

Go微服务容错与韧性(Service Resilience) - - SegmentFault 思否
source link: https://segmentfault.com/a/1190000020503704?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Go微服务容错与韧性(Service Resilience)
Service Resilience是指当服务的的运行环境出现了问题,例如网络故障或服务过载或某些微服务宕机的情况下,程序仍能够提供部分或大部分服务,这时我们就说服务的韧性很强。它是微服务中很重要的一部分内容,并被广泛讨论。它是衡量服务质量的一个重要指标。Service Resilience从内容上讲翻译成“容错”可能更接近, 但“容错”英文是“Fault Tolerance”,它的含义与“Service Resilience”是不同的。因此我觉得翻译成“服务韧性“比较合适。服务韧性在微服务体系中非常重要,它通过提高服务的韧性来弥补环境上的不足。
服务韧性通过下面几种技术来提升服务的可靠性:
- 服务超时 (Timeout)
- 服务重试 (Retry)
- 服务限流(Rate Limiting)
- 熔断器 (Circuit Breaker)
- 故障注入(Fault Injection)
- 舱壁隔离技术(Bulkhead)
程序实现:
服务韧性能通过不同的方式来实现,我们先用代码的来实现。程序并不复杂,但问题是服务韧性的代码会和业务代码混在一起,这带来了以下问题:
- 误改业务逻辑:当你修改服务韧性的代码时有可能会失手误改业务逻辑。
- 系统架构不够灵活:将来如果要改成别的架构会很困难,例如将来要改成由基础设施来完成这部分功能的话,需要把服务韧性的代码摘出来,这会非常麻烦。
- 程序可读性差:因为业务逻辑和非功能性需求混在一起,很难看懂这段程序到底需要完成什么功能。有些人可能觉得这不很重要,但对我来说这个是一个致命的问题。
- 加重测试负担:不管你是要修改业务逻辑还是非功能性需求,你都要进行系统的回归测试, 这大大加重了测试负担。
多数情况下我们要面对的问题是现在已经有了实现业务逻辑的函数,但要把上面提到的功能加入到这个业务函数中,又不想修改业务函数本身的代码。我们采用的方法叫修饰模式(Decorator Pattern),在Go中一般叫他中间件模式(Middleware Pattern)。修饰模式(Decorator Pattern)的关键是定义一系列修饰函数,每个函数都完成一个不同的功能,但他们的返回类型(是一个Interface)都相同,因此我们可以把这些函数一个个叠加上去,来完成全部功能。下面看一下具体实现。
我们用一个简单的gRPC微服务来展示服务韧性的功能。下图是程序结构,它分为客户端(client)和服务端(server),它们的内部结构是类似的。“middleware”包是实现服务韧性功能的包。 “service”包是业务逻辑,在服务端就是微服务的实现函数,客户端就是调用服务端的函数。在客户端(client)下的“middleware”包中包含四个文件并实现了三个功能:服务超时,服务重试和熔断器。“clientMiddleware.go"是总入口。在服务端(server)下的“middleware”包中包含两个文件并实现了一个功能,服务限流。“serverMiddleware.go"是总入口。
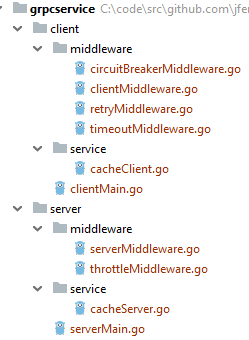
修饰模式:
修饰模式有不同的实现方式,本程序中的方式是从Go kit中学来的,它是我看到的是一种最灵活的实现方式。
下面是“service”包中的“cacheClient.go", 它是用来调用服务端函的。“CacheClient”是一个空结构,是为了实现“CallGet()”函数,也就实现了“callGetter”接口(下面会讲到)。所有的业务逻辑都在这里,它是修饰模式要完成的主要功能,其余的功能都是对它的修饰。
type CacheClient struct {
}
func (cc *CacheClient) CallGet(ctx context.Context, key string, csc pb.CacheServiceClient) ( []byte, error) {
getReq:=&pb.GetReq{Key:key}
getResp, err :=csc.Get(ctx, getReq )
if err != nil {
return nil, err
}
value := getResp.Value
return value, err
}
func (cc *CacheClient) CallStore(key string, value []byte, client pb.CacheServiceClient) ( *pb.StoreResp, error) {
storeReq := pb.StoreReq{Key: key, Value: value}
storeResp, err := client.Store(context.Background(), &storeReq)
if err != nil {
return nil, err
}
return storeResp, err
}下面是客户端的入口文件“clientMiddleware.go". 它定义了”callGetter“接口,这个是修饰模式的核心,每一个修饰(功能)都要实现这个接口。接口里只有一个函数“CallGet”,就是这个函数会被每个修饰功能不断调用。 这个函数的签名是按照业务函数来定义的。它还定义了一个结构(struct)CallGetMiddleware,里面只有一个成员“Next”, 它的类型是修饰模式接口(callGetter),这样我们就可以通过“Next”来调用下一个修饰功能。每一个修饰功能结构都会有一个相应的修饰结构,我们需要把他们串起来,才能完成依次叠加调用。
“BuildGetMiddleware()”就是用来实现这个功能的。CircuitBreakerCallGet,RetryCallGet和TimeoutCallGet分别是熔断器,服务重试和服务超时的实现结构。它们每个里面也都只有一个成员“Next”。在创建时,要把它们一个个依次带入,要注意顺序,最先创建的 “CircuitBreakerCallGet” 最后执行。在每一个修饰功能的最后都要调用“Next.CallGet()”,这样就把控制传给了下一个修饰功能。
type callGetter interface {
CallGet(ctx context.Context, key string, c pb.CacheServiceClient) ( []byte, error)
}
type CallGetMiddleware struct {
Next callGetter
}
func BuildGetMiddleware(cc callGetter) callGetter {
cbcg := CircuitBreakerCallGet{cc}
tcg := TimeoutCallGet{&cbcg}
rcg := RetryCallGet{&tcg}
return &rcg
}
func (cg *CallGetMiddleware) CallGet(ctx context.Context, key string, csc pb.CacheServiceClient) ( []byte, error) {
return cg.Next.CallGet(ctx, key, csc)
}服务重试:
当网络不稳定时,服务有可能暂时失灵,这种情况一般持续时间很短,只要重试一下就能解决问题。下面是程序。它的逻辑比较简单,就是如果有错的话就不断地调用“tcg.Next.CallGet(ctx, key, csc)”,直到没错了或达到了重试上限。每次重试之间有一个重试间隔(retry_interval)。
const (
retry_count = 3
retry_interval = 200
)
type RetryCallGet struct {
Next callGetter
}
func (tcg *RetryCallGet) CallGet(ctx context.Context, key string, csc pb.CacheServiceClient) ( []byte, error) {
var err error
var value []byte
for i:=0; i<retry_count; i++ {
value, err = tcg.Next.CallGet(ctx, key, csc)
log.Printf("Retry number %v|error=%v", i+1, err)
if err == nil {
break
}
time.Sleep(time.Duration(retry_interval)*time.Millisecond)
}
return value, err
}服务重试跟其他功能不同的地方在于它有比较大的副作用,因此要小心使用。因为重试会成倍地增加系统负荷,甚至会造成系统雪崩。有两点要注意:
- 重试次数:一般来讲次数不要过多,这样才不会给系统带来过大负担
- 重试间隔时间:重试间隔时间要越来越长,这样能错开重试时间,而且越往后失败的可能性越高,因此间隔时间要越长。一般是用斐波那契数列(Fibonacci sequence)或2的幂。当然如果重试次数少的话可酌情调整。示例中用了最简单的方式,恒定间隔,生产环境中最好不要这样设置。
并不是所有函数都需要重试功能,只有非常重要的,不能失败的才需要。
服务超时:
服务超时给每个服务设定一个最大时间限制,超过之后服务停止,返回错误信息。它的好处是第一可以减少用户等待时间,因为如果一个普通操作几秒之后还不出结果就多半出了问题,没必要再等了。第二,一个请求一般都会占用系统资源,如线程,数据库链接,如果有大量等待请求会耗尽系统资源,导致系统宕机或性能降低。提前结束请求可以尽快释放系统资源。下面是程序。它在context里设置了超时,并通过通道选择器来判断运行结果。当超时时,ctx的通道被关(ctx.Done()),函数停止运行,并调用cancelFunc()停止下游操作。如果没有超时,则程序正常完成。
type TimeoutCallGet struct {
Next callGetter
}
func (tcg *TimeoutCallGet) CallGet(ctx context.Context, key string, c pb.CacheServiceClient) ( []byte, error) {
var cancelFunc context.CancelFunc
var ch = make(chan bool)
var err error
var value []byte
ctx, cancelFunc= context.WithTimeout(ctx, get_timeout*time.Millisecond)
go func () {
value, err = tcg.Next.CallGet(ctx, key, c)
ch<- true
} ()
select {
case <-ctx.Done():
log.Println("ctx timeout")
//ctx timeout, call cancelFunc to cancel all the sub-processes in the calling chain
cancelFunc()
err = ctx.Err()
case <-ch:
log.Println("call finished normally")
}
return value, err
}这个功能应该设置在客户端还是服务端?服务重试没有问题只能在客户端。服务超时在服务端和客户端都可以设置,但设置在客户端更好,这样命运是掌握在自己手里。
下一个问题是顺序选择。 你是先做服务重试还是先做服务超时?结果是不一样的。先做服务重试时,超时是设定在所有重试上;先做服务超时,超时是设定在每一次重试上。这个要根据你的具体需求来决定,我是把超时定在每一次重试上。
服务限流(Rate Limiting):
服务限流根据服务的承载能力来设定一个请求数量的上限,一般是每秒钟能处理多少个并发请求。超过之后,其他所有请求全部返回错误信息。这样可以保证服务质量,不能得到服务的请求也能快速得到结果。这个功能与其他不同,它定义在服务端。当然你也可以给客户端限流,但最终还是要限制在服务端才更有意义。
下面是服务端“service”包中的“cacheServer.go", 它是服务端的接口函数。“CacheService”是它的结构,它实现了“Get”函数,也就服务端的业务逻辑。其他的修饰功能都是对他的补充修饰。
// CacheService struct
type CacheService struct {
Storage map[string][]byte
}
// Get function
func (c *CacheService) Get(ctx context.Context, req *pb.GetReq) (*pb.GetResp, error) {
fmt.Println("start server side Get called: ")
//time.Sleep(3000*time.Millisecond)
key := req.GetKey()
value := c.Storage[key]
resp := &pb.GetResp{Value: value}
fmt.Println("Get called with return of value: ", value)
return resp, nil
}
...
下面是“serverMiddleware.go”,它是服务端middleware的入口。它定义了结构“CacheServiceMiddleware”, 里面只有一个成员“Next", 它的类型是 “pb.CacheServiceServer”,是gRPC服务端的接口。注意这里我们的处理方式与客户端不同,它没有创建另外的接口, 而是直接使用了gRPC的服务端接口。客户端的做法是每个函数建立一个入口(接口),这样控制的颗粒度更细,但代码量更大。服务端所有函数共用一个入口,控制的颗粒度较粗,但代码量较少。这样做的原因是客户端需要更精准的控制。具体实现时,你可以根据应用程序的需求来决定选哪种方式。“BuildGetMiddleware”是服务端创建修饰结构的函数。ThrottleMiddleware是服务限流的实现结构。它里面也只有一个成员“Next”。在创建时,要把具体的middleware功能依次带入,现在只有一个就是“ThrottleMiddleware”。
type CacheServiceMiddleware struct {
Next pb.CacheServiceServer
}
func BuildGetMiddleware(cs pb.CacheServiceServer ) pb.CacheServiceServer {
tm := ThrottleMiddleware{cs}
csm := CacheServiceMiddleware{&tm}
return &csm
}
func (csm *CacheServiceMiddleware) Get(ctx context.Context, req *pb.GetReq) (*pb.GetResp, error) {
return csm.Next.Get(ctx, req)
}
func (csm *CacheServiceMiddleware) Store(ctx context.Context, req *pb.StoreReq) (*pb.StoreResp, error) {
return csm.Next.Store(ctx, req)
}
func (csm *CacheServiceMiddleware) Dump(dr *pb.DumpReq, csds pb.CacheService_DumpServer) error {
return csm.Next.Dump(dr, csds)
}下面是服务限流的实现程序,它比其他的功能要稍微复杂一些。其他功能使用的的控制参数(例如重试次数)在执行过程中是不会被修改的,而它的(throttle)是可以并行读写的,因此需要用“sync.RWMutex”来控制。具体的限流功能在“Get”函数中,它首先判断是否超过阀值(throttle),超过则返回错误信息,反之则运行。
const (
service_throttle = 5
)
var tm throttleMutex
type ThrottleMiddleware struct {
Next pb.CacheServiceServer
}
type throttleMutex struct {
mu sync.RWMutex
throttle int
}
func (t *throttleMutex )getThrottle () int {
t.mu.RLock()
defer t.mu.RUnlock()
return t.throttle
}
func (t *throttleMutex) changeThrottle(delta int ) {
t.mu.Lock()
defer t.mu.Unlock()
t.throttle =t.throttle+delta
}
func (tg *ThrottleMiddleware) Get(ctx context.Context, req *pb.GetReq) (*pb.GetResp, error) {
if tm.getThrottle()>=service_throttle {
log.Printf("Get throttle=%v reached\n", tm.getThrottle())
return nil, errors.New("service throttle reached, please try later")
} else {
tm.changeThrottle(1)
resp, err := tg.Next.Get(ctx, req)
tm.changeThrottle(-1)
return resp, err
}
}熔断器 (Circuit Breaker):
熔断器是最复杂的。 它的主要功能是当系统检测到下游服务不畅通时对这个服务进行熔断,这样就阻断了所有对此服务的调用,减少了下游服务的负载,让下游服务有个缓冲来恢复功能。与之相关的就是服务降级,下游服务没有了,需要的数据怎么办?一般是定义一个降级函数,或者是从缓存里取旧的数据或者是直接返回空值给上游函数,这要根据业务逻辑来定。下面是它的服务示意图。服务A有三个下游服务,服务B,服务C,服务D。其中前两个服务的熔断器是关闭的,也就是服务是畅通的。服务D的熔断器是打开的,也就是服务异常。
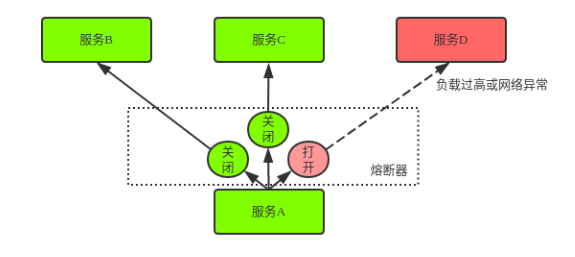
熔断器用状态机(State Machine)来进行管理,它会监测对下游服务的调用失败情况,并设立一个失败上限阀值,由阀值来控制状态转换。它有三个状态:关闭,打开和半打开。这里的“关闭“是熔断器的关闭,服务是打开的。下面是它的简单示意图。

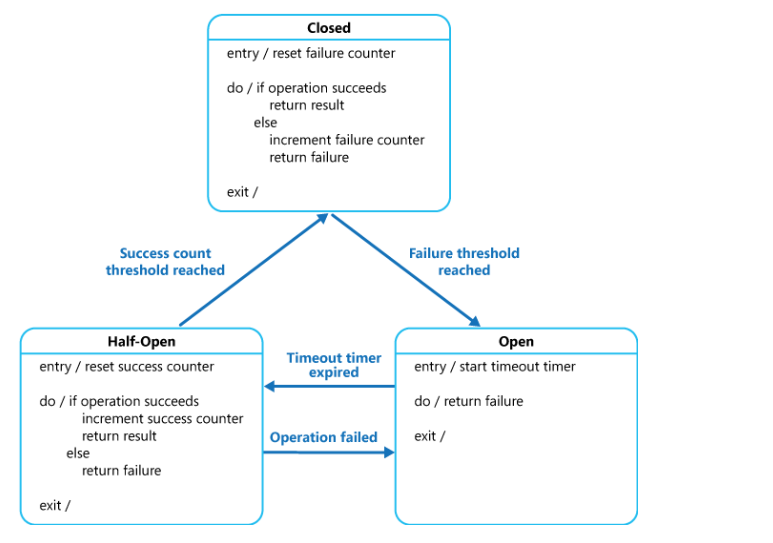
正常情况熔断器是关闭的,当失败请求数超过阀值时,熔断器打开,下游服务关闭。熔断器打开是有时间限制的,超时之后自动变成半打开状态,这时只放一小部分请求通过。当请求失败时,返回打开状态,当请求成功并且数量超过阀值时,熔断器状态变成关闭,恢复正常。下面是它的详细示意图。它图里有伪程序,可以仔细读一下,读懂了,就明白了实现原理。
当有多个修饰功能时,咋一看熔断器应该是第一个执行的,因为如果服务端出了问题最好的对策就是屏蔽掉请求,其他的就不要试了,例如服务重试。但仔细一想,这样的话服务重试就没有被熔断器监控,因此熔断器还是最后一个执行好。不过具体情况还是要根据你有哪些修饰功能来决定。
熔断器有很多不同的实现,其中最出名的可能是Netflix的“Hystrix”。本程序用的是一个go开源库叫gobreaker, 因为它比较纯粹(Hystrix把很多东西都集成在一起了),当然熔断的原理都是一样的。下面是熔断器的程序。其中“cb”是“CircuitBreaker”的变量,它是在“init()”里面创建的,这样保证它只创建一次。在创建时,就设置了具体参数。“MaxRequests”是在半开状态下允许通过的最大请求数。”Timeout“是关闭状态的超时时间(超时后自动变成半开状态),这里没有设置,取缺省值60秒。“ReadyToTrip”函数用来控制状态转换,当它返回true时,熔断器由关闭变成打开。熔断器的功能是在函数“CallGet”中实现的,它的执行函数是“cb.Execute”, 只要把要运行的函数传入就行了。如果熔断器是打开状态,它就返回缺省值,如果熔断器是关闭状态,它就运行传入的请求。熔断器自己会监测请求的执行状态并根据它的信息来控制开关转换。
var cb *gobreaker.CircuitBreaker
type CircuitBreakerCallGet struct {
Next callGetter
}
func init() {
var st gobreaker.Settings
st.Name = "CircuitBreakerCallGet"
st.MaxRequests = 2
st.ReadyToTrip = func(counts gobreaker.Counts) bool {
failureRatio := float64(counts.TotalFailures) / float64(counts.Requests)
return counts.Requests >= 2 && failureRatio >= 0.6
}
cb = gobreaker.NewCircuitBreaker(st)
}
func (tcg *CircuitBreakerCallGet) CallGet(ctx context.Context, key string, c pb.CacheServiceClient) ( []byte, error) {
var err error
var value []byte
var serviceUp bool
log.Printf("state:%v", cb.State().String())
_, err = cb.Execute(func() (interface{}, error) {
value, err = tcg.Next.CallGet(ctx, key, c)
if err != nil {
return nil, err
}
serviceUp = true
return value, nil
})
if !serviceUp {
//return a default value here. You can also run a downgrade function here
log.Printf("circuit breaker return error:%v\n", err)
return []byte{0}, nil
}
return value, nil
}本示例中熔断器是设置在客户端的。从本质上来讲它是针对客户端的功能,当客户端察觉要调用的服务失效时,它暂时屏蔽掉这个服务。但我觉得它其实设置在服务端更有优势。 设想一下当有很多不同节点访问一个服务时,当然也有可能别人都能访问,只有我不能访问。这基本可以肯定是我的节点和服务端节点之间的链接出了问题,根本不需要熔断器来处理(容器就可以处理了)。因此,熔断器要处理的大部分问题是某个微服务宕机了,这时监测服务端更有效,而不是监测客户端。当然最后的效果还是要屏蔽客户端请求,这样才能有效减少网络负载。这就需要服务端和客户端之间进行协调,因此有一定难度。
另外还有一个问题就是如何判断服务宕机了,这个是整个熔断器的关键。如果服务返回错误结果,那么是否意味着服务失效呢?这会有很多不同的情况,熔断器几乎不可能做出完全准确的判断,从这点上来讲,熔断器还是有瑕疵的。我觉得要想做出准确的判断,必须网络,容器和Service Mesh进行联合诊断才行。
故障注入(Fault Injection)
故障注入通过人为地注入错误来模拟生产环境中的各种故障和不稳定性。你可以模拟10%的错误率,或服务响应延迟。使用的技术跟上面讲的差不多,可以通过修饰模式来对服务请求进行监控和控制,来达到模拟错误的目的。故障注入既可以在服务端也可以在客户端。
舱壁隔离技术(Bulkhead)
舱壁隔离技术指的是对系统资源进行隔离,这样当一个请求出现问题时不会导致整个系统的瘫痪。比较常用的是Thread pool和Connection pool。比如系统里有数据库的Connection Pool,它一般都有一个上限值,如果请求超出,多余的请求就只能处于等待状态。如果你的系统中既有运行很慢的请求(例如报表),也有运行很快的请求(例如修改一个数据库字段),那么一个好的办法就是设立两个Connection Pool, 一个给快的一个给慢的。这样当慢的请求很多时,占用了所有Connection Pool,但不会影响到快的请求。下面是它的示意图,它用的是Thread Pool。

Netflix的Hystrix同时集成了舱壁隔离技术和熔断器,它通过限制访问一个服务的资源(一般是Thread)来达到隔离的目的。它有两种方式,第一种是通过Thread Pool, 第二种是信号隔离(Semaphore Isolation)。也就是每个请求都要先得到授权才能访问资源,详细情况请参阅这里.
舱壁隔离的实际应用方式要比Hystrix的广泛得多,它不是一种单一的技术,而是可以应用在许多不同的方向(详细情况请参阅这里) 。
新一代技术--自适应并发限制(Adaptive Concurreny Limit)
上面讲的技术都是基于静态阀值的,多数都是每秒多少请求。但是对于拥有自动伸缩(Auto-scaling)的大型分布式系统,这种方式并不适用。自动伸缩的云系统会根据服务负载来调整服务器的个数,这样服务的阀值就变成动态的,而不是静态的。Netflix的新一代技术可以建立动态阀值,它叫自适应并发限制(Adaptive Concurrency Limit)。它的原理是根据服务的延迟来计算负载,从而动态地找出服务的阀值。一旦找出动态阀值,这项技术是很容易执行的,困难的地方是如何找出阀值。这项技术可以应用在下面几个方向:
- RPC(gRPC):既可以应用在客户端,也可以应用在服务端。可以使用拦截器(Interceptor)来实现
- Servlet: 可以使用过滤器来实现(Filter)
- Thread Pool:这是一种更通用的方式。它可以根据服务延迟来自动调节Thread Pool的大小,从而达到并发限制。
详细情况请参见Netflix/concurrency-limits.
Service Mesh实现:
从上面的程序实现可以看出,它们的每个功能并不复杂,而且不会对业务逻辑进行侵入。但上面只是实现了一个微服务调用的一个函数,如果你有很多微服务,每个微服务又有不少函数的话,那它的工作量还是相当大的。有没有更好的办法呢?当我接触服务韧性时,就觉得直接把功能放到程序里对业务逻辑侵入太大,就用了拦截器(Interceptor),但它不够灵活,也不方便。后来终于找到了比较灵活的修饰模式的实现方式,这个问题终于解决了。但工作量还是太大。后来看到了Service Mesh才发现问题的根源。因为服务韧性本来就不是应用程序应该解决的问题,
而是基础设施或中间件的主场。这里面涉及到的许多数据都和网络和基础设施相关,应用程序本来就不掌握这些信息,因此处理起来就束手束脚。应用程序还是应该主要关注业务逻辑,而把这些跨领域的问题交给基础设施来处理。
我们知道容器技术(Docker和Kubernetes)的出现大大简化了程序的部署,特别是对微服务而言。但一开始服务韧性这部分还是由应用程序来做,最有名的应该是“Netflix OSS”。现在我们把这部分功能抽出来, 就是Service Mesh, 比较有名的是Istio和Linkerd。当然Service Mesh还有其它功能,包括网路流量控制,权限控制与授权,应用程序监测等。它是在容器的基础上,加强了对应用程序的管理并提供了更多的服务。
当用Service Mesh来实现服务韧性时,你基本不用编程,只需要写些配置文件,这样更加彻底地把它与业务逻辑分开了,也减轻了码农的负担。但它也不是没有缺点的,编写配置文件实际上是另一种变向的编程,当文件大了之后很容易出错。现在已经有了比较好的支持容器的IDE,但对Service Mesh的支持还不是太理想。另外,就是这个技术还比较新,有很多人都在测试它,但在生产环境中应用的好像不是特别多。如果想要在生产环境中使用,需要做好准备去应对各种问题。当然Service Mesh是一个不可阻挡的趋势,就像容器技术一样,也许将来它会融入到容器中,成为容器的一部分。有关生产环境中使用Service Mesh请参阅“下一代的微服务架构基础是ServiceMesh?”
Service Mesh的另一个好处是它无需编程,这样就不需要每一种语言都有一套服务韧性的库。当然Service Mesh也有不同的实现,每一种实现在设置参数时都有它自己的语法格式,理想的情况是它们都遵守统一的接口,希望以后会是这样。
什么时候需要这些技术?
上面提到的技术都不错,但不论你是用程序还是用Service Mesh来实现,都有大量的工作要做,尤其是当服务众多,并且之间的调用关系复杂时。那么你是否应该让所有的服务都具有这些功能呢?我的建议是,在开始时只给最重要的服务增加这些功能,而其他服务可以先放一放。当在生产环境运行一段时间之后,就能发现那些是经常出问题的服务,再根据问题的性质来考虑是否增加这些功能。应用本文中的修饰模式的好处是,它增加和删除修饰功能都非常容易,并且不会影响业务逻辑。
服务韧性是微服务里非常重要的一项技术,它可以在服务环境不可靠的情况下仍能提供适当的服务,大大提高了服务的容错能力。它使用的技术包括服务超时 (Timeout),服务重试 (Retry),服务限流(Rate Limiting),熔断器 (Circuit Breaker),故障注入(Fault Injection)和舱壁隔离技术(Bulkhead)。你可以用代码也可以用Service Mesh来实现这些功能,Service Mesh是将来的方向。但实现它们需要大量的工作,因此需要考虑清楚到底哪些服务真正需要它们。
[1]Go kit
http://gokit.io/examples/stri...
[2] Circuit Breaker Pattern
https://docs.microsoft.com/en...
[3]gobreaker
https://github.com/sony/gobre...
[4]Bulkhead pattern
https://docs.microsoft.com/en...
[5]How it Works
https://github.com/Netflix/Hy...
[6]It takes more than a Circuit Breaker to create a resilient application
https://developers.redhat.com...
[7]Netflix/concurrency-limits
https://github.com/Netflix/co...
[8]Istio
https://istio.io/
[9]Linkerd
https://linkerd.io/
[10]下一代的微服务架构基础是ServiceMesh?
https://www.sohu.com/a/271138...
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK