

用Python偷偷告诉你国庆8亿人都去哪儿浪?
source link: http://developer.51cto.com/art/201909/603717.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
用Python偷偷告诉你国庆8亿人都去哪儿浪?
祖国 70 周年的华诞一天天临近,各行各业都在为祖国母亲庆祝生日。作为一个 IT 人,也想贡献一份绵薄之力。
【51CTO.com原创稿件】祖国 70 周年的华诞一天天临近,各行各业都在为祖国母亲庆祝生日。作为一个 IT 人,也想贡献一份绵薄之力。

图片来自 Pexels
据文化和旅游部消息称,预计 2019 年国庆旅游人次有望达到近 8 亿。

#国庆假期或有近 8 亿人次出游#这个话题还冲上了微博热搜榜。

我仿佛已经看到了假期景区人山人海的画面!
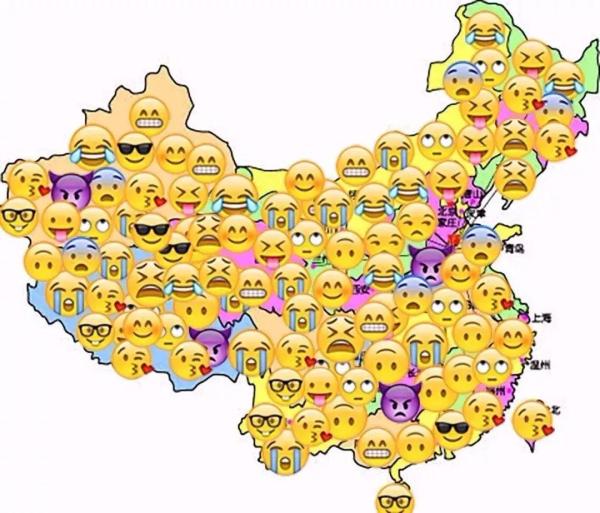
左思右想,最后落脚到国庆长假的旅游上,能否用网络爬虫看看,十一长假哪些城市最堵?哪些景区最热门?

今天一起来看看,如何利用网络爬虫生成国庆期间的旅游热点图吧。
需求构思
制作一张旅游热点图,我们想要达到的效果是,在一张中国地图上面标注出旅游热点。
通过这张图可以知道哪些城市,或者哪些区域是十一期间的旅游热点。也就是说哪些地方在国庆期间去玩的人多。

首先,我们要找一个数据源能够获取全国旅游信息。这里有一个思路就是订票信息,哪些景点的订票比较多,那么这些景点所在的城市就越热门。类似的售票网站比较多,例如:携程,去哪儿,途牛旅游之类的。
然后,需要分析网站上面的票务数据,将我们感兴趣的旅游热点信息爬取下来。分析信息的重点是针对网页 HTML 信息的解析。
之后,将分析完毕的信息按照一定格式保存到本地,由于下载的信息可能和最终展示信息存在偏差,所以需要做一些数据清洗和数据聚合的操作。
最后,将整理好的信息输入到地图上显示出来,这也是最后展示的环节。这里可以选择对外展示的方式,例如:点图,线图,或者热力图。
网站分析
全局预览
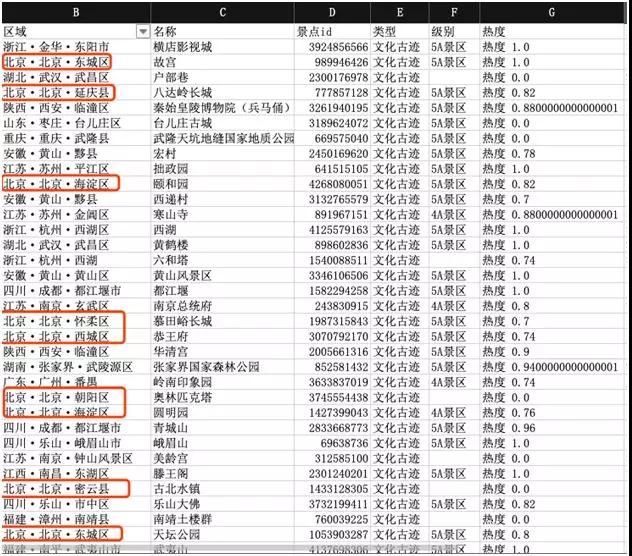
找了一圈旅游网站以后,发现在“去哪儿”的门票页面中,有一个对旅游景点热度的展示信息。
网页会根据不同类型景点(自然风光,文化古迹等)进行查询,查询的结果会显示景点名称,景点热度和城市信息。
如果我们将这些景点对应的区域的热度进行汇总,就可以知道哪些区域对应的景点热度了。
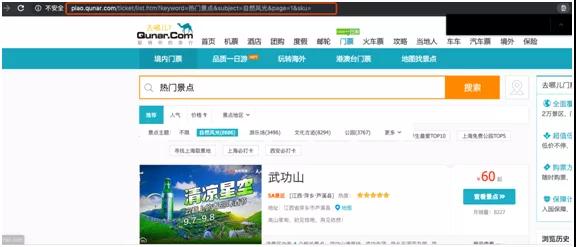
先打开去哪儿旅游,搜索“热门景点”。下面列出了各个地方的热门旅游景点。
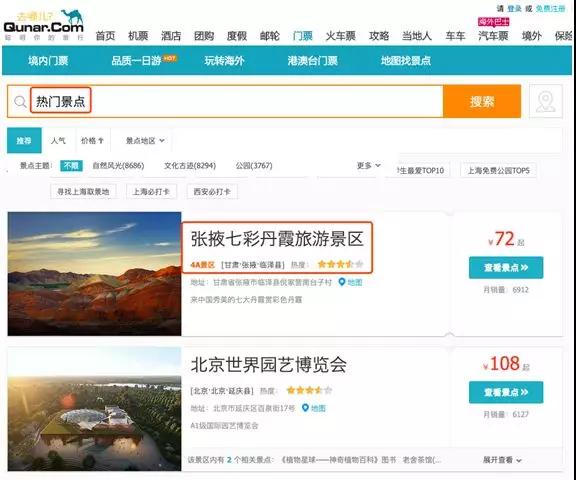
针对景点主题做了分类,在展示的列表中,有景点名称,景点级别,所在省市,以及热度。其中省市和热点是我们关心的数据。
URL 分析
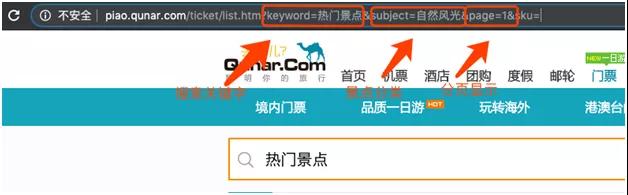
URL 分析图
打开 Chrome 的开发者工具来看看 HTML 页面的结构。URL 的规律很容易能够看明白:
- Keyword 就是“热门景点”,它是个常量,每次请求填写这个就行了。
- Subject 是景点分类,例如:自然风光,游乐场,文化古迹等等。这个需要一一罗列出来,是在一个变量后面用数组存放。
- Page 是页数,如果我们要爬取所有的信息,需要一页一页往下翻,所以这个数字会不断增长。页面滑动到最下方的时候,会看到 Next 按钮,可以通过这个按钮将所有页面都遍历到。
URL 全景图
页面元素分析
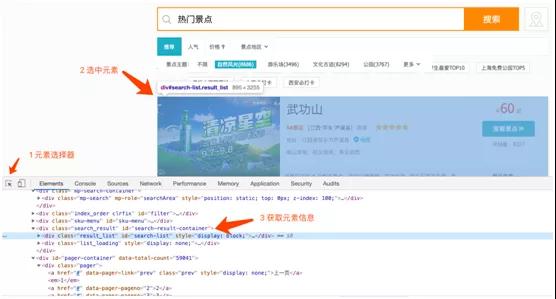
通过 Chrome 开发者工具中的元素选择器,可以清楚地看到元素的 HTML 标签。
列表元素图
由于景点信息放在一个列表中,所以找到列表所在的元素,它放在 id 为“search-list”的 div 中。
也就是说在请求 URL 并获取 HTML 之后,我就需要找到“search-list”div 并且获取其中对应的项目信息。
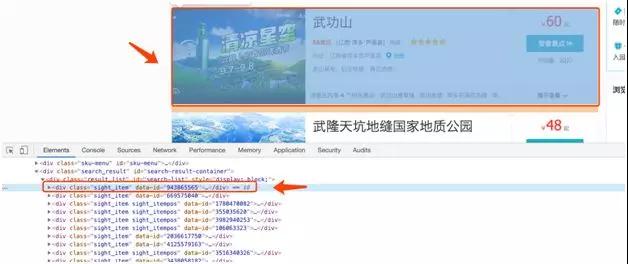
获取了列表元素之后,再来看看每一项旅游纪录中的值如何获取。其内容放在”sight_item”的 div 中。
列表中每项的示意图
接下来分别将景点名称,景点级别,所在省市,热度,地址分别做分析。并且记录他们元素的值在后面解析 HTML 的时候可以用到。
元素的 HTML 标签获取类似上面两个元素。把上面这些元素的 ID 或者 Class 可以先记录下来,在后面解析 HTML 的时候会用到。
爬虫准备
构思和分析都完毕了,我们需要编写代码来实现想法。但是,在这之前我们需要把开发环境以及需要的工具准备好。
由于涉及到网络爬虫,以及图形的展示。所以这里计划使用 Python 作为开发语言,IDE 环境使用 PyCharm,展示图表用到 Pyecharts。
普及一下 Pyecharts,Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。
而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,Pyecharts 就诞生了。
因此,Pyecharts 可以理解为用 Python 来实现的 Echarts 程序,可以在 Python 上面运行,并且提供良好的地理信息展示。
Pyecharts 图标
另外 Pyecharts 的地理展示功能比较强大,这点也是我们需要利用的。

Pyecharts 展示中国地图
针对 HTML 的解析我们使用了 BeautifulSoup。它是一个可以从 HTML 或 XML 文件中提取数据的 Python 库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。

BeautifulSoup 官网图片
爬虫编码
万事具备只欠东风,让我们开始写代码吧,为国庆搬砖让我快乐。这里我们把程序分成两个部分来写,一部分是爬取旅游热点信息,另一部分是旅游热点地图展示。
爬取旅游热点信息
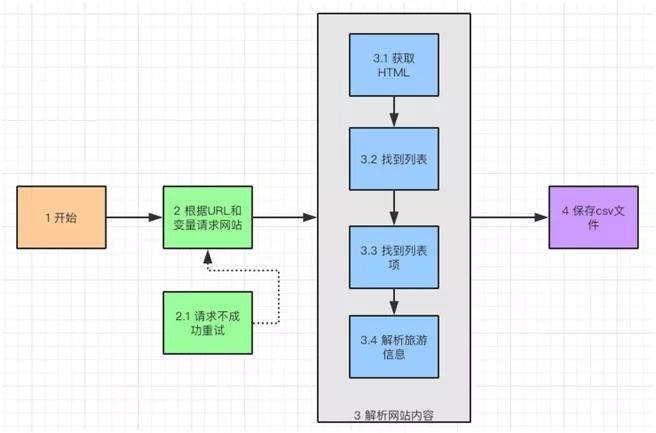
程序流水图
先说一下获取旅游热点信息的思路,大约分为四步:
- 开始准备必要的文件和引入组件包。
- 组合变量 URL 并且做网络请求,请求不成功进行重试。
- 下载 HTML 以后对其进行解析,找到旅游热点列表,列表项,分析具体旅游信息。
- 把分析完的信息保存到 csv 文件中。
因为我们需要请求网络,解析 HTML,保存文件,所以需要引入一些 Python 的包:
- HTML 解析
- 读写 csv
- 在请求头中伪装浏览器
- 错误重试,等待时间
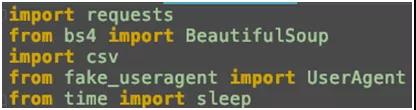
接下来就是创建请求头,请求头中包括了请求的浏览器,语言,请求格式等信息。
这里我们是使用 fake_useragent 中 UserAgent 的 random 方法随机产生浏览器的信息。
这样在模拟浏览器访问网站的时候,每次请求都会随机模拟一种浏览器。例如:IE,Firefox,Chrome 等等。让网站认为是不同的人,用不同的浏览器来访问网站的。
接下来生成一个 csv 文件,用 utf-8 格式保存。这个文件是用来存放爬虫信息。
在文件的表头,我们分别定义了,“区域”,“名称”等和景点相关的字段。在文件生成的时候就准备好这些列,等填入数据以后,可以方便查看。

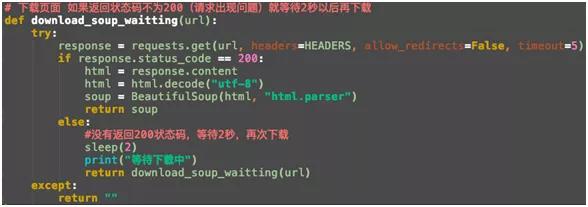
定义一个下载景点内容的函数,这个函数接受 URL 作为参数,然后通过 requests 对象下载景点内容。

由于下载信息可能会遇到网络问题,导致下载失败。所以,我们需要定义一个下载失败函数,在下载不成功的时候重试下载。
还记得之前分析的 URL 吗?景点的类型和分页是变量,这里我们定义一个生成 URL 的函数来处理这些变量。
我们会罗列需要搜索的景点类型在其中。Keyword 字段已经转换成 ACSII 码了,如果需要直接输入中文字符,可以使用 from urllib.parse import quote 来实现。
另外,我们的开始搜索的页面,使用 page=1,之后会解析页面中的“next”按钮,完成翻页的功能。

好了,到此我们定义了文件,下载函数,重试下载函数,分类搜集函数,现在要定义最重要的 HTML 解析函数了。它的输入参数是景点类型和 URL 地址。
依次执行以下工作:
- 下载 HTML,并且转换成 SOUP 对象。
- 找到旅游景点的列表。找到 div 的 id 为‘search-list’的元素。用 soup 的 find 方法找到它。
- 针对景点的项目进行遍历。在‘search-list’元素下面,通过 findAll 方法找到 class 是‘sight_item’的项目,并且对其进行遍历。
- 解析具体景点信息:名称,区域,省市,热度,地址等等。
- 找到翻页按钮,继续往下载后面的页面,并且再次解析。通过 find 方法找到 class 是‘next’的 a 标签。

最后,执行 main 函数运行整个 Python 程序:
下载完成的 csv 图
csv 看上去比较凌乱,把文件通过 xls 打开,看看格式化以后的热点信息:
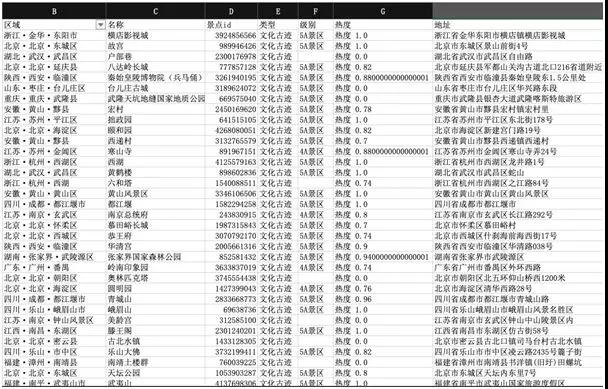
整理以后的旅游热点图
旅游热点地图展示
好了旅游热点的信息已经抓到了,现在开始分析。这里建议将抓取和分析工作分成两块来进行。
因为,在抓取过程中会遇到网络问题,解析问题或者反爬虫的问题,而且抓取数据需要一段时间。
为了保证其独立性,所以信息抓取可以单独运行。当完成以后,把抓取的文件作为输入放到展示程序中运行。
展示程序主要完成,数据清洗,汇总求和以及展示地图的工作。这样前面的爬虫和后面的分析展示就连成一体了。
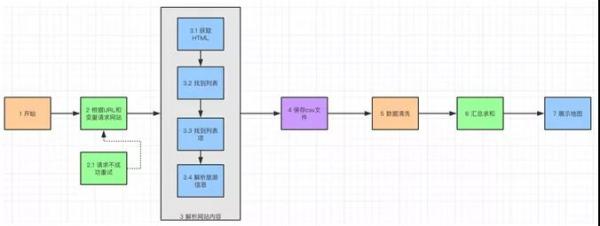
旅游热点分析流程图
首先我们依旧要引入几个 Python 包,如下。其中 Geoopts 和 ChartType 都是用来展示地图用的。

其次,我们需要装载 csv 文件。虽然我们下载了很多信息,但是对于我们最重要的其实是省市和热点信息。因为我们最后展示出来的就是,哪个城市是旅游的热点。
城市,热度信息图
根据观察,要计算城市的热度,必须将城市信息分组以后求和,这个也是需要考虑的。
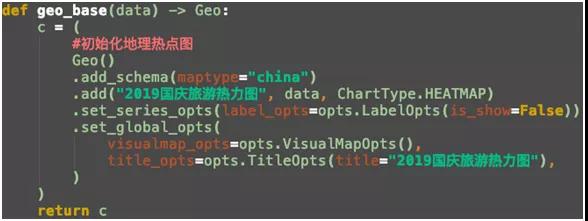
根据城市信息对热度求和
将一些地图中无法识别的地点,以及一些没有热度值的脏数据过滤掉,就可以将生成的城市,热度列表传给展示函数了。

最后,展示函数接受到列表参数,绘制热力图:
结果分析
先看看哪些区域是大家比较喜欢的旅游目的地,如下图:
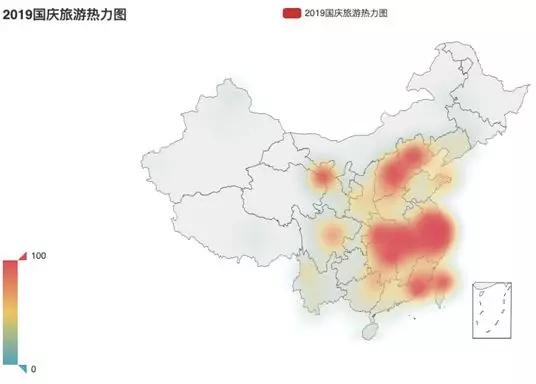
2019 国庆旅游热力图
从图上可以看出北京,沿海地区(福建,广州),江浙地区,甘肃地区是国庆期间比较热门的景点。中部地区的武汉,由于军运会将至,也成为了旅游的热门城市。

2019 国庆旅游热点图
再来看看,TOP 20 的旅游热点城市,如下图:
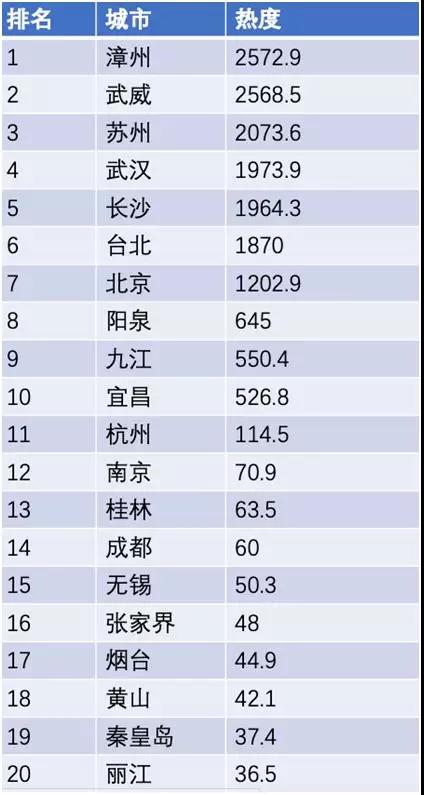
TOP 20 的 5A 旅游景点:
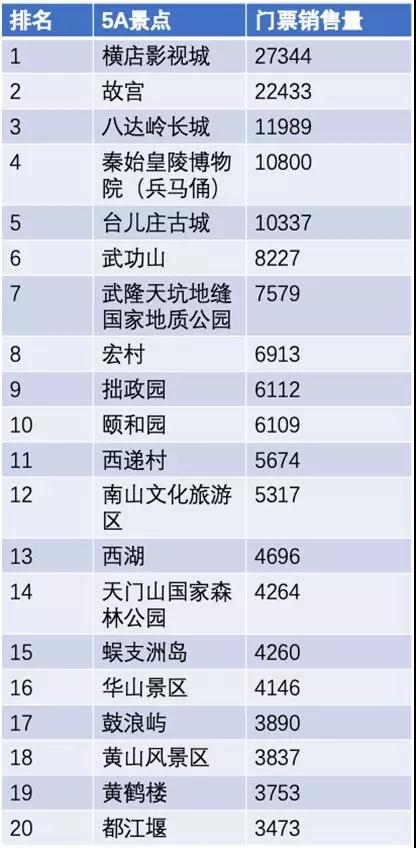
总结
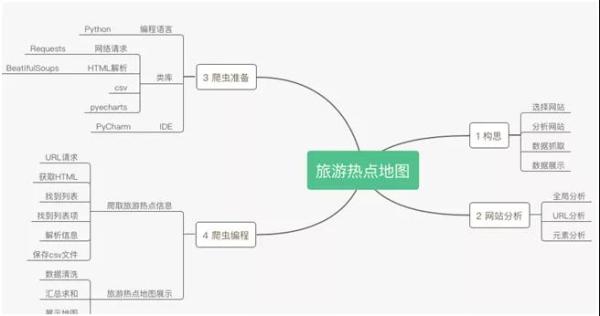
爬虫思维导图
在网络爬虫之前需要根据达到的目标进行构思,包括:选择网站,分析网站,数据抓取,数据展示。
在分析网站时,需要注意以下几点,包括全局分析,URL 分析,元素分析。
在爬虫编程之前,需要针对工具,IDE,Python 类库进行准备。爬虫编码分为,爬取旅游热点信息和旅游热点地图展示。
作者:崔皓
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】
【编辑推荐】
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK