
21

Kubernetes Deployment Controller 详解
source link: http://yangxikun.com/kubernetes/2020/02/22/kubernetes-deployment-controller.html?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kubernetes Deployment Controller 详解
22 February 2020
创建与启动
- ctx.AvailableResources:可用的 GVR,由 cmd/kube-controller-manager/app.GetAvailableResources 通过 pkg/controller.SimpleControllerClientBuilder 创建的 client-go/kubernetes.Clientset 调用 kube-apiserver 的接口获得。
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
// 创建控制器
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
// 启动控制器
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
- dInformer:client-go/informers/apps/v1.deploymentInformer
- rsInformer:client-go/informers/apps/v1.replicaSetInformer
- podInformer:client-go/informers/core/v1.podInformer
- client:client-go/kubernetes.Clientset
- eventBroadcaster:记录 Deployment 处理时发生的一些事件,在 kubectl get events 和 kubectl describe 中可以看到
- dc.rsControl:用于接管/释放 rs
// NewDeploymentController creates a new DeploymentController.
func NewDeploymentController(dInformer appsinformers.DeploymentInformer, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, client clientset.Interface) (*DeploymentController, error) {
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: client.CoreV1().Events("")})
if client != nil && client.CoreV1().RESTClient().GetRateLimiter() != nil {
// 创建了一个 Prometheus Gauge
// 第二个参数被忽略
// 对应的功能未实现,标记为 TODO
if err := metrics.RegisterMetricAndTrackRateLimiterUsage("deployment_controller", client.CoreV1().RESTClient().GetRateLimiter()); err != nil {
return nil, err
}
}
dc := &DeploymentController{
client: client,
eventRecorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "deployment-controller"}),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
dc.rsControl = controller.RealRSControl{
KubeClient: client,
Recorder: dc.eventRecorder,
}
// 注册控制器回调
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
// 同步 Deployment 资源对象的状态
dc.syncHandler = dc.syncDeployment
dc.enqueueDeployment = dc.enqueue
// Lister 用于从缓存中获取资源对象
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
dc.dListerSynced = dInformer.Informer().HasSynced
dc.rsListerSynced = rsInformer.Informer().HasSynced
dc.podListerSynced = podInformer.Informer().HasSynced
return dc, nil
}
- workers:ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs
- dc.syncHandler:处理资源对象变更,相同 key 不能并发处理(由 dc.queue 的实现保证了)
// Run begins watching and syncing.
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
// recover
defer utilruntime.HandleCrash()
// 关闭工作队列,停止所有 worker
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
// 等待 Lister 完成一遍同步
if !controller.WaitForCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
// 启动指定数量的 worker 来处理资源对象变更
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
// 等待控制器停止
<-stopCh
}
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string))
// 如果 err != nil,会尝试重新入队
dc.handleErr(err, key)
return true
}
控制循环流程图
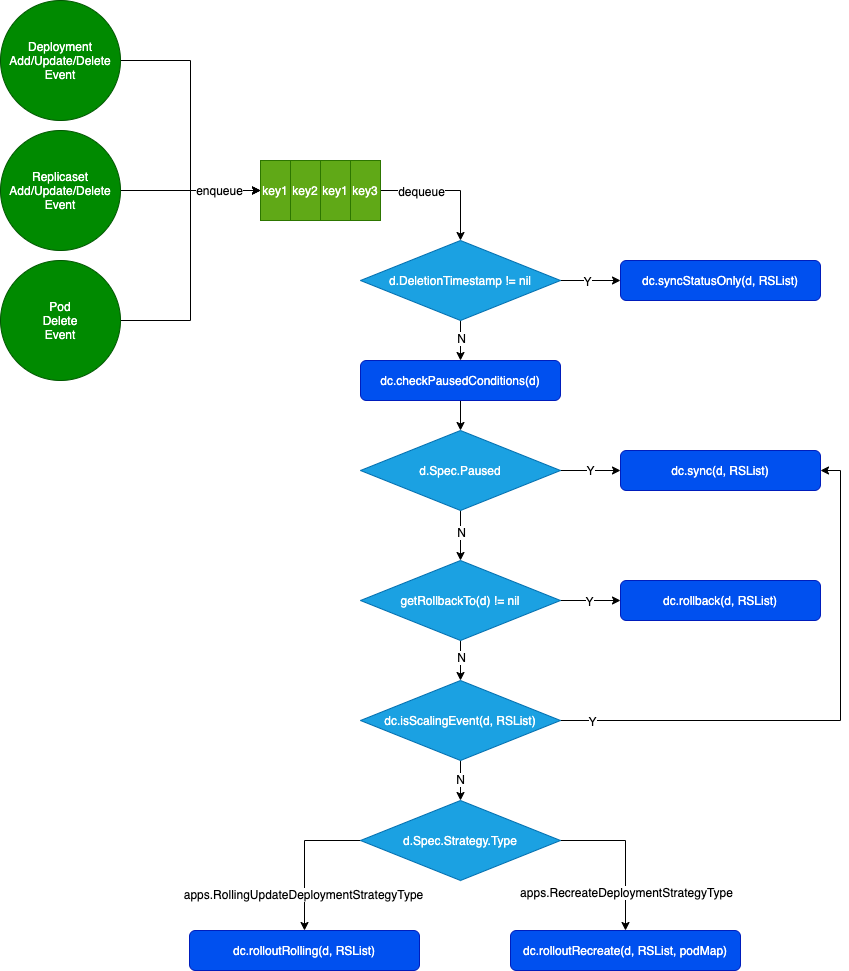
DeploymentController.queue
工作队列,由 Informer 的回调负责入队,dc.worker 负责出队,实现是 client-go/util/workqueue.rateLimitingType,支持速率限制、延迟、去重的功能,由如下组件组成:
- client-go/util/workqueue.delayingType:实现延迟功能,维护一个小顶堆,当任务延迟时间到达后,会被取出放到工作队列中
- client-go/util/workqueue.Type:工作队列的实现,会丢弃短时间内相同的任务,确保相同的任务只有一个处于处理状态
- client-go/util/workqueue.MaxOfRateLimiter:速率限制,由多个限制器组成,返回最坏情况的限制
- client-go/util/workqueue.ItemExponentialFailureRateLimiter:实现 baseDelay*2^num-failures 的延迟,最大延迟为 maxDelay
- client-go/util/workqueue.BucketRateLimiter:对 golang.org/x/time/rate.Limiter 的封装
发生以下事件时,会将 Deployment 入队。
- addDeployment(obj interface{}):Deployment 创建
- updateDeployment(old, cur interface{}):Deployment 更新(包括 Status)
- deleteDeployment(obj interface{}):Deployment 删除
- addReplicaSet(obj interface{}):发生了 ReplicaSet 创建事件,如果有所属的 Deployment,则入队,否则根据 rs.Labels 找出所有的 Deployment 并入队
- updateReplicaSet(old, cur interface{}):发生了 ReplicaSet 更新事件(Scale 操作、Status 更新),根据 old 与 cur 的情况,入队所属的 Deployment
- deleteReplicaSet(obj interface{}):发生了 ReplicaSet 删除事件,入队所属的 Deployment
- deletePod(obj interface{}):发生了 Pod 删除事件,且其所属的 Deployment 的更新策略为 Recreate,则入队该 Deployment
任务出队,处理资源对象变更
- dc.getReplicaSetsForDeployment:遍历所有的 ReplicaSet,找出满足 d.Spec.Selector 的 ReplicaSets
- 如果 ReplicaSet 属于 d,但不匹配 d.Spec.Selector,则会释放 ReplicaSet,删除 ownerReferences.uid
- 如果 ReplicaSet 不属于任何 d,则会接管 ReplicaSet,设置 ownerReferences
- dc.getPodMapForDeployment:根据 d.Spec.Selector 从 Lister 缓存中获取 Pods,构造按 rs.UID 分组的 PodMap 结果
- dc.syncStatusOnly:
- dc.getAllReplicaSetsAndSyncRevision:获取最新的 RS 和所有旧的 RS,如果最新的 RS 不存在的话,可以进行创建。同时更新最新的 RS 和 d 的 revision
- deploymentutil.FindOldReplicaSets:返回除了最新的 RS,其余的 RS
- deploymentutil.FindNewReplicaSet:找到最旧的 rs.Spec.Template == d.Spec.Template 的 RS
- dc.getNewReplicaSet:返回最新的 RS,如果不存在,则可以进行创建,并且同步最新的 RS 和 d 的 revision
- deploymentutil.FindOldReplicaSets:返回除了最新的 RS,其余的 RS
- dc.syncDeploymentStatus:根据 RSs 计算 Deployment 的状态,如果状态有变化,则调用接口更新
- calculateStatus:计算 Deployment 的状态
- dc.getAllReplicaSetsAndSyncRevision:获取最新的 RS 和所有旧的 RS,如果最新的 RS 不存在的话,可以进行创建。同时更新最新的 RS 和 d 的 revision
- dc.checkPausedConditions:如果设置了 d.Spec.ProgressDeadlineSeconds,那么根据 d.Spec.Paused 和 pausedCondExists 的情况,更新 d.Status.Conditions,添加 DeploymentPaused 或 DeploymentResumed 类型的 Condition
- dc.sync:负责调协 Scale 和 Pause 操作
- dc.getAllReplicaSetsAndSyncRevision
- dc.scale
- deploymentutil.FindActiveOrLatest:如果只有一个活跃的 RS,返回这个 RS;如果没有活跃的 RS,返回最新的 RS
- 将 rs.Spec.Replicas Scale 为 deployment.Spec.Replicas
- deploymentutil.IsSaturated:判断 newRS 是否满足 rs.Spec.Replicas == deployment.Spec.Replicas && desired == deployment.Spec.Replicas && rs.Status.AvailableReplicas == deployment.Spec.Replicas
- 如果满足,将所有活跃的 oldRSs Scale 为 0
- deploymentutil.IsRollingUpdate:如果更新策略是 apps.RollingUpdateDeploymentStrategyType,此时有多个活跃的 RS
- allRSsReplicas = 所有 rs.Spec.Replicas 之和
- deploymentReplicasToAdd = deployment.Spec.Replicas + maxSurge - allRSsReplicas
- 按照比例对所有活跃的 RS 进行 Scale
- deploymentReplicasAdded = 累加 proportion
- 计算每个 RS 的 proportion
- rsFraction = rs.Spec.Replicas * (d.Spec.Replicas + MaxSurge(d)) / annotatedReplicas
- 如果 MaxReplicasAnnotation(rs) = oldD.Spec.Replicas + MaxSurge(oldD) 存在,则 annotatedReplicas = MaxReplicasAnnotation(rs)
- 否则 annotatedReplicas = d.Status.Replicas
- 如果 deploymentReplicasToAdd > 0,那么返回 min(rsFraction, deploymentReplicasToAdd - deploymentReplicasAdded)
- 如果 deploymentReplicasToAdd < 0,那么返回 max(rsFraction, deploymentReplicasToAdd - deploymentReplicasAdded)
- rsFraction = rs.Spec.Replicas * (d.Spec.Replicas + MaxSurge(d)) / annotatedReplicas
- rs.Spec.Replicas = rs.Spec.Replicas + proportion
- deploymentutil.FindActiveOrLatest:如果只有一个活跃的 RS,返回这个 RS;如果没有活跃的 RS,返回最新的 RS
- dc.cleanupDeployment:如果 d.Spec.Paused && getRollbackTo(d) == nil,那么删除掉最旧的不活跃的 RS,保留最新 d.Spec.RevisionHistoryLimit 个 RS
- dc.syncDeploymentStatus
- dc.rollback:处理回滚操作
- 从 Annotations 中获取回滚的版本号,如果版本号为 0,则回滚到上一个版本
- 否则,从 ReplicaSets 中找到版本号对应的 RS,更新 deployment.Spec.Template = rs.Spec.Template 和清除回滚的 annotation,调用 kube-apiserver 接口更新
- dc.rolloutRecreate:
- dc.scaleDownOldReplicaSetsForRecreate:设置所有旧的 ReplicaSets Spec.Replicas = 0
- dc.scaleUpNewReplicaSetForRecreate:当所有旧的 ReplicaSets 管理的 Pod 都停止后,才创建新的 RS
- dc.rolloutRolling:
- dc.reconcileNewReplicaSet:
- 如果 newRS.Spec.Replicas == deployment.Spec.Replicas,则不需要调协
- 否则 deploymentutil.NewRSNewReplicas:计算 newReplicasCount
- 根据 deployment.Spec.Strategy.RollingUpdate.MaxSurge 和 deployment.Spec.Replicas,计算 maxSurge
- 如果 deployment.Spec.Strategy.RollingUpdate.MaxSurge 是百分数,那么 maxSurge = roundUp(deployment.Spec.Strategy.RollingUpdate.MaxSurge * deployment.Spec.Replicas)
- 如果 deployment.Spec.Strategy.RollingUpdate.MaxSurge 是整数,那么 maxSurge = deployment.Spec.Strategy.RollingUpdate.MaxSurge
- maxTotalPods = deployment.Spec.Replicas + maxSurge
- currentPodCount = 所有 rs.Spec.Replicas 的和
- 如果 currentPodCount >= maxTotalPods,则不能 scaleUp
- 否则 scaleUpCount = min(maxTotalPods - currentPodCount, deployment.Spec.Replicas - newRS.Spec.Replicas)
- newReplicasCount = newRS.Spec.Replicas + scaleUpCount
- 根据 deployment.Spec.Strategy.RollingUpdate.MaxSurge 和 deployment.Spec.Replicas,计算 maxSurge
- dc.scaleReplicaSetAndRecordEvent:调整 newRs.Spec.Replicas = newReplicasCount
- dc.reconcileOldReplicaSets:
- oldPodsCount = oldRSs 的 rs.Spec.Replicas 之和
- 如果 oldPodsCount == 0,则不需要调协,直接返回
- allPodsCount = 所有 rs.Spec.Replicas 的和
- deploymentutil.MaxUnavailable:计算 maxUnavailable
- 根据 deployment.Spec.Strategy.RollingUpdate.MaxUnavailable 和 deployment.Spec.Replicas,计算 maxUnavailable
- 如果 deployment.Spec.Strategy.RollingUpdate.MaxUnavailable 是百分数,那么 maxUnavailable = deployment.Spec.Strategy.RollingUpdate.MaxUnavailable * deployment.Spec.Replicas
- 如果 deployment.Spec.Strategy.RollingUpdate.MaxUnavailable 是整数,那么 maxUnavailable = deployment.Spec.Strategy.RollingUpdate.MaxUnavailable
- maxUnavailable = min(maxUnavailable, deployment.Spec.Replicas)
- 根据 deployment.Spec.Strategy.RollingUpdate.MaxUnavailable 和 deployment.Spec.Replicas,计算 maxUnavailable
- 计算最小可用 minAvailable = deployment.Spec.Replicas - maxUnavailable
- newRS 不可用 Pod 计数 newRSUnavailablePodCount = newRS.Spec.Replicas - newRS.Status.AvailableReplicas
- maxScaledDown = allPodsCount - minAvailable - newRSUnavailablePodCount
- 我们需要确保 minAvailable 个 Pod 可用,但 newRS 可能有些 Pod 还不可用(因为 newRS 在 scaleUp),所以需要再减掉 newRSUnavailablePodCount
- 当然,这里假设 oldRSs 的 Pod 都是可用的
- dc.cleanupUnhealthyReplicas:在 oldRSs 中,将 rs.Spec.Replicas > rs.Status.AvailableReplicas 的不健康的 RS,进行 scaleDown,并累计 cleanupCount,不超过 maxScaledDown
- dc.scaleDownOldReplicaSetsForRollingUpdate
- deploymentutil.MaxUnavailable:计算 maxUnavailable
- 计算最小可用 minAvailable = deployment.Spec.Replicas - maxUnavailable
- availablePodCount = 计算所有 rs.Status.AvailableReplicas 的和
- 如果 availablePodCount <= minAvailable,则返回,不进行 scaleDown
- 如果不做 dc.cleanupUnhealthyReplicas 处理的话,且当前有不健康的 RS,那么 availablePodCount <= minAvailable 就有可能会一直为 true,导致一直无法 scaleDown,也就卡主了 rolloutRolling 的过程
- totalScaleDownCount = availablePodCount - minAvailable
- 在 oldRSs 中,按创建时间排序,逐个 RS 进行 scaleDown,并累计 totalScaledDown,不超过 totalScaleDownCount
- 返回 cleanupCount + totalScaledDown
- oldPodsCount = oldRSs 的 rs.Spec.Replicas 之和
- dc.reconcileNewReplicaSet:
// syncDeployment will sync the deployment with the given key.
// This function is not meant to be invoked concurrently with the same key.
func (dc *DeploymentController) syncDeployment(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
// 从 Lister 缓存中获取资源对象
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d)
}
return nil
}
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef
// through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// List all Pods owned by this Deployment, grouped by their ReplicaSet.
// Current uses of the podMap are:
//
// * check if a Pod is labeled correctly with the pod-template-hash label.
// * check that no old Pods are running in the middle of Recreate Deployments.
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
// d 正在删除,同步状态
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// Update deployment conditions with an Unknown condition when pausing/resuming
// a deployment. In this way, we can be sure that we won't timeout when a user
// resumes a Deployment with a set progressDeadlineSeconds.
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// rollback is not re-entrant in case the underlying replica sets are updated with a new
// revision so we should ensure that we won't proceed to update replica sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
// 更新
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
</div
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK