决策树的保存与加载
决策树的保存有很多种方法,但原理都是一样的,即序列化与反序列化,这里介绍以下两种方法。
#第一种方法
np.save('TheTree.npy',TheTree)
read_tree = np.load('TheTree.npy',allow_pickle=True).item()第一种方法是利用numpy库中的save方法,可以将字典格式的决策树保存为npy文件;当读取树时,需要在方法后加上item(),因为我们存储的数据是字典类型,若是矩阵类型则需删去。
#第二种方法
import pickle
def storeTree(inputTree, filename):
fw = open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
fr = open(filename,'rb')
return pickle.load(fr)第二种方法是利用pickle库的dump方法对数据序列化,在读取时,用load方法即可加载数据,这里需要注意,不论写入还是读取时,都需要以二进制的格式,不然会发生报错。
六、利用决策树分类
构造决策树之后,可以将它用于实际数据的分类,在执行数据分类时,需要传入决策树、特征标签列表和用于分类的测试数据。然后程序会比较测试数据与决策树上的数值,递归执行该过程直到进入叶子节点,最后得到的分类结果就是叶子节点所属类型。
代码如下:
#传入的数据为决策树、数据集特征标签、测试数据
def classify(inputTree,labels,testVec):
#获取决策树的第一个节点
FirstStr = list(inputTree.keys())[0]
#取第一个节点外下一个字典
SecondDict = inputTree[FirstStr]
'''
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
{0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}
{0: 'no', 1: 'yes'}
'''
#取第一个节点在labels里的索引
feat_index = labels.index(FirstStr)
#遍历字典中的key
for key in SecondDict.keys():
#比较testVec里的值与树节点的值,如果达到叶子节点,返回类标签
if testVec[feat_index]==key:
#如果下一个字典中的仍包含字典,则递归继续比较
if type(SecondDict[key])==dict :
classlabel = classify(SecondDict[key],labels,testVec)
else:
#直到最后取到类标签
classlabel = SecondDict[key]
return classlabel其中传入特征标签列表labels的作用是帮助确定每次最优特征在数据集中的索引,利用index方法查找当前列表中第一个匹配FirstStr变量的元素,然后代码递归遍历整棵树,比较测试数据testVec变量中的值与树节点的值,直到达到叶子节点,返回当前节点的分类标签。
这里利用了上篇文章的数据构造的树做一个SecondDict举例,它的作用就是获取当前字典中最优特征(第一个关键字)的值,以达到与测试数据递归比较的效果。
classlabel = classify(inputTree,labels,[0,1,0,0])
'''
no lenses
'''执行该函数,可以将传入的数据与原文中的数据进行比对,得到的分类结果是一致的。
七、决策树可视化
决策树的主要优点就是直观易于理解,如果不能将其直观地显示出来,就无法发挥其优势。但通过matplotlib库绘制决策树是一个十分复杂的过程,这里偷懒介绍另一种比较简易的方法。
Graphviz是一种图形绘制工具,可以绘制出很多图形结构,但传入的数据需要的是dot格式,所以这里利用sklearn生成的决策树进行可视化。
Graphviz下载地址中下载graphviz-2.38.msi文件,在安装结束后需要配置环境,将该文件夹的路径添加至系统变量的Path中,在cmd中输入dot -version出现版本信息则代表安装配置成功。
决策树可视化代码如下:
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
import pydotplus
import graphviz
def pic_tree(DataSet):
#所有特征数据
feature_train = DataSet.iloc[:, :-1]
#类标签数据
the_label = DataSet.iloc[:, -1]
#unique将类标签去重
labels = the_label.unique().tolist()
#以类标签的在列表中的索引代替该标签——转化成数字
the_label = the_label.apply(lambda x: labels.index(x))
#训练数据
clf = DecisionTreeClassifier()
clf = clf.fit(feature_train, the_label)
#绘图过程
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=['age','prescript','astigmatic','tearRate'],
class_names=['no lenses', 'soft','hard'], filled=True, rounded=True,
special_characters=True)
# 两种方法
# 1.利用graphviz库生成PDF图片
pic = graphviz.Source(dot_data)
pic.render('lense')
# 2.利用pydotplus库将Dot格式转成PDF
#graph = pydotplus.graph_from_dot_data(dot_data)
#return graph.write_pdf("lense.pdf")这里生成决策树图片时也有两种方法,第一种是利用graphviz库的Source方法生成PDF图片,第二种需要利用pydotplus库将Dot格式转成PDF,最后得到的可视化图片如下:
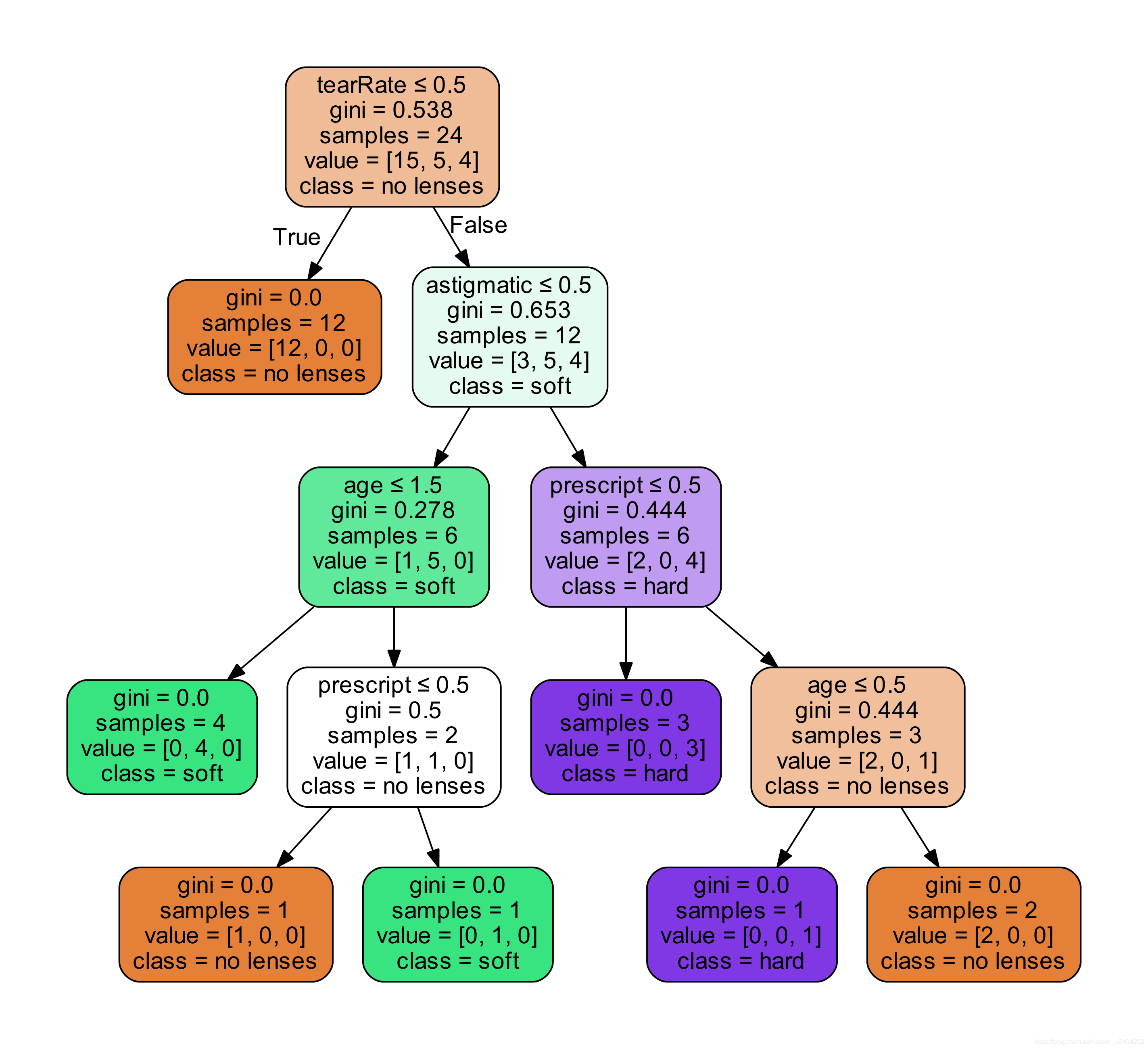
综上有关决策树的相关知识介绍完毕,总体来说,这个分类算法还是易于理解的,但它是十分重要的,因为它为后面学习随机森林奠定了基础,每一个算法都有各自的适合环境,而决策树也有自己的优缺点。
决策树的优点:
- 计算复杂度不高,输出结果易于理解。
- 对中间缺失值不敏感。
- 可以处理不相关特征数据。
- 树能实现图形化。
决策树的缺点:
- 当决策树过于复杂时,会出现过度拟合情况。
- 比较不稳定,数据发生比较小的变化时也会导致生成不同的树。
- 在样本不均衡时,权重不同会导致树出现偏差。
公众号【奶糖猫】后台回复“隐形眼镜”即可获取源码和数据供参考,感谢阅读。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK