

【论文】little table / mesa - - SegmentFault 思否
source link: https://segmentfault.com/a/1190000020899473
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
【论文】little table / mesa /confluo/scuba
哎呀,论文总结的越来越应付了,要看的太多,基本都是总结点了,合在一起吧。第一个是little table,第二个是mesa
LittleTable: A Time-Series Database and Its Uses
(2017 cisco meraki)
### 架构
- in-memory tablet
(balanced binary tree??)=>加入list to flush,allocat another
- 索引全内存
- merge table
假设磁盘读速度是120M/s,至少要让seek时间少于1半才有收益,每次至少要读1M,因此buff的量:1000个不同tablets有1G。=》merge table(不按照timespans固定新的是旧的一半大小,就按照tablets size,把新加的和相邻的都聚合在一起) - 插入分4phour,7 dayps,其他pweeks聚合的方式. roll up
- 带时间,为了保证有序,有flush dependency的tablet有向依赖图,
- unique primary keys
检查timestamp是否更新,primar key是否更大,否则需要去磁盘查,在查的时候其他插入到同table的先写到一个小的in-memorytable中,不阻碍这次查询, - lasted row
bloom filter(duplicate kets也可以用) - schema 版本
table descriptor file存当前schema,旧版的随footer。读取组合或者设置默认值 - aggreation
写入时聚合(rrdtool)?后台线程ageregation,选择后者,在aggregation schema变化时轻松应对,就是更灵活吧
纯写内存时300M(cpu),写入文件70M(disk),遇到merge 40M(disk brandwidth)
Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing(google 2014)
data model
每个table有table schema 和aggregation func
updates,分钟级产生,带版本,查询所有版本前的updates聚合返回。版本会roll up。比如base 0-60, 61-70/61-80/61-90,原始61~90
rows blocks。每个block按照column调整顺序压缩,
无状态(controller+update workers/compaction workers/schema chaneg workers/checksum workers)
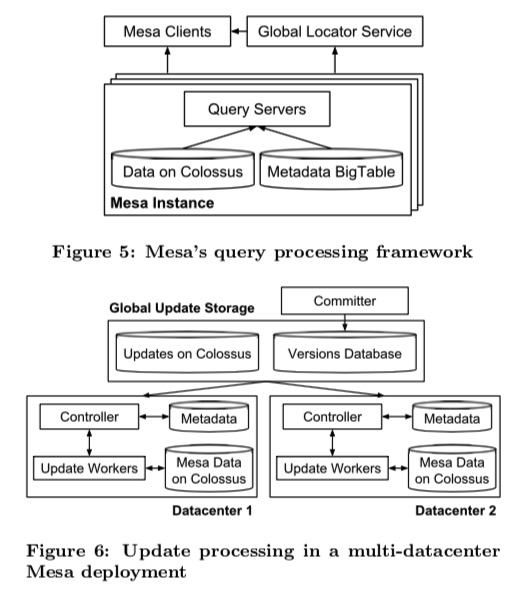
metadata存在bigtable中
数据存在colossus中
查询:pre-fetching and cache colossus中的数据
写入:基于paxos全局的version number和version对应file的位置。version database.controller监听versions database,commiter确保所有相关tables都更新,
返回分成streaming fashion,有resume key,查询中断后切机器继续上次的resume key(查询有这么大?)
来自google的建议
分布式,并行,云计算(pre_fetch+并行来补偿colossum对于local disk的性能影响,利用云计算的性能计算),越简单性能越好。
不要做任何应用层假设(比如meta不会经常变更)。
容错,这个可能一个active的computer只是浮点运算除了问题但是没有发现等等
人员交叉培训
Confluo: Distributed Monitoring and Diagnosis Stack for High-speed Networks
UC Berkeley.2019
应用于网络监控过滤等。这个应用场景只append且不需要按照时间聚合,统计,需要对一个header的所有请求聚合,该领域的FloSIS等也能达到该速率,但是只过滤第一个包对于重传等无法应用,与其他领域数据库比,性能差距很大,单纯的写入吞吐(应用场景不一样,这里BTRDB 16B5M 80m左右和btrdb论文差不多,它可以64b30m的样子千M,我们的就百兆):

功filter,moniTor配置agg,filter,查询
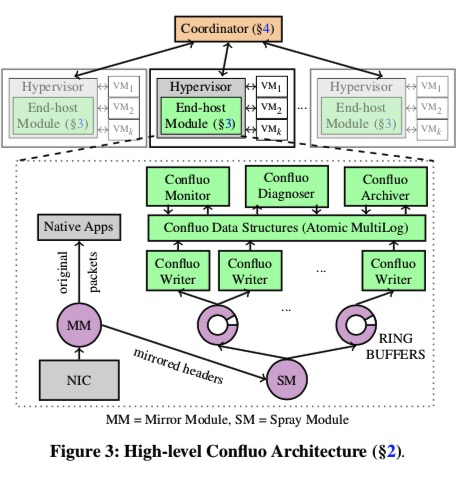
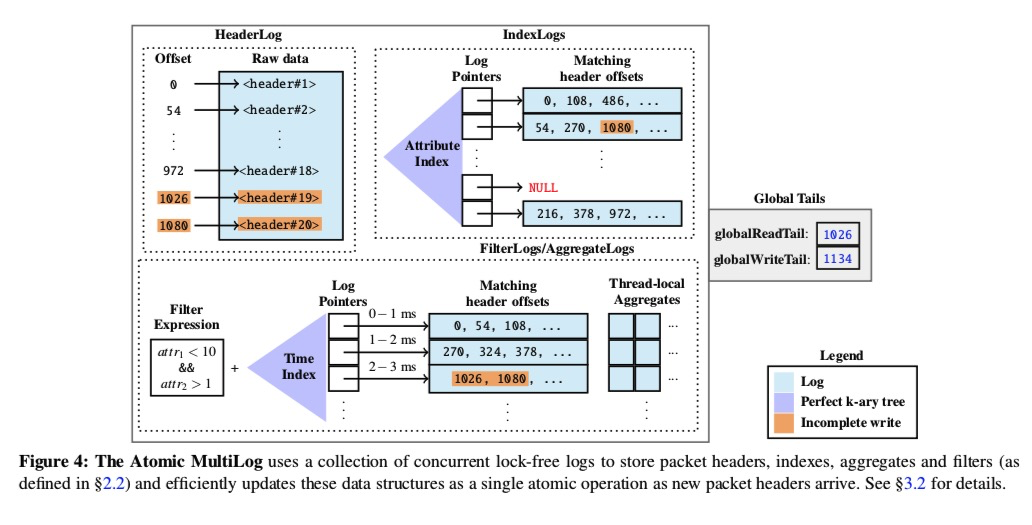
end-host层接受NIC的请求,把header做mirror,通过DPDK传给SM。SM分配到不同的ring buffers中,写入到不同种类的atomic,multilog中。一共有四种log:header log,index,aggre,filter。后面三个都是指向Header log。
header log只有一个。在写入ring buf前,原子增globalwritetail(增加header大小,fetchandadd),当writers读到ringbuffer的header,更新所有相关log,更新Globalreadtail使其可见。
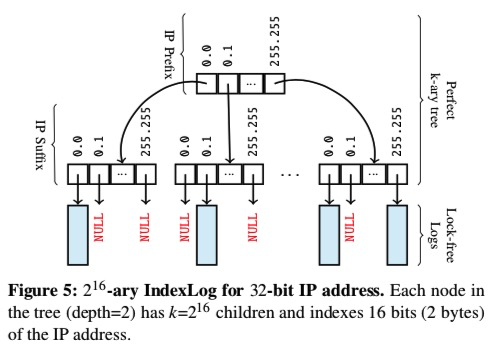
其他有几个index,agg维度就几个log,都是k-ary tree索引叶子是只增offset(指向index),compareandswap
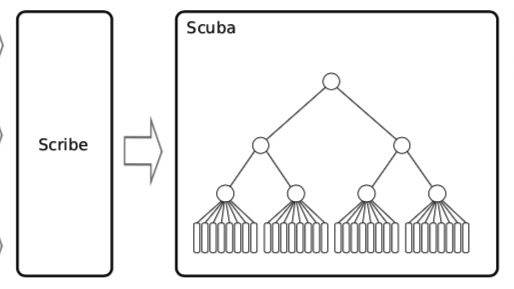
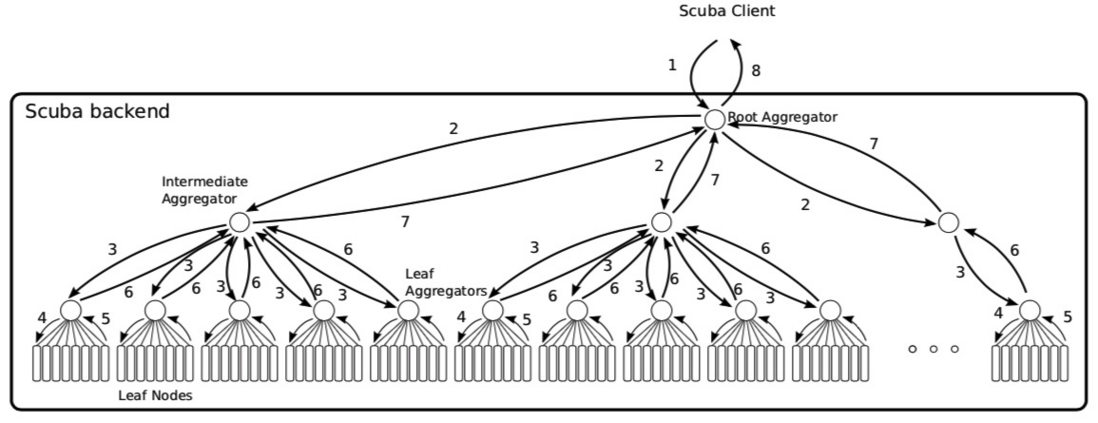
scuba
Scuba: Diving into Data at Facebook(2013比较旧了)
查询性能都是s级别的,
写入时随机选择叶子节点,每个节点包含自己table的schema,每个schema随着每个batch的rows带着。查询aggre的同样的。若某个Leaf查询时间过长,舍弃该leaf
写入:
查询:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK