

Starbucks Offer Optimisation
source link: https://www.tuicool.com/articles/mauYneq
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Starbucks Offer Optimization

Sep 30 ·18min read

Introduction
Promotional offers are quite prevalent these days. Almost every corporate house that sells consumer products runs some kind of promotional offers -be it due to increased competition, or to expand the customer base or to generate more revenue. Since there is a cost associated with sending these offers, it is of utmost importance to maximize the likelihood of success for these offers by devising effective promotional strategies.
In this post, we will analyze simulated promotional offers data that mimic customer behavior on the Starbucks rewards mobile app. We will use this data to derive business insights and then translate those findings into an ‘explainable’ machine learning model that will predict whether a customer will respond to an offer. The objective is to send offers to only those customers who are more likely to respond and also send only those offers which have the maximum chance of success with a customer.
We will follow the most widely used analytics process model CRISP-DM for this project.
Business understanding
Once every few days, Starbucks sends out an offer to users of the mobile app. An offer can be merely an advertisement for a drink or an actual offer such as a discount or BOGO (buy one get one free). Some users might not receive any offers during certain weeks.
Not all users receive the same offer, and that is the challenge to solve with this data set.
This data set is a simplified version of the real Starbucks app because the underlying simulator only has one product, whereas Starbucks actually sells dozens of products.
Every offer has a difficulty level and also a validity period before the offer expires. As an example, a BOGO offer with a difficulty level of 7, might be valid for only 5 days. This means if a customer spends 7 or more dollars before the offer expiration, he will get 7 dollars worth of product free. Informational offers have a difficulty level of 0 since they don’t require any purchases to be made. They also have a validity period even though these ads are merely providing information about a product; for example, if an informational offer has 7 days of validity, we can assume the customer is feeling the influence of the offer for 7 days after receiving the advertisement.
Then there is customer data which contains demographic information like age, gender, income along with membership start date.
There are transactional data showing user purchases made on the app including the timestamp of purchase and the amount of money spent on a purchase. This transactional data also has a record for each offer that a user receives as well as a record for when a user actually views the offer. There are also records for when a user completes an offer.
We will combine transaction, demographic, and offer data and then label the effective customer-offer combinations. Effective offers are those where the customer was influenced by the offer and made transactions to complete the offer. Next, we will do exploratory data analysis to develop intuition regarding the customer and/or the offer attributes that correlate with offer effectiveness. We will use our findings from the data analysis phase to build a supervised machine learning model that will take combinations of the customer and offer details as input and predict whether it will be an effective combination or not. Offer will be sent only if the model predicts it to be effective for the customer.
Data understanding
In this section, we will have a cursory look at the data to have a high level of understanding of everything available to us in the form of data.
The data is contained in three files:
- portfolio.json — containing offer ids and metadata about each offer (duration, type, etc.)
- profile.json — demographic data for each customer
- transcript.json — records for transactions, offers received, offers viewed, and offers completed
Here is the schema and explanation of each variable in the files:
portfolio.json
- id (string) — offer id
- offer_type (string) — the type of offer i.e., BOGO, discount, informational
- difficulty (int) — the minimum required to spend to complete an offer
- reward (int) — reward given for completing an offer
- duration (int) — time for the offer to be open, in days
- channels (list of strings)

profile.json
- age (int) — age of the customer
- became_member_on (int) — the date when customer created an app account
- gender (str) — gender of the customer (note some entries contain ‘O’ for other rather than M or F)
- id (str) — customer Id
- income (float) — customer’s income

transcript.json
- event (str) — record description (ie transaction, offer received, offer viewed, etc.)
- person (str) — customer Id
- time (int) — time in hours since the start of the test. The data begins at time t=0
- value — (dict of strings) — either an offer id or transaction amount depending on the record

Here is an overview of the data:
- There are 10 offers and a subset of these offers are sent to 17000 customers.
- Offer validity period ranges from 3 to 10 days.
- The difficulty level of the offers ranges from 0 to 20. The easiest offer has a purchase amount threshold of 5 and the hardest offer has a purchase threshold of 20.
- Offer related events and transaction data is available for 30 days. The transcript data has transaction data for 30 days.
- The latest membership was in July 2018, indicating that the data is 1-year -old.
Data Preparation
In here we will do the data wrangling first and then do data analysis using visualizations.
Data cleaning
For each of the data sets, we will assess the inconsistencies and characteristics of the data, and then we will address these together using a cleaning function.
From the data understanding phase, we know the data in customer Id and offer Id columns is not in a user-friendly format. We will need to convert these columns to a more legible format by using a common mapper function that will map unique integer values to each id.
Based on our assessment, below are the cleaning steps we need to follow.
portfolio
- Map unique integer ids to each offer id.
- Split the channels into separate columns.
- Drop the email channel, since it is a common channel for all the offers.
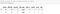
profile
- Map unique integer ids to each person.
- Remove the profiles for the persons aged 118 years since this is a default age populated for persons with missing gender and income data.
- Convert ‘become member on’ to date format.
- Create a new column ‘membership_duration’ from ‘become member on’ as the ‘became_member_on’ column is not very useful in its current format. We will derive membership duration in days for each of the customers by taking the latest ‘became member on’ date as a reference.
- Drop ‘become member on’ column

transcript
The cleanup process is a bit more involved for the transcript data. Here are the initial steps:
- Map unique integer ids to each person and offer using the id mapping dictionaries used in cleaning profile and portfolio data
- Extract amounts, offer ids and rewards from value column
- Covert time from hours to days. Since the offer duration is in days, this will help us compare the data and derive offer expiration date based on offer received date and offer duration.
- Split the transcript data frame into two separate dataframes containing transactions and non-transactions data.

The transaction amounts do not have offer ids mapped to it. So, the only way to know how much a customer spent during a particular offer, is, to sum up, the customer’s transaction amounts during the offer period. Let’s plot the transaction amounts.

Most of the purchase amounts are under 100. However, there are lots of high-value transactions with the max transaction amount being as high as 1062. We know from the portfolio data, that the most difficult offer requires the customer to spend 20 or more. So, the high-value transactions that are way above 20 are probably group orders and not affected by the promotional offers. For our analysis and modeling purposes, we will mark these transactions as outliers by using the max threshold value from the inter-quartile range . During an offer period, if a customer has one or more outlier transactions, we will not consider that as an effective offer for the customer.

Next, we will merge all the datasets into a single dataframe by following the below steps:
- Convert non_transactions data to a wide format by creating separate columns for the events.
- From transaction data, calculate the total amount spent by each customer during the 30 days promotional period. Exclude the outlier transactions from this calculation.
- Merge all the data sets into a single dataframe using the common customer and offer id columns.
- For cases, where customers were sent the same offer multiple times, we will consider only the first one.

Identify Impacted customers
Before we plot the data to look for trends and patterns, we need to categorize the customer and offer id combinations to effective and ineffective categories.
For this, we will look at each promotional offer sent to customers and decide if the offer influenced if him or her. There are four broad categories based on customers’ responses to promotional offers.
- Not Influenced: If a customer viewed the offer but did not complete it, then he was not influenced by the offer. He knew of the offer but did not get influenced to make purchases.
- Influenced: The customer viewed the offer and completed it. The rule of thumb is if the customer was aware of the offer and then opted for and completing it, then the offer influenced him. However, we will exclude those customer-offer combinations that meet this criterion but have outlier transactions during the offer period.
- Completed Without Viewing: The customer completed an offer without viewing it or viewed it post-offer completion. Since he was not aware of the offer, it did not influence him. Probably he or she is a premium customer whose average spend is more than the regular ones irrespective of the promotional offers. Or it could just be a one-off high-value transaction by regular customers. Either way, it differs from the earlier two categories of customer-offer combination. We cannot conclude if the customer would have got influenced had he seen the offer.
- Not Viewed Not Completed — These are incomplete offers that the customers did not view or viewed after the expiry. Again, we cannot say anything conclusive about how the customer would have responded if he or she had viewed the offer.
In the merged data, these categories will be mapped to 0, 1, 2, and 3 respectively.
It is worth mentioning, these are not groupings of customers, rather customer-offer combinations since the same customer can respond differently to different offers. Also, ideally we would clean up the data related to the third and fourth categories. But before that, we will plot the data for all four categories and see how they compare with each other.
Another thing to note here is that, since informational offers were never completed, by default they will fall under the ‘not influenced’ category.
Data Analysis
In this section, we will perform visual data analysis to derive some critical insights into the data and find answers related to relevant business questions.
We will plot some of the customers and offer attributes to develop an intuition about how these attributes contribute to the customer’s response to the promotional offers. During our visual analysis of these plots, we will ignore the trends for informational offers.
Categorical features
For categorical features, we will judge the influence by comparing the response ratio (influenced vs not influenced) for various categories.
Offer type

- It seems customers responded better to Discounts than BOGO offers.
Offer Id

- Based on customer response ratio, offer ids 7,6 and 4 respectively are the top 3 offers. Here are the details for these offers.
7: Spend 10 dollars within 10 days and get 2 dollars as a discount.
6: Spend 7 dollars within 7 days and get 3 dollars as a discount.
4: Spend 5 dollars within 7 days and get 5 dollars worth of product free.
- An interesting point to note here is that BOGO offers with the same level of difficulty(offer ids 1 and 2) as offer id 7 and even a higher reward ratio had a lower success rate. It seems customers preferred to buy the product at a discounted amount than getting an extra product for free.
Difficulty

- Offers with difficulty level 7 had the best response ratio.
- For the offer with the highest difficulty level, most of the offers were not viewed by the customer. However, there is no clear correlation between the difficulty level and response ratio.
Duration

- Offers with longer durations had a better success rate probably because customers get a longer time window to make more purchases.
Gender
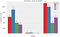
- Females have a better response ratio than their male counterparts.
- Although there was a comparatively lesser no of customers belonging to ‘Other’ gender, their response ratio was better than the males.
Numerical features
Next, we will explore the influence of numerical features in successful offers. For this, we will compare the distribution of the feature for responsive and not responsive offers.
Total Amount Spent
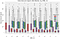
- The customers who were influenced by the offers spent significantly more per hour on average than the ones who did not respond. This is on expected lines.
- The total spent amounts were almost always under 200 dollars.
- Offer Ids 5 and 10 which had the difficulty level of 20 and 10 respectively had slightly higher distribution in total spent amounts.
- There seem to be two broad categories. Those who completed the offers(category 1 and 2) and those who did not(category 0 and 3).
- 0 and 1 have similar distributions of total amounts spent, as do segments 2 and 3.
- And there is no clear trend to demarcate the viewed and not viewed segments from one another. Let’s see if this trend holds for other customer attributes like age, income and membership duration.
Income

- Most of the offers were sent to customers belonging to the 40–80k income bracket.
- Across the offers, the influenced segment belongs to the higher income group than their non-influenced counterparts. It is safe to surmise that customers belonging to higher income groups are more likely to respond to the promotional offers, irrespective of the offer variety.
- Just like ‘total amounts spent’, segments 1 and 2 share similarity as do segments 0 and 3. The similarities are less profound than what we saw for ‘total amounts spent’.
- Unlike ‘total amounts spent,’ there is no clear separation between completed and not completed segments.
Age

- Most of the offers were sent to 40 to 70-year-old customers.
- The separation between different segments is not as profound for ‘age’ distribution as it was for income and total amount spent. However, category 3 seems to always belong to a lower age group as compared to the rest of the categories. The youngest members are more likely to not view and/or not complete the offers.
Membership duration

- Most of the offers were sent to customers with less than 2 years of membership.
- On average, customers who responded to the offers have been a member for a longer time than the ones who did not.
- Membership duration does a good job of separating the different segments. It appears to be an important feature for determining the customer’s likelihood of response to an offer.
- Also, the trend observed in ‘amount spent per hour’ seems to more or less hold here as well, i.e., categories 1 and 2 share a similarity. As does categories 0 and 3. However, category 3 has a wider distribution of membership than category 0.
Feature creation
Extending from the above visualizations, we will create some features that will segregate the continuous features like age, income and membership duration to various demographic groups.
We will compare these demographic groups to understand which among them responds better to the offers.
Difficulty ratio
Difficulty ratio is created by dividing offer difficulty with duration.

- Offers with a lower difficulty ratio seem to have a better response rate.
Income groups
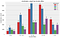
- The response ratio was best for customers in the 100k+ income bracket, followed by the customers in the 80–100k income bracket.
- A positive correlation between income and customer response is clear from the above visualization.
- We can safely infer that people with an income greater than 60k are more likely to respond to the offers.
Membership spans

- Customers with less than 1 year of membership were the least responsive customers.
- The most responsive customers are those who have been members for 1 to 2.5 years (365–900 days), followed by those with 2.5–4 years of membership.
- After reaching a high around 1–2.5 years of membership, the response rate decreases continually with an increase in membership duration.
Age groups
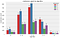
- The response ratio was best for customers in the 80+ age group, followed by the customers in the 61–80 age group.
- There is a positive correlation between age and the customer’s response. Older customers seem to have a better response ratio than their younger counterparts.
- It is probably safe to infer that customers older than 40 years are more likely to respond to the offers.
Modeling and Evaluation
In this part, we will build a predictive model that will predict if a customer is likely to respond to an offer. Since sending offers costs the organization, we don’t want to send offers to customers who are not likely to respond. Also, we don’t want to miss out on sending offers to the customers who will actually respond. As we need to optimize both precision and recall, we will use the F1 score as the model evaluation metric.
Select features for predictive model
As a first step, we need to select only relevant features for the model. Our goal is to build a predictive model that classifies if a customer and offer id combination is effective or not, based on the customer’s demographic data and offer attributes. We will drop everything related to transaction data including the ‘total amount spent’. Though, ‘total amount spent’ does a good job of separating ‘influenced’ and ‘not influenced’ categories, including it as an independent feature will cause data leakage .
Also from the Data Analysis section, it is safe to surmise that there is no clear trend that separates category 2 from the other categories. Though categories 1 and 2 share similarities, we can’t merge them because there may be some high-value customers inside category 2 who on average spend more than regular customers. Sending offers to these customers does not make much of a business sense. We can’t merge category 2 with the ‘not influenced’ group because there is no similarity between the two groups.
However, we can merge categories 0 and 3 as they share similar traits and it is okay to not send offers to customers who did not view the offer and are most likely not going to respond even after viewing.
Naive predictor
We will start with a naive classifier that randomly classifies all the customer and offer id combinations to ‘influenced’ or ‘not influenced’.
This is simply to show how a base model with no intelligence would perform. We can use this to compare the performance of the machine learning algorithm we will be building.
It seems if we distribute the offers randomly, there is a 50% chance of having a successful offer.
Prepare Data for Modeling
Many machine learning algorithms work better when features are on a relatively similar scale and close to normally distributed. The usual process is to apply transformations, for instance, the log transformation that removes skewness from numerical features. Also, it is better to one-hot-encod e categorical features to avoid introducing ordinality in nominal variables among other reasons.
For our initial model, we will not apply the numerical transformation. Later on, we will explore this option for improving model performance.
Initial Model Evaluation
We will consider following supervised models and see which one generalizes best to the dataset:
- Logistic Regression
- Ada Boost
- Random Forest
- Light GBM
For each of these models, we will use 5-fold Cross-Validation to see how the model score varies on different subsets of data. For now, we will leave the model parameters at the default settings.
Here is the result:
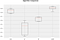
LightGBM is the winner here. It has the best average Cross-Validation score and the low standard deviation value for the cross-validation scores indicates the robustness of the model with the variation in input data.
Feature Importance and Model Explainability
We will check the feature importance of the model using permutation importance . It determines the weight of the input variables by checking how much model outcome changes by dropping the variable or shuffling the rows.

Offer difficulty, membership duration, income, reward, and gender seem to be the most important features.
Next, we will look at a sample prediction using lime to interpret how the model makes a prediction.
Sample explanation for prediction on a validation data row :


The decision boundaries seem to more or less confirm the intuition we developed during the EDA phase.
Performance Tuning
In this section, we will try to improve upon the model score further by tuning the LightGBM model’s parameters using RandomizedSearchCV .
- num_leaves: Large value for num_leaves helps improve accuracy but might lead to over-fitting. To prevent that, we should let it be smaller than 2^(max_depth).
- min_data_in_leaf: Its optimal value depends on the number of training samples and num_leaves. Setting it to a large value can avoid growing too deep a tree, but may cause under-fitting. In practice, setting it to hundreds or thousands is enough for a large dataset.
- max_depth: max_depth is used to limit the tree depth explicitly.
- boosting_type: ‘dart’ usually gives better accuracy
We could optimize the model to achieve a better score (.80) as compared to the un-optimized model’s score (0.79) with default parameters. And if we compare with the naive predictor, using this model can significantly improve our chances of a successful offer than just randomly distributing the offers.
Conclusion
Reflections:
- Cleaning up transcript data was one of the most challenging aspects of this project.
- The difficulty level and reward amount of offers along with membership duration, income, and age of customers are the most important features that determine the chances of offer success.
- Discount offers type, longer duration, lesser difficulty level are some of the offers attributes that increase the probability of a successful offer.
- Some of the customers attribute that increases response probability are higher income(>60 k), longer membership(sweet spot is in 1 to 2.5 years range), female gender and higher age(>40 years).
Scope for Improvement:
- There is still scope for improving the model performance further. We can simply try out other high-performance models like XGboost, Catboost to see if they generalize better than LightGBM. Another strategy commonly used for improving model performance is Stacking a bunch of models together. Also, this one being an imbalanced dataset, another option that we can certainly explore SMOTE to oversample data from the minority class.
- Using transaction data for predicting customer’s responses would result in data leakage. However, historical data related to customers’ purchase amounts can help us in predicting if a customer will respond to an offer or not. For instance, if a customer’s average spending is much more than the regular customer, sending the low difficulty offers to them does not make much of a business sense. We would rather send the high difficulty offers to them. Also, with the current data, it is difficult to judge if informational offers had any influence. A comparison of the customer’s historical average spending rate with the offer period average spending rate would have helped us determine the effect of informational offers.
- There are lots of cases where customers availed of the offer without viewing it. From a business perspective, we would ideally want to avoid sending those offers. During our analysis, we could not find attributes that can help predict this segment of customers. However, a way around would be to make the offers coupon-based. That way only the customers wanting to avail the offers will complete the offers.
- Since all offers were not sent to all the users, we can create a data set by mapping all offers to all customers and then predict customer’s responses for each of the offers. If a customer is likely to respond to multiple offers, we need to pick only the ones which bring maximum business, for instance, the offers with the highest difficulty or the lowest reward ratio.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK