

Why Going from Implementing Q-learning to Deep Q-learning Can Be Difficult
source link: https://towardsdatascience.com/why-going-from-implementing-q-learning-to-deep-q-learning-can-be-difficult-36e7ea1648af?gi=7490cf0b945f
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
3 Questions I was Afraid to Ask (and my Tensorflow 2.0 Template)

Dec 31 ·11min read

For many people, myself included, Q-learning serves as an introduction to the world of reinforcement learning. It gets us neatly accustomed to the core ideas of states, actions and rewards in a way that is intuitive and not bogged down by complicated technical details.
What makes implementing Deep Q-Learning so much more difficult then? While Q-learning took me only a day to go from reading the Wikipedia article to getting something that worked with some OpenAI Gym environments, Deep Q-learning frustrated me for over a week!
Despite the name, Deep Q-learning is not as simple as swapping out a state-action table for a neural network. For me, becoming comfortable with coding Deep Q Networks (DQNs) took three broad steps in understanding:
- Realizing that DQNs refer to a family of value-learning algorithms and the various combinations of engineering improvements that have been made to increase their stability.
- Learning how the Bellman equation based value-iteration in Q-learning is related to the gradient descent updates needed for neural networks.
- Figuring out how to interleave the neural network updates with the agent’s interaction with the environment.
Each of these steps involved errors that I would now be tempted to label “silly” or “basic.” However, one difficulty I find in learning resources is that they present things as a neat, completed story, in contrast to the winding maze of confusion that learning often ends up being.
With that in mind, I will step through the main questions and points of confusion I had in my own learning process in the hope that it makes the path easier for others. I will also build up to an environment-agnostic agent template that I often like to use when beginning reinforcement learning projects, using Tensorflow 2.0 for the neural networks.
Q-Learning Review
Before starting on the 3 questions I had, let’s first review reinforcement learning (RL) and the Q-learning algorithm. The five core concepts of RL are environments, agents, states, actions, and rewards.
An environment is, in practice, some kind of simulation which can be broken down into discrete time-steps. At each step, the agent interacts with the environment by observing its state and taking an action . The goal of each agent (environments can have one or many, competing or collaborating) is to maximize some reward that is a function of its actions and the state of the environment (and often some random elements). Rewards are not necessarily observed at every step, in which case they can be called sparse .
Since the rewards that an agent receives often depend on actions it took many steps ago, a central difficulty of RL is in determining which actions actually led to the rewards. This is known as the credit assignment problem . One broad family of approaches to reinforcement learning involves trying to learn the value of each action, given the state. Defining value to capture a more holistic measure of an action’s worth beyond the immediate reward allows one to attempt to solve the credit assignment problem.
Q-learning is one such value-based approach. In the simplest implementations, the value function is stored as a table with each cell corresponding to the value of an individual action taken from an individual state. Values are updated directly according to this update rule:

To translate learned values into a policy which governs an agents behavior given a state, the maximum value for the given state is selected at each step. While the values are still being learned, a slightly different policy is followed in order to explore the state space, a simple one being an epsilon-greedy strategy, where a random action is taken with a probability that is annealed over time, and the max-value action taken otherwise.
A major limitation of Q-learning is that it is limited to environments with discrete and finite state and action spaces. One solution for extending Q-learning to richer environments is to apply function approximators to learn the value function, taking states as inputs, instead of storing the full state-action table (which is often infeasible). Since deep neural networks are powerful function approximators, it seems logical to try to adapt them for this role.
Wait, Deep Q-Learning doesn’t refer to a single algorithm?
So slap together a neural network and the value-update equation above and you’ve got Deep Q-learning, right? Not quite.
There are a few extra steps that must be taken to successfully carry out what is motivated by the simple replacement of a table with a model. One, which I’ll get to in the next section, is realizing that while the value iteration above can be applied straightforwardly in a model-free situation, updating neural network weights is typically done using backpropagation and gradient descent, which in practice means engineering an appropriate objective function.
But before we get there I’d like to address the fact I wish I had known when I first started learning about Deep Q-learning: on it’s own, learning values using a neural network simply doesn’t work very well . By that I mean: it is unstable and prone to diverging.
Researchers realized this of course, and have since developed a whole slew of incremental add-ons and improvements which successfully stabilize Deep Q-learning. From this emerges the answer to my first major question. When people refer to “Deep Q-learning” they are talking about the core concept of doing Q-learning with a neural network function approximator, but also about the collection of techniques that make it actually work. Thus, the term refers to a whole family of related algorithms, which I feel can be quite confusing to a beginner!
To get an idea of the range of these techniques, I recommend checking on the Rainbow algorithm, so named because it employs a full spectrum of DQN extensions: Double Q-learning, prioritized replay, dueling networks, multi-step learning, distributional RL, and noisy nets.
As a baseline, I recommend implementing DQNs with the main innovations from DeepMind’s 2015 paper, “ Human-level control through deep reinforcement learning ,” which trained DQNs on Atari games.
- Experience Replay : instead of performing a network update immediately after each “experience” (action, state, reward, following state), these experiences are stored in memory and sampled from randomly.
- Separate Target Network : The weights of the neural network responsible for calculating the value of the state reached as a result of an action are frozen, and only periodically copied over from the “online” network.
To get started on the code template, I’ll create mostly empty objects for my agent and my neural network, with some of the parameters and methods I expect to use. Feel free to skip over this snippet if you’re only interested in the finished template.
Since the focus of this article is not on the actual neural network, I’ve gone ahead and started with a simple 2-layer feed-forward network (or multi-layer perceptron). This is usually enough to debug a DQN on simpler environments.
How do I go from updating matrix cells to weights of a neural network?
As I hinted at in the last section, one of the roadblocks in going from Q-learning to Deep Q-learning is translating the Q-learning update equation into something that can work with a neural network. In a Q-learning implementation, the updates are applied directly, and the Q values are model-free, since they are learned directly for every state-action pair instead of calculated from a model.
With a neural network, we ultimately want to update the weights of the model in order to adjust its outputs in a way that is analogous to the Q-learning updates. This is commonly achieved through backpropagation and gradient descent. Fortunately, most deep learning frameworks take care of backpropagating the partial derivatives, so all that needs to be done is to select an appropriate cost function.
It turns out we don’t need to look far. Consider the quantity on the right side of the Q-learning update rule. This is sometimes referred to as the TD-target (for temporal difference), and represents what we want the Q values to converge to: the total expected reward over all remaining timesteps for performing an action, where future rewards are discounted by some factor.
If this TD target is what we want the Q values — that is, the output of our neural network in a DQN setting — to converge to, then it seems appropriate to use a measure of our current output’s distance to the target as our loss function. For this, squared-error is an obvious first choice. Now, if we take the derivative of this loss function with respect to the output layer (the Q-values), and then write a gradient descent update based on this, we see that we recover the Q-learning update rule.



While this isn’t a precise argument, since the Q value outputs themselves are not parameters that get updated during gradient descent, it does satisfy the intuition. However, there are still a couple details that may represent frustrating obstacles when trying to implement this for the first time.
- How do we calculate the value of the next state?
- How do we make it so gradient updates only depend on one Q value at a time, and not the entire output layer?
Our best estimate for the value of the next state is the value of taking what we believe to be the best action in that state. That is:
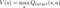
This is where having a separate target network comes into play. Instead of using the online network which is going to have its weights updated, we’ll use the periodically updated target network. And yes, this means that we’re using a less-trained version of the current network to provide part of the objective that is used in training. This general concept is known as bootstrapping .
How then to make each update only correspond to adjusting one Q-value (though of course, all of the weights will be updated, changing how the network interprets states and values actions)? This is one of those instances where compact math notation is not suggestive of what needs to be done in code. It’s easy to write subscripts in an equation, a little harder to translate that to code, and deep learning code at that.
The trick is to select out the Q-value contributing to the objective function using differentiable operations, so that backpropagation will work. It turns out this isn’t too difficult, but it’s annoying that no one seems to talk about it explicitly. One way to do this is by one-hot encoding the action and using this as a mask, multiplying it against the online network’s output. Check out the code snippet below to see these ideas implemented.
How does network training fit in with running episodes from the environment?
Recall that in order to interact with the environment, our agent will need a policy. While some RL agents learn the policy directly, Q-learning agents take the intermediate step of learning the value of each action. This is usually translated into a policy by taking the most valuable action at each step, and because value has expected future rewards baked into it, doing so doesn’t necessarily lead to myopic behavior.
During training, a separate policy can be used in order to better explore the state space. It’s important to recognize that even here, there are multiple options to choose, but the “vanilla” choice would be an epsilon-greedy strategy, which starts out taking completely random actions, and anneals the rate at which random actions are taken over time. One simple way to perform this annealing is linearly, that is, by a small amount every step. Also, by not annealing it all the way to 0, some exploration can be retained even deep into training.
One piece of terminology you may run into at this stage is the distinction between on-policy and off-policy learning. Basically, if an agent is using the same policy to interact with the environment as it is to estimate the value of state-action pairs in its learning updates, then it is on-policy. Since our agent is using an epsilon-greedy policy to explore the environment, but assuming a greedy policy for calculating the value of states in its objective function, it is off-policy. An example of an on-policy RL algorithm that can be used with Q-learning agents is SARSA .
So we use an epsilon-greedy strategy to control the agent during episodes, and update its weights using the TD target with value estimates calculated by a separate target network. What’s left? How to implement experience replay.
In practical terms, this means having a deque -like data structure that stores “experience tuples” as the agent steps through each episode. One silly thing that I got caught-up on was that in a lot of literature, experience tuples are denoted as ( s_t, a_t, r_t, s_(t+1) ), when in actuality, you don’t ever actually know the next state, only the present and past ones. So in the code, you end up storing “last states” and “last actions” in experience tuples that look more like ( s_(t-1), a_(t-1), r_(t-1), s_t ).
Beyond that, it’s just a matter of recognizing that there are some extra decisions that get introduced by experience replay:
- How large do we let the ER memory grow before starting training?
- How many experiences should be stored at most?
- Once training starts, should we train every step or less frequently?
- How many experiences should we sample per training step?
In practice, these decisions all just get encoded as extra parameters for the agent that you can initialize it with. Now that we’ve come this far, I feel ready to share my full DQN template code, that I often use when starting new projects. Note that depending on the details of the environment, there are a few extra steps required to “plug in” the agent and get something functional. In particular, something mapping action indices to actions the environment understands almost always needs to be done. Nevertheless, I hope the following provides some value and speeds up your own experiments.
Conclusion
In this article, I reviewed Q-learning and discussed three questions that made the leap from Q-learning to Deep Q-learning difficult for me. I hope doing so will make it easier for others to make that same leap.
I also shared the template code I use when starting a new reinforcement learning project. Because environments come in many different flavors, the template will almost certainly not work out-of-the-box. The main extensions that are usually required include:
- Translating an integer action into something the environment understands.
- Extracting the features meant for a model from the state, which often contains other metadata.
- Implementing additional logic for detecting and handling the beginnings and endings of episodes.
Next, once everything is plugged in, it’s usually not long until I need to replace the starter network with something more sophisticated or suited for the problem.
With that in mind, I hope that what I’ve provided will be a useful resource, and I hope to hear all about your own reinforcement learning journeys.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK