

GAN Pix2Pix Generative Model
source link: https://towardsdatascience.com/gan-pix2pix-generative-model-c9bf5d691bac?gi=f2ea2272aa01
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Pix2Pix GAN: Introduction
We hear a lot about language translation with deep learning where the neural network learns a mapping from one language to another. In fact, Google translate uses one to translate to more than 100 languages. But, can we do a similar task with images? Certainly, yes! If it’s possible to capture the intricacies of languages, it’ll surely be possible to translate an image to another. Indeed, this shows the power of deep learning.
Pix2Pix GAN paper was published back in 2016 by Phillip Isola , Jun-Yan Zhu , Tinghui Zhou , Alexei A. Efros . Find the paper here . It was later revised in 2018. When it was published, internet users tried something creative. They used the pix2pix GAN system to a variety of different scenarios like a frame-to-frame translation of a video of one person to another, mimicking the former’s moves. Cool, isn’t it? Using pix2pix, we can map any image to any other image like edges of an object to the image of the object. Further, we’ll explore more about its architecture and working in detail. Now, let’s dive right in!

How Pix2Pix GAN works?
cGAN: Overview
Heard about GANs (Generative Adversarial Network) that generate realistic synthetic images? Similarly, Pix2pix belongs to one such type called conditional GAN or cGAN. They have some conditional settings and they learn the image-to-to mapping under this condition. Whereas, basic GAN’s generate images from a random distribution vector with no condition applied. Confused? Try to get this.
Say, we have a GAN trained with the images of the MS-COCO data set. In GANs, the output image that is generated with the generator network is random. That is, it might generate images of any object that was there in the data set. But, with a cGAN, we can generate images what we want. If we want it to generate a person, it’ll generate an image of a person. This is achieved by conditioning the GAN.
Pix2Pix GAN: Overview

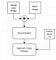
Let’s take another example of image-to-image translation task, ‘black&white to colour image ‘ conversion. In pix2pix cGAN, the B&W image is given as input to the generator model. And, the output of the generated model and the given input (B&W image) pair of images is the generated pair. The B&W input image and the target output (i.e the real colour version of the input B&W image) forms the real pair.
The discriminator classifies a given pair of images as the real pair or the generated pair. The one that is used in Pix2Pix is different from normally how we’d expect a classifier’s output to be. It produces an output classification that classifies multiple patches in the input image pairs (patchGAN). I’ll explain more about it in detail. In the below depictions, concatenation is represented as ⊕.
Pix2Pix GAN Architecture

Pix2Pix GAN has a generator and a discriminator just like a normal GAN would have. But, it is more supervised than GAN (as it has target images as output labels). For our black and white image colourization task, the input B&W is processed by the generator model and it produces the colour version of the input as output. In Pix2Pix, the generator is a convolutional network with U-net architecture.
It takes in the input image (B&W, single-channel), passes it through a series of convolution and up-sampling layers. Finally, it produces an output image that is of the same size as the input but has three channels (colourized). But before training, the generator produces just random output.
After the generator, the synthetic image is concatenated with the target colour image. Therefore, the number of color channels will be six (height x width x 6). This is fed as input to the discriminator network. In Pix2Pix, the authors employ a different type of discriminator network (patchGAN type). The patchGAN network takes the concatenated input images and produces an output that NxN.
Loss Function
Discriminator Loss
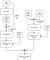
Discriminator loss function measures how good or bad discriminator’s predictions are. The lesser the discriminator loss, the more accurate it becomes at identifying synthetic image pairs.
A normal binary classifier that’s used in GANs produces just a single output neuron to predict real or fake. But, the patchGAN’s NxN output predicts a number of overlapping patches in the input image. For example, in Pix2Pix, the output size is 30x30x1 that predicts for each 70×70 patch of the input. We’ll see more about patchGANs in another post. The 30×30 output is fed to a log loss function that compares it with a 30×30 zero matrix (since it is generated and not real).

This is called generated loss. The real loss is calculated for the pair of B&W and its corresponding color image from the data set. This is a real pair. Hence, ‘real loss’ is the sigmoid cross-entropy of the NxN output and a matrix of ones of the NxN size.
The total discriminator loss is the sum of the above two losses. The gradients of the loss function are computed with respect to the discriminator network and are backpropagated to minimize the loss. While the discriminator loss is back-propagated, weights of the generator network are frozen. Phew! Now we’re almost done.
Generator Loss
The generator loss measures how real the synthetic images look. By minimizing this, the generator could produce more realistic images.
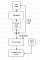
This loss is almost the same as generated loss except that it is the sigmoid cross-entropy of the NxN discriminator output and a matrix of ones. When this loss is back-propagated, the discriminator network’s parameters are frozen. And only the generator’s weights are adjusted.
To improve the aesthetics of the generated image, the authors of the pix2pix paper added an L1 loss term. It calculates the L1 distance between the target image and the generated image. It is then multiplied with a parameter ‘Lambda’ and gets added to the generator loss.
Training the Pix2Pix model
To train the model to convert B&W images to color, we have to feed the network with the input and target images. Hence, any data set with color images like the ImageNet can be used. The data set can be constructed by converting the color images to B&W to form the input. And the color image itself forms the target. Thus, the network can be trained by iterating through the data set, feeding the images to the pix2pix model, one by one or by batch.
And…Done!
That’s pix2pix for you! Hope you got a clear idea about what pix2pix GAN is and how it works.
See how to train a cGAN model yourself on your custom data set.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK