

JVM Bug:多个线程持有一把锁? | PerfMa应用性能技术社区
source link: https://club.perfma.com/article/205475?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
JVM线程dump Bug描述
在JAVA语言中,当同步块(Synchronized)被多个线程并发访问时,JVM中会采用基于互斥实现的重量级锁。JVM最多只允许一个线程持有这把锁,如果其它线程想要获得这把锁就必须处于等待状态,也就是说在同步块被并发访问时,最多只会有一个处于RUNNABLE状态的线程持有某把锁,而另外的线程因为竞争不到这把锁而都处于BLOCKED状态。然而有些时候我们会发现处于BLOCKED状态的线程,它的最上面那一帧在打印其正在等待的锁对象时,居然也会出现-locked的信息,这个信息和持有该锁的线程打印出来的结果是一样的(请看下图),但是对比其他BLOCKED态的线程却并没有都出现这种情况。当我们再次dump线程时又可能出现不一样的结果。测试表明这可能是一个偶发的情况,本文就是针对这种情况对JVM内部的实现做了一个研究以寻找其根源。
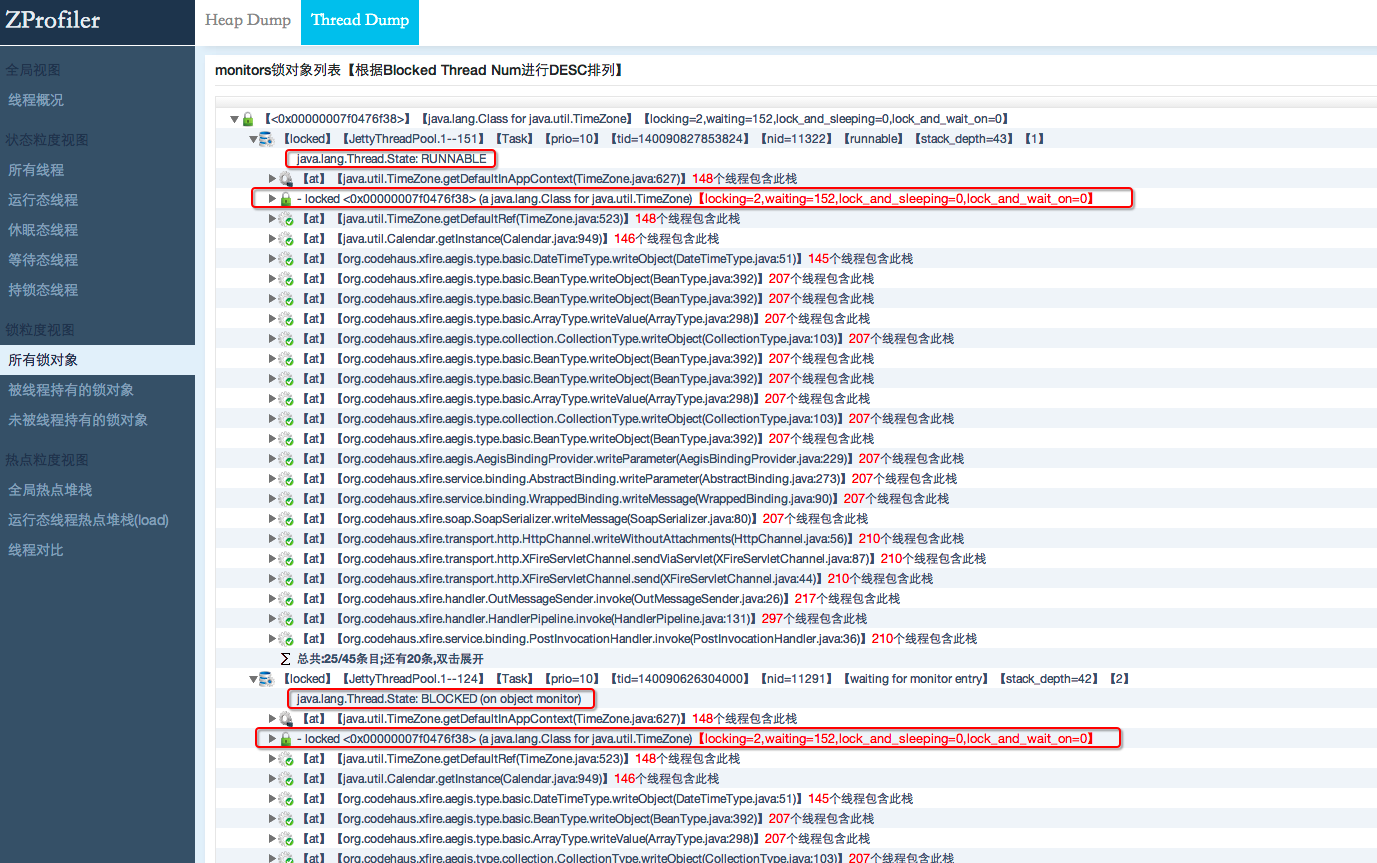
JStack命令的整个过程
上面提到了线程dump,那么就不得不提执行线程dump的工具—jstack,这个工具是Java自带的工具,和Java处于同一个目录下,主要是用来dump线程的,或许大家也有使用kill -3的命令来dump线程,但这两者最明显的一个区别是,前者的dump内容是由jstack这个进程来输出的,目标JVM进程将dump内容发给jstack进程(注意这是没有加-m参数的场景,指定-m参数就有点不一样了,它使用的是serviceability agent的api来实现的,底层通过ptrace的方式来获取目标进程的内容,执行过程可能会比正常模式更长点),这意味着可以做文件重定向,将线程dump内容输出到指定文件里;而后者是由目标进程输出的,只会产生在目标进程的标准输出文件里,如果正巧标准输出里本身就有内容的话,看起来会比较乱,比如想通过一些分析工具去分析的话,要是该工具没有做过滤操作,很可能无法分析。因此一般情况我们尽量使用jstack,另外jstack还有很多实用的参数,比如jstack pid >thread_dump.log,该命令会将指定pid的进程的线程dump到当前目录的thread_dump.log文件里。
jstack是使用Java实现的,它通过给目标JVM进程发送一个threaddump的命令,目标JVM的监听线程(attachListener)会实时监听传过来的命令(其实attachListener线程并不是一启动就创建的,它是lazy创建启动的),当attachListener收到threaddump命令时会调用thread_dump的方法来处理dump操作(方法在attachListener.cpp里)。
static jint thread_dump(AttachOperation* op, outputStream* out) {
bool print_concurrent_locks = false;
if (op->arg(0) != NULL && strcmp(op->arg(0), "-l") == 0) {
print_concurrent_locks = true;
}
// thread stacks
VM_PrintThreads op1(out, print_concurrent_locks);
VMThread::execute(&op1);
// JNI global handles
VM_PrintJNI op2(out);
VMThread::execute(&op2);
// Deadlock detection
VM_FindDeadlocks op3(out);
VMThread::execute(&op3);
return JNI_OK;
}
从上面的方法可以看到,jstack命令执行了三个操作:
- VM_PrintThreads:打印线程栈
- VM_PrintJNI:打印JNI
- VM_FindDeadlocks:打印死锁
三个操作都是交给VMThread线程去执行的,VMThread线程在整个JAVA进程有且只会有一个。可以想象一下VMThread线程的简单执行过程:不断地轮询某个任务列表并在有任务时依次执行任务。任务执行时,它会根据具体的任务决定是否会暂停整个应用,也就是stop the world,这是不是让我们联想到了我们熟悉的GC过程?是的,我们的ygc以及cmsgc的两个暂停应用的阶段(init_mark和remark)都是由这个线程来执行的,并且都要求暂停整个应用。其实上面的三个操作都是要求暂停整个应用的,也就是说jstack触发的线程dump过程也是会暂停应用的,只是这个过程一般很快就结束,不会有明显的感觉。另外内存dump的jmap命令,也是会暂停整个应用的,如果使用了-F的参数,其底层也是使用serviceability agent的api来dump的,但是dump内存的速度会明显慢很多。
VMThread执行任务的过程
VMThread执行的任务称为vm_opration,在JVM中存在两种vm_opration,一种是需要在安全点内执行的(所谓安全点,就是系统处于一个安全的状态,除了VMThread这个线程可以正常运行之外,其他的线程都必须暂停执行,在这种情况下就可以放心执行当前的一系列vm_opration了),另外一种是不需要在安全点内执行的。而这次我们讨论的线程dump是需要在安全点内执行的。
以下是VMThread轮询的逻辑:
void VMThread::loop() {
assert(_cur_vm_operation == NULL, "no current one should be executing");
while(true) {
...
//已经获取了一个vm_operation
if (_cur_vm_operation->evaluate_at_safepoint()) {
//如果该vm_operation需要在安全点内执行
_vm_queue->set_drain_list(safepoint_ops);
SafepointSynchronize::begin();//进入安全点
evaluate_operation(_cur_vm_operation);
do {
_cur_vm_operation = safepoint_ops;
if (_cur_vm_operation != NULL) {
do {
VM_Operation* next = _cur_vm_operation->next();
_vm_queue->set_drain_list(next);
evaluate_operation(_cur_vm_operation);
_cur_vm_operation = next;
if (PrintSafepointStatistics) {
SafepointSynchronize::inc_vmop_coalesced_count();
}
} while (_cur_vm_operation != NULL);
}
if (_vm_queue->peek_at_safepoint_priority()) {
MutexLockerEx mu_queue(VMOperationQueue_lock,
Mutex::_no_safepoint_check_flag);
safepoint_ops = _vm_queue->drain_at_safepoint_priority();
} else {
safepoint_ops = NULL;
}
} while(safepoint_ops != NULL);
_vm_queue->set_drain_list(NULL);
SafepointSynchronize::end();//退出安全点
} else { // not a safepoint operation
if (TraceLongCompiles) {
elapsedTimer t;
t.start();
evaluate_operation(_cur_vm_operation);
t.stop();
double secs = t.seconds();
if (secs * 1e3 > LongCompileThreshold) {
tty->print_cr("vm %s: %3.7f secs]", _cur_vm_operation->name(), secs);
}
} else {
evaluate_operation(_cur_vm_operation);
}
_cur_vm_operation = NULL;
}
}
...
}
在这里重点解释下在安全点内执行的vm_opration的过程,VMThread通过不断循环从_vm_queue中获取一个或者几个需要在安全点内执行的vm_opertion,然后在准备执行这些vm_opration之前先通过调用SafepointSynchronize::begin()进入到安全点状态,在执行完这些vm_opration之后,调用SafepointSynchronize::end(),退出安全点模式,恢复之前暂停的所有线程让他们继续运行。对于安全点这块的逻辑挺复杂的,仅仅需要记住在进入安全点模式的时候会持有Threads_lock这把线程互斥锁,对线程的操作都需要获取到这把锁才能继续执行,并且还会设置安全点的状态,如果正在进入安全点过程中设置_state为_synchronizing,当所有线程都完全进入了安全点之后设置_state为_synchronized状态,退出的时候设置为_not_synchronized状态。
void SafepointSynchronize::begin() {
...
Threads_lock->lock();
...
_state = _synchronizing;
...
_state = _synchronized;
...
}
void SafepointSynchronize::end() {
assert(Threads_lock->owned_by_self(), "must hold Threads_lock");
...
_state = _not_synchronized;
...
Threads_lock->unlock();
}
线程Dump中的VM_PrintThreads过程
回到开头提到的JVM线程Dump时的Bug,从我们打印的结果来看也基本猜到了这个过程:遍历每个Java线程,然后再遍历每一帧,打印该帧的一些信息(包括类,方法名,行数等),在打印完每一帧之后然后打印这帧已经关联了的锁信息,下面代码就是打印每个线程的过程:
void JavaThread::print_stack_on(outputStream* st) {
if (!has_last_Java_frame()) return;
ResourceMark rm;
HandleMark hm;
RegisterMap reg_map(this);
vframe* start_vf = last_java_vframe(®_map);
int count = 0;
for (vframe* f = start_vf; f; f = f->sender() ) {
if (f->is_java_frame()) {
javaVFrame* jvf = javaVFrame::cast(f);
java_lang_Throwable::print_stack_element(st, jvf->method(), jvf->bci());
if (JavaMonitorsInStackTrace) {
jvf->print_lock_info_on(st, count);
}
} else {
// Ignore non-Java frames
}
count++;
if (MaxJavaStackTraceDepth == count) return;
}
}
和我们这次问题相关的逻辑,也就是打印"-locked"的信息是正好是在jvf->print_lock_info_on(st, count)这行里面,请看具体实现:
void javaVFrame::print_lock_info_on(outputStream* st, int frame_count) {
ResourceMark rm;
if (frame_count == 0) {
if (method()->name() == vmSymbols::wait_name() &&
instanceKlass::cast(method()->method_holder())->name() == vmSymbols::java_lang_Object()) {
StackValueCollection* locs = locals();
if (!locs->is_empty()) {
StackValue* sv = locs->at(0);
if (sv->type() == T_OBJECT) {
Handle o = locs->at(0)->get_obj();
print_locked_object_class_name(st, o, "waiting on");
}
}
} else if (thread()->current_park_blocker() != NULL) {
oop obj = thread()->current_park_blocker();
Klass* k = Klass::cast(obj->klass());
st->print_cr("\t- %s <" INTPTR_FORMAT "> (a %s)", "parking to wait for ", (address)obj, k->external_name());
}
}
GrowableArray* mons = monitors();
if (!mons->is_empty()) {
bool found_first_monitor = false;
for (int index = (mons->length()-1); index >= 0; index--) {
MonitorInfo* monitor = mons->at(index);
if (monitor->eliminated() && is_compiled_frame()) {
if (monitor->owner_is_scalar_replaced()) {
Klass* k = Klass::cast(monitor->owner_klass());
st->print("\t- eliminated (a %s)", k->external_name());
} else {
oop obj = monitor->owner();
if (obj != NULL) {
print_locked_object_class_name(st, obj, "eliminated");
}
}
continue;
}
if (monitor->owner() != NULL) {
const char *lock_state = "locked";
if (!found_first_monitor && frame_count == 0) {
markOop mark = monitor->owner()->mark();
if (mark->has_monitor() &&
mark->monitor() == thread()->current_pending_monitor()) {
lock_state = "waiting to lock";
}
}
found_first_monitor = true;
print_locked_object_class_name(st, monitor->owner(), lock_state);
}
}
}
}
看到上面的方法,再对比线程dump的结果,我们会发现很多熟悉的东西,比如waiting on,parking to wait for,locked,waiting to lock,而且也清楚了它们分别是在什么情况下会打印的。
那为什么我们的例子中BLOCKED状态的线程本应该打印waiting to lock,但是为什么却打印了locked呢,那说明if (mark->has_monitor() && mark->monitor() == thread()->current_pending_monitor()) 这个条件肯定不成立,那这个在什么情况下不成立呢?在验证此问题前,有必要先了解下markOop是什么东西,它是用来干什么的?
markOop是什么
markOop描述了一个对象(也包括了Class)的状态信息,Java语法层面的每个对象或者Class在JVM的结构表示中都会包含一个markOop作为Header,当然还有一些其他的JVM数据结构也用它做Header。markOop由32位或者64位构成,具体位数根据运行环境而定。
下面的结构图包含markOop每一位所代表的含义,markOop的值根据所描述的对象的类型(比如是锁对象还是正常的对象)以及作用的不同而不同。就算在同一个对象里,它的值也是可能会不断变化的,比如锁对象,在一开始创建的时候其实并不知道是锁对象,会当成一个正常对象来创建(在对象的类型并没有设置偏向锁的情况下,其markOop值可能是0x1),但是随着我们执行到synchronized的代码逻辑时,就知道其实它是一个锁对象了,它的值就不再是0x1了,而是一个新的值,该值是对应栈帧结构里的监控对象列表里的某一个内存地址。
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
就最后的3位而言,其不同的值代表不同的含义:
enum { locked_value = 0,//00
unlocked_value = 1,//01
monitor_value = 2,//10
marked_value = 3,//11
biased_lock_pattern = 5 //101
};
上面的判断条件“mark->has_monitor()”其实就是判断最后的2位是不是10,如果是,则说明这个对象是一个监控对象,可以通过mark->monitor()方法获取到对应的结构体:
bool has_monitor() const {
return ((value() & monitor_value) != 0);
}
ObjectMonitor* monitor() const {
assert(has_monitor(), "check");
// Use xor instead of &~ to provide one extra tag-bit check.
return (ObjectMonitor*) (value() ^ monitor_value);
}
将一个普通对象转换为一个monitor对象的过程(就是替换markOop的值)请参考为ObjectSynchronizer::inflate方法,能进入到该方法说明该锁为重量级锁,也就是说这把锁其实是被多个线程竞争的。
了解了markOop之后,还要了解下上面那个条件里的thread()->current_pending_monitor(),也就是这个值是什么时候设置进去的呢?
线程设置等待的监控对象的时机
设置的逻辑在ObjectMonitor::enter里,关键代码如下:
...
{
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);//设置当前monitor对象为当前线程等待的monitor对象
for (;;) {
jt->set_suspend_equivalent();
EnterI (THREAD) ;
if (!ExitSuspendEquivalent(jt)) break ;
_recursions = 0 ;
_succ = NULL ;
exit (false, Self) ;
jt->java_suspend_self();
}
Self->set_current_pending_monitor(NULL);
}
...
设置当前线程等待的monitorObject是在有中文注释的那一行设置的,那么出现Bug的原因是不是正好在设置之前进行了线程dump呢?
在JVM中只会有一个处于RUNNBALE状态的线程,也就是说另外一个打印"-locked"信息的线程是处于BLOCKED状态的。上面的第一行代码:
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
找到其实现位置:
JavaThreadBlockedOnMonitorEnterState(JavaThread *java_thread, ObjectMonitor *obj_m) :
JavaThreadStatusChanger(java_thread) {
assert((java_thread != NULL), "Java thread should not be null here");
_active = false;
if (is_alive() && ServiceUtil::visible_oop((oop)obj_m->object()) && obj_m->contentions() > 0) {
_stat = java_thread->get_thread_stat();
_active = contended_enter_begin(java_thread);//关键处
}
}
static bool contended_enter_begin(JavaThread *java_thread) {
set_thread_status(java_thread, java_lang_Thread::BLOCKED_ON_MONITOR_ENTER);//关键处
ThreadStatistics* stat = java_thread->get_thread_stat();
stat->contended_enter();
bool active = ThreadService::is_thread_monitoring_contention();
if (active) {
stat->contended_enter_begin();
}
return active;
}
上面的contended_enter_begin方法会设置java线程的状态为java_lang_Thread::BLOCKED_ON_MONITOR_ENTER,而线程dump时根据这个状态打印的结果如下:
const char* java_lang_Thread::thread_status_name(oop java_thread) {
assert(JDK_Version::is_gte_jdk15x_version() && _thread_status_offset != 0, "Must have thread status");
ThreadStatus status = (java_lang_Thread::ThreadStatus)java_thread->int_field(_thread_status_offset);
switch (status) {
case NEW : return "NEW";
case RUNNABLE : return "RUNNABLE";
case SLEEPING : return "TIMED_WAITING (sleeping)";
case IN_OBJECT_WAIT : return "WAITING (on object monitor)";
case IN_OBJECT_WAIT_TIMED : return "TIMED_WAITING (on object monitor)";
case PARKED : return "WAITING (parking)";
case PARKED_TIMED : return "TIMED_WAITING (parking)";
case BLOCKED_ON_MONITOR_ENTER : return "BLOCKED (on object monitor)";
case TERMINATED : return "TERMINATED";
default : return "UNKNOWN";
};
}
正好对应我们dump日志中的信息"BLOCKED (on object monitor)"也就是说这行代码被正常执行了,那问题就可能出在JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this)和Self->set_current_pending_monitor(this)这两行代码之间的逻辑里了:
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);//设置当前monitor对象为当前线程等待的monitor对象
于是检查每一行的实现,前面几行都基本可以排除了,因为它们都是很简单的操作,下面来分析下ThreadBlockInVM tbivm(jt)这一行的实现:
ThreadBlockInVM(JavaThread *thread)
: ThreadStateTransition(thread) {
thread->frame_anchor()->make_walkable(thread);
trans_and_fence(_thread_in_vm, _thread_blocked);
}
void trans_and_fence(JavaThreadState from, JavaThreadState to) {
transition_and_fence(_thread, from, to);
}
static inline void transition_and_fence(JavaThread *thread, JavaThreadState from, JavaThreadState to) {
assert(thread->thread_state() == from, "coming from wrong thread state");
assert((from & 1) == 0 && (to & 1) == 0, "odd numbers are transitions states");
thread->set_thread_state((JavaThreadState)(from + 1));
if (os::is_MP()) {
if (UseMembar) {
OrderAccess::fence();
} else {
InterfaceSupport::serialize_memory(thread);
}
}
if (SafepointSynchronize::do_call_back()) {
SafepointSynchronize::block(thread);
}
thread->set_thread_state(to);
CHECK_UNHANDLED_OOPS_ONLY(thread->clear_unhandled_oops();)
}
...
}
也许我们看到可能造成问题的代码了:
if (SafepointSynchronize::do_call_back()) {
SafepointSynchronize::block(thread);
}
想象一下,当这个线程正好执行到这个条件判断,然后进去了,从方法名上来说是不是意味着这个线程会block住,并且不往后走了呢?这样一来设置当前线程的pending_monitor对象的操作就不会被执行了,从而在打印这个线程栈的时候就会打印"-locked"信息了,那么纠结是否正如我们想的那样呢?
首先来看条件SafepointSynchronize::do_call_back()是否一定会成立:
inline static bool do_call_back() {
return (_state != _not_synchronized);
}
上面的VMThread执行任务的过程中说到了这个状态,当vmThread执行完了SafepointSynchronize::begin()之后,这个状态是设置为_synchronized的。如果正在执行,那么状态是_synchronizing,因此,当我们触发了jvm的线程dump之后,VMThread执行该操作,而且还在执行线程dump过程前,但是还只是_synchronizing的状态,那么do_call_back()将会返回true,那么将执行接下来的SafepointSynchronize::block(thread)方法:
void SafepointSynchronize::block(JavaThread *thread) {
assert(thread != NULL, "thread must be set");
assert(thread->is_Java_thread(), "not a Java thread");
ttyLocker::break_tty_lock_for_safepoint(os::current_thread_id());
if (thread->is_terminated()) {
thread->block_if_vm_exited();
return;
}
JavaThreadState state = thread->thread_state();
thread->frame_anchor()->make_walkable(thread);
switch(state) {
case _thread_in_vm_trans:
case _thread_in_Java: // From compiled code
thread->set_thread_state(_thread_in_vm);
if (is_synchronizing()) {
Atomic::inc (&TryingToBlock) ;
}
Safepoint_lock->lock_without_safepoint_check();
if (is_synchronizing()) {
assert(_waiting_to_block > 0, "sanity check");
_waiting_to_block--;
thread->safepoint_state()->set_has_called_back(true);
DEBUG_ONLY(thread->set_visited_for_critical_count(true));
if (thread->in_critical()) {
increment_jni_active_count();
}
if (_waiting_to_block == 0) {
Safepoint_lock->notify_all();
}
}
thread->set_thread_state(_thread_blocked);
Safepoint_lock->unlock();
Threads_lock->lock_without_safepoint_check();//关键代码
thread->set_thread_state(state);
Threads_lock->unlock();
break;
...
}
if (state != _thread_blocked_trans &&
state != _thread_in_vm_trans &&
thread->has_special_runtime_exit_condition()) {
thread->handle_special_runtime_exit_condition(
!thread->is_at_poll_safepoint() && (state != _thread_in_native_trans));
}
}
void Monitor::lock_without_safepoint_check (Thread * Self) {
assert (_owner != Self, "invariant") ;
ILock (Self) ;
assert (_owner == NULL, "invariant");
set_owner (Self);
}
void Monitor::lock_without_safepoint_check () {
lock_without_safepoint_check (Thread::current()) ;
}
看到上面的实现可以确定,Java线程执行时会调用Threads_lock->lock_without_safepoint_check(),而Threads_lock因为被VMThread持有,将一直卡死在ILock (Self)这个逻辑里,从而没有设置current_monitor属性,由此验证了我们的想法。
Bug修复
在了解了原因之后,我们可以简单的修复这个Bug。将下面两行代码调换下位置即可:
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);//设置当前monitor对象为当前线程等待的monitor对象
该Bug不会对生产环境产生影响,本文主要是和大家分享分析问题的过程,希望大家碰到疑惑都能有一查到底的劲儿,带着问题,不断提出自己的猜想,然后不断验证自己的猜想,最终解决问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK