

Serverless实践系列(一):如何通过SCF与自然语言处理为网站赋能-InfoQ
source link: https://www.infoq.cn/article/bYQRmj5ez*aa9zOKW6qX
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Serverless 实践系列(一):如何通过 SCF 与自然语言处理为网站赋能
发布于:2019 年 8 月 16 日 15:34

自然语言的内容有很多,本文所介绍的自然语言处理部分是“文本摘要”和“关键词提取”。在做博客的时候,经常会发一些文章,这些文章发出去了,有的很容易被搜索引擎检索,有的则很难,那么有没有什么方法,让博客对搜索引擎友好一些呢?
一个比较好的方法就是填写网页的 Description 还有 Keywords。但是每次都需要我们自己去填写,比较繁琐,本文将会分享一种方法:通过 Python 的 jieba 和 snownlp 实现关键词和文本摘要的自动提取。
下载以下资源:
https://github.com/fxsjy/jieba
https://github.com/isnowfy/snownlp
下载之后,新建文件夹,将这些文件中对应的文件拷贝:
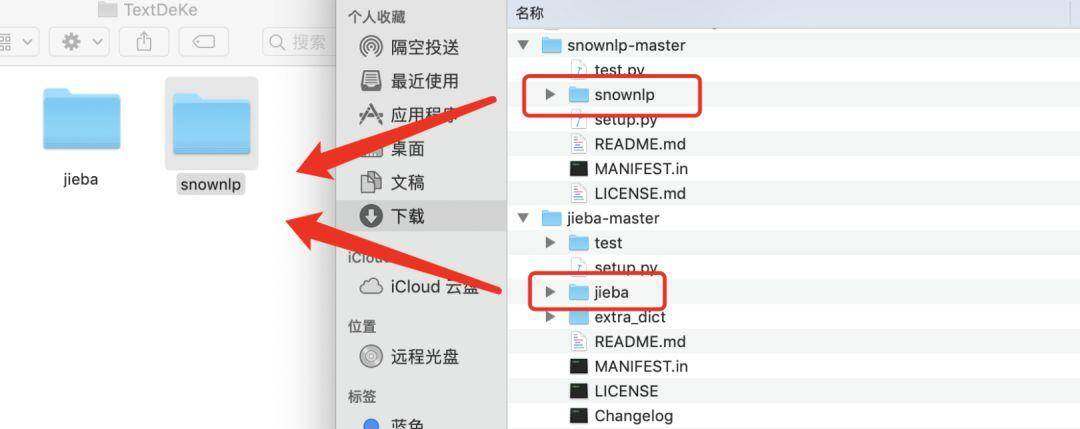
拷贝之后,建立文件 index.py :
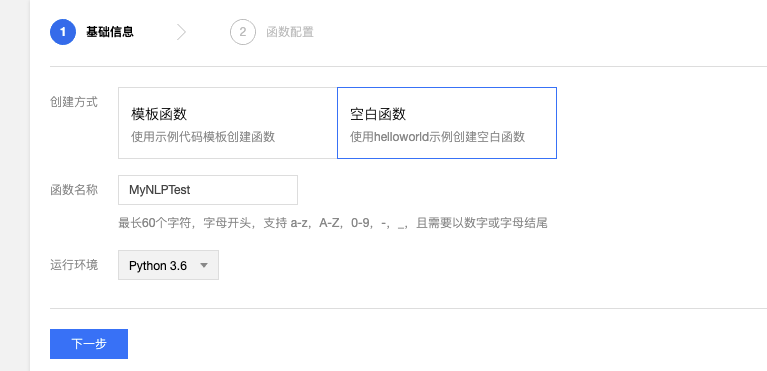
# -*- coding: utf8 -*-import jsonimport jieba.analysefrom snownlp import SnowNLPdef FromSnowNlp(text, summary_num): s = SnowNLP(text) return s.summary(summary_num)def FromJieba(text, keywords_type, keywords_num): if keywords_type == "tfidf": return jieba.analyse.extract_tags(text, topK=keywords_num) elif keywords_type == "textrank": return jieba.analyse.textrank(text, topK=keywords_num) else: return Nonedef main_handler(event, context): text = event["text"] summary_num = event["summary_num"] keywords_num = event["keywords_num"] keywords_type = event["keywords_type"] return {"keywords": FromJieba(text, keywords_type, keywords_num), "summary": FromSnowNlp(text, summary_num)}在 SCF 网页上面建立一个项目:
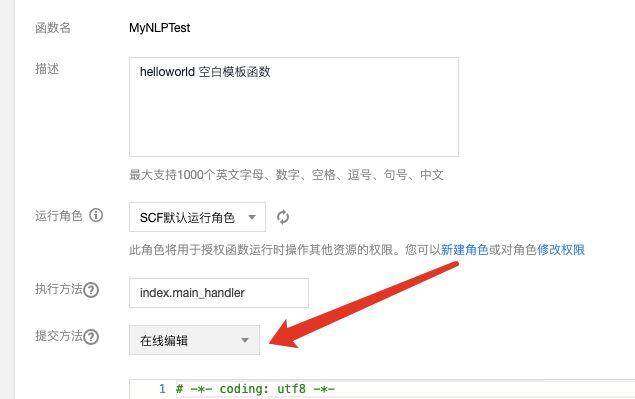
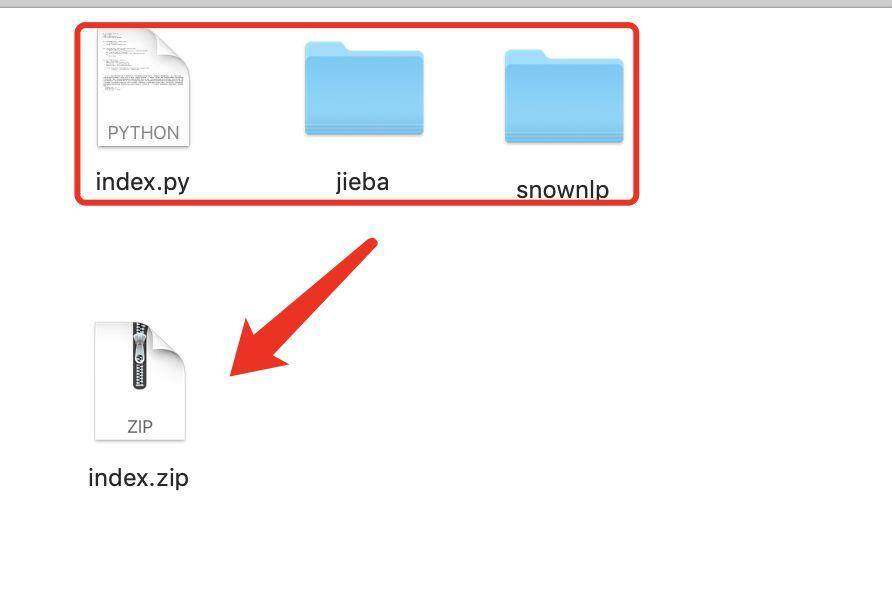
提交方法选择上传 zip,然后压缩文件,并改名为 index.zip:
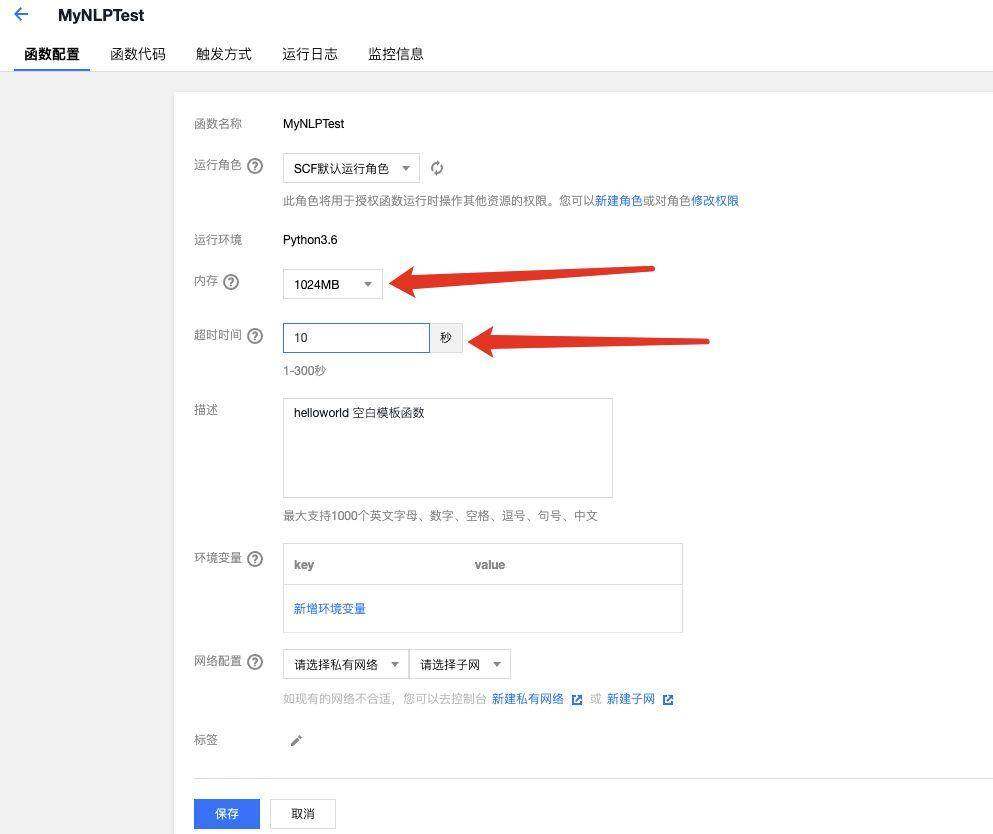
测试之前可以适当调整一下配置:
然后进行 input 模板的输入:
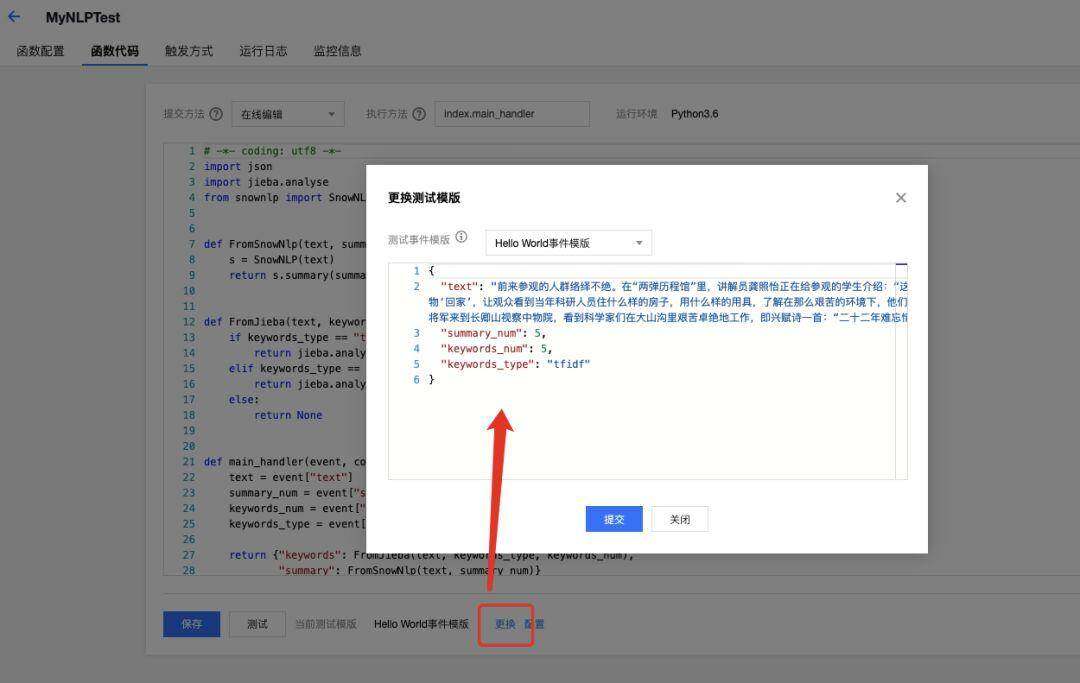
模板可以是:
"text": " 前来参观的人群络绎不绝。在“两弹历程馆”里,讲解员龚照怡正在给参观的学生介绍:“这是我国第一颗核航弹的模型,长 3 米、直径 1.5 米左右,后面就是它爆炸时产生的蘑菇云。”学生们一边听一边认真记录。记者看到,馆内利用声、光、电等手段,通过实物、模型、影像资料和场景复原,展现“两弹”研制工作的艰辛历程。“算盘、计算尺这些文物都是激励后人艰苦奋斗的好教材。我们让文物‘回家’,让观众看到当年科研人员住什么样的房子,用什么样的用具,了解在那么艰苦的环境下,他们是怎样研制‘两弹’的,怎么样让中国挺起了民族的脊梁。”四川省梓潼两弹城红色旅游开发有限公司副总经理贾鲁蓉告诉记者,作为爱国主义教育基地,这里目前存有 2 万多份图片资料、500 多万字文字资料、3000 余件实物。在“两弹历程馆”的不远处是“将军楼”。1983 年 5 月 20 日,时任国防部部长张爱萍将军来到长卿山视察中物院,看到科学家们在大山沟里艰苦卓绝地工作,即兴赋诗一首:“二十二年难忘情,崎岖道路信踏平。屡建奇功震寰宇,更创奇迹惊鬼神。”", "summary_num": 5, "keywords_num": 5, "keywords_type": "tfidf"然后点击测试:
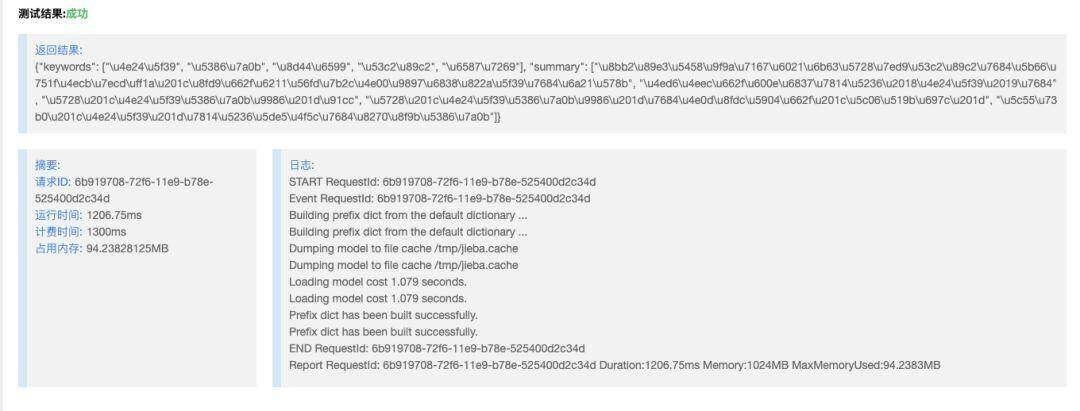
至此,我们完成了简单的关键词提取功能和简单的抽取式文本摘要过程。当然,这部分依旧是一个简单的抛砖引玉,因为摘要这里还要声称是文本摘要,而且抽取式摘要也可能会根据不同的文章类型,有着不同的特色方法,所以这里只是通过一个简单的 Demo 来实现一个小功能,帮助大家做一个简单的 SEO 优化,大家可以在做博客的时候,增加 keywords 或者 description 字段,然后每次从 sql 获得文章数据的时候,将这两个部分放到 meta 中,会大大提高页面被索引的概率。
作者介绍:
刘宇,腾讯云 Serverless 团队后台研发工程师。毕业于浙江大学,先后参与腾讯云云函数产品研发、自动扩缩容、CLI 等模块建设以及社区相关工作。本文转载自微信公众号 ServerlessCloudNative(ID:ServerlessGo)
相关文章:
《Serverless 实践系列(二):为 Python 云函数打包依赖》
《Serverless 实践系列(三):突破传统 OJ 瓶颈,“判题姬”接入云函数》
《Serverless 实践系列(四):网站监控脚本的实现》
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK