

golang 中拿 slice 当 queue 和拿 list 当 queue
source link: https://www.tuicool.com/articles/NrIFVf7
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
前言
我记得曾经有一次参加面试时,在答题过程中非常嘴欠地说了一句:“我之所以代码这么写,因为在 golang 中没有内置的无限长度 queue 的实现……”,当时说完我就后悔了,面试我的人,前几个问题本就有那么几分刻薄,一听这一句,立马就来劲了:“谁说没有?谁说没有?”
好在我连连改口,巧舌如簧,搪塞了过去。我明白,在大牛们的手里,只需最简单的数组,稍微加几个“简单的”函数,摇身一变,就可以成为“现成的”队列、栈、环、二叉树、图……
我不仅不是大牛,我还是个懒汉,我希望的内置的队列,是拿过来就能 dequeue
、 enqueue
的工具,但 golang 的标准库里并没有名字叫 queue 的内置对象,只用 channel 可以在某些时候当队列来用,但是一个 channel 使用长度限制的,超过 channel 的长度了还继续入队会触发阻塞,最简单的例子:二叉树的逐层遍历,第一想到的是用队列去做吧?你不知道二叉树的尺寸,你敢用 channel 怼上去吗?
网上有很对文章展示了如何自己实现一个队列,看起来似乎也没啥问题,但我说了我很懒,我不想自己手写一个队列。你说可以把网上的代码复制粘贴过来?那我们猜个谜,问:什么实现最有可能需要实现逐层遍历二叉树?
答案是:面试的时候。那你是要我面试的时候把把网上的代码复制粘贴过来吗?
……
虽然 golang 没有内置的 queue,但它还是提供了很多强大的数据结构,那有没有可以直接拿过来当 queue 来使的呢?有的,且至少有两个选项。强调一句,我们这里并不讨论线程安全队列,仅是普通的无容量限制队列。
拿 slice 当 queue
我敢打赌,slice 是你在 golang 中用到的最频繁的数据结构了,它基于底层数组实现的,但又比数组要强大的多。拿来当队列用,slice 是完全能胜任的。
初始化一个队里:
var queue []int
入队一个元素:
queue = append(queue, 1)
出队一个元素:
if len(queue) > 1 {
queue = queue[1:]
}
看吧,简单明了,易学易用。
但你会不会有一点觉得 queue = queue[1:]
这样的写法有一点挫?白白浪费掉了 slice 前端元素的内存,和队列的假溢出问题有点像,当然 slice 会自动扩容,并不会发生假溢出,且每次扩容时会重新开辟新数组,拷贝元素到新数组时并不会拷贝被弃用的元素,所以内存的浪费还是在可控的范围内的。我们可以跑一个例子加以说明:
// 一个空的 cap 为 5 的 slice
queue := make([]int, 0, 5) // _ _ _ _ _
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 0, cap(queue): 5, queue: []
// 入队一个元素
queue = append(queue, 1) // [1] _ _ _ _
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 1, cap(queue): 5, queue: [1]
// 再入队一个元素
queue = append(queue, 2) // [1 2] _ _ _
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 2, cap(queue): 5, queue: [1 2]
// 出队一个元素
queue = queue[1:] // 1 [2] _ _ _
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 1, cap(queue): 4, queue: [2]
// 再入队三个元素
queue = append(queue, 3, 4, 5) // 1 [2 3 4 5]
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 4, cap(queue): 4, queue: [2 3 4 5]
// 出队二个元素
queue = queue[2:] // 1 2 3 [4 5]
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 2, cap(queue): 2, queue: [4 5]
// 再入队一个元素,触发 slise 的扩容,根据扩容策略,此时 slice cap 为 2,翻倍为 4
queue = append(queue, 6) // // [4 5 6] _
fmt.Printf("len(queue): %v, cap(queue): %v, queue: %v\n", len(queue), cap(queue), queue)
// 输出 len(queue): 3, cap(queue): 4, queue: [4 5 6]
不过你可以看到了,当不断地入队出队,slice 的需要反复扩容,这也可能造成一定的 CPU 消耗。且 queue = queue[1:]
这样的写法未免也太简单粗暴了一点,有没有更高大上的做法呢,我们且看另一种可以拿来当队列用的数据结构。
拿 list 当 queue
这里的 list 指的是 golang 内置的包 container/list
,是这是一个双向链表的实现,如果你不了解它,可以花几分钟看一下这篇 《container — 容器数据类型:heap、list和ring》
,这里复制粘贴一下,把 list 对应的方法列举一下:
type Element
func (e *Element) Next() *Element
func (e *Element) Prev() *Element
type List
func New() *List
func (l *List) Back() *Element // 最后一个元素
func (l *List) Front() *Element // 第一个元素
func (l *List) Init() *List // 链表初始化
func (l *List) InsertAfter(v interface{}, mark *Element) *Element // 在某个元素后插入
func (l *List) InsertBefore(v interface{}, mark *Element) *Element // 在某个元素前插入
func (l *List) Len() int // 在链表长度
func (l *List) MoveAfter(e, mark *Element) // 把e元素移动到mark之后
func (l *List) MoveBefore(e, mark *Element) // 把e元素移动到mark之前
func (l *List) MoveToBack(e *Element) // 把e元素移动到队列最后
func (l *List) MoveToFront(e *Element) // 把e元素移动到队列最头部
func (l *List) PushBack(v interface{}) *Element // 在队列最后插入元素
func (l *List) PushBackList(other *List) // 在队列最后插入接上新队列
func (l *List) PushFront(v interface{}) *Element // 在队列头部插入元素
func (l *List) PushFrontList(other *List) // 在队列头部插入接上新队列
func (l *List) Remove(e *Element) interface{} // 删除某个元素
当然我们是不用关心这么多方法的,拿来当队列用的话,还是很简单的:
初始化一个队里:
queue := list.New()
入队一个元素:
queue.PushBack(1)
出队一个元素:
if queue.Len() > 1 {
queue.Remove(queue.Front())
}
queue.Remove(queue.Front())
比 queue = queue[1:]
看起来高大上多了有没有?由于是基于链表的,自然也没有内存浪费或假溢出的情况,你是不是已经决定好了,以后要用队列就用它了。
由于不需要像 slice 那样在扩容时大量拷贝元素,list 作为队列一定比 slice 性能好得多,难道不是吗?
性能对比
且慢,口说无凭,我们做个性能测试吧。
测试代码我已经写好了,测试逻辑是这样的,每次往队列里入队两个元素,再出队一个元素,保持队列的中元素数量持续增长。且看代码:
import (
"container/list"
"testing"
)
func BenchmarkListQueue(b *testing.B) {
q := list.New()
for i := 0; i < b.N; i++ {
q.PushBack(1)
q.PushBack(1)
q.Remove(q.Front())
}
}
func BenchmarkSliceQueue(b *testing.B) {
var q []int
for i := 0; i < b.N; i++ {
q = append(q, 1)
q = append(q, 1)
q = q[1:]
}
}
运行结果:
$ go test -bench=. -benchmem -count=3 goos: darwin goarch: amd64 pkg: tinylib/queue/queue_test BenchmarkListQueue-12 10000000 144 ns/op 96 B/op 2 allocs/op BenchmarkListQueue-12 10000000 208 ns/op 96 B/op 2 allocs/op BenchmarkListQueue-12 10000000 169 ns/op 96 B/op 2 allocs/op BenchmarkSliceQueue-12 100000000 25.8 ns/op 82 B/op 0 allocs/op BenchmarkSliceQueue-12 200000000 12.0 ns/op 83 B/op 0 allocs/op BenchmarkSliceQueue-12 100000000 10.5 ns/op 82 B/op 0 allocs/op PASS ok tinylib/queue/queue_test 13.337s
没想到吧,slice 作为队列,性能要比 list 好得多,无论是 CPU 耗时、内存消耗、内存申请次数,slice 到要低,甚至单次操作的 CPU 耗时仅为 list 的 1 ⁄ 20 到 1 ⁄ 10 。
你是不是缓过神来了,由于双向链表的维护本身就是需要成本的(维护前驱指针和后继指针),且链式结构的内存寻址也肯定不如线性结构来得快的。相比于 list “出栈时就释放内存,出栈事故才申请内存”,slice 的扩容策略实际上是“攒满了才释放,避免频繁 GC,申请时申请多一点作为预留,避免频繁 allocs”,这简直成是一个性能调优的典范呀。
那是不是可以下定论了,用 slice 当队列比用 list 当队列性能得多呢?
且慢 again。
换一个场景再对比
要知道,性能调优是要考虑具体场景的,在不同的场景,无谓的性能调优可能会适得其反。我们换一个场景测试上述的例子,这个场景是:队列元素的尺寸比较大。
还是之前的代码,只是这次队列元素不再是一个 int,而是一个长度为 1024 的数组:
import (
"container/list"
"testing"
)
func BenchmarkListQueue(b *testing.B) {
q := list.New()
for i := 0; i < b.N; i++ {
q.PushBack([1024]byte{})
q.PushBack([1024]byte{})
q.Remove(q.Front())
}
}
func BenchmarkSliceQueue(b *testing.B) {
var q [][1024]byte
for i := 0; i < b.N; i++ {
q = append(q, [1024]byte{})
q = append(q, [1024]byte{})
q = q[1:]
}
}
再次运行:
$ go test -bench=. -benchmem -count=3 goos: darwin goarch: amd64 pkg: tinylib/queue/queue_test BenchmarkListQueue-12 2000000 638 ns/op 2144 B/op 4 allocs/op BenchmarkListQueue-12 3000000 705 ns/op 2144 B/op 4 allocs/op BenchmarkListQueue-12 3000000 521 ns/op 2144 B/op 4 allocs/op BenchmarkSliceQueue-12 2000000 4048 ns/op 11158 B/op 0 allocs/op BenchmarkSliceQueue-12 1000000 3380 ns/op 11003 B/op 0 allocs/op BenchmarkSliceQueue-12 1000000 2045 ns/op 11003 B/op 0 allocs/op PASS ok tinylib/queue/queue_test 23.784s
可以看到,这一次 slice 的性能反过来被 list 碾压了,单次操作所用的 CPU 耗时是 slice 的三四倍,内存使用更是高达五六倍。
由于元素尺寸比较大,slice 扩容时的元素拷贝操作变成了其性能瓶颈,由于在测试代码中,队列的长度会越来越长,所以每次扩容需要拷贝的元素也越来也越多,使得性能越来越差。所以如果我们再调整一下代码,让队列中的元素数量总是保持在一个较低的数字,slice 未必就那么容易输。
总结
综上所述,在常规情况下,slice 因为其结构的简单,维护成本低,作为队列,性能是胜于 list 的。但如果元素的尺寸越来越大,队列中存储的元素越来越多,slice 扩容成本也会随之越来越大,当超过一个临界值后,便会在性能上输给 list。
但事实上,本文展示了一个错误的使用方法,上文中将 [1024]byte
作为队列元素时,你应该会反应过来,如果换成 *[1024]byte
,岂不是会省去大量的值拷贝操作,大大提升性能?是这样的,如果元素的尺寸确实需要比较大,可以换成指针类型作为队列中的元素,这时候 slice 就没那么容易输了。
为了证明一下这个结论,最后我们祭出 LeetCode 的题: 二叉树的层次遍历 ,一模一样的解题思路,一个用 slice,一个用 list,运行结果如下:
slice:
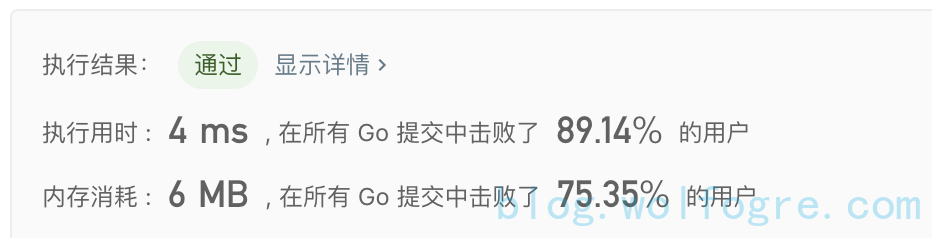
list:

这里好像 slice 比 list 快了 4 ms,但事实时上这么小的时间差距已经没有什么可比性的了,稍微抖一抖,多跑几次,结果可能就一会儿 8 ms 一会儿 4 ms,毕竟测试用例没有真实地逼出两种写法的性能差异,这里只是想说明,slice 作队列并不会比 list 挫。
附代码,写得不好,将就看哈。
func levelOrder(root *TreeNode) [][]int {
var ret [][]int
if root == nil {
return ret
}
var queue []*TreeNode
queue = append(queue, root)
queue = append(queue, nil)
layer := make([]int, 0)
for len(queue) > 0 {
node := queue[0]
queue = queue[1:]
if node == nil {
ret = append(ret, layer)
layer = make([]int, 0)
if len(queue) > 0 {
queue = append(queue, nil)
}
continue
}
layer = append(layer, node.Val)
if node.Left != nil {
queue = append(queue, node.Left)
}
if node.Right != nil {
queue = append(queue, node.Right)
}
}
return ret
}
func levelOrder(root *TreeNode) [][]int {
var ret [][]int
if root == nil {
return ret
}
queue := list.New()
queue.PushBack(root)
queue.PushBack(nil)
layer := make([]int, 0)
for queue.Len() > 0 {
node, ok := queue.Front().Value.(*TreeNode)
queue.Remove(queue.Front())
if !ok {
ret = append(ret, layer)
layer = make([]int, 0)
if queue.Len() > 0 {
queue.PushBack(nil)
}
continue
}
layer = append(layer, node.Val)
if node.Left != nil {
queue.PushBack(node.Left)
}
if node.Right != nil {
queue.PushBack(node.Right)
}
}
return ret
}
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK