

新一波潮流来袭:网络与计算之融合
source link: https://www.sdnlab.com/23432.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
从计算机诞生伊始,“计算”这个词汇便随着时代的变迁不断丰富着自己的内涵,IT从业者为了提高计算效率也在给“计算”赋予了更多载体,高性能计算、云计算、量子计算都通过各个领域为计算赋能。时代发展离不开网络,那么网络如何与计算融合成为本文要讨论的话题。

为什么要关心计算和网络的融合?
计算与网络一直密不可分,用网络与计算的高效融合也成为了未来计算发展的趋势。我们也可以看到与计算机相关的硬件和软件(如运行虚拟机的通用CPU、传统操作系统和编程语言)越来越多地被用于各类网络功能。诸如交换机,路由器和NIC之类的网络设备也正在变得可编程,以允许在网络中完成各类通用计算。
在以数据中心为代表的高密度计算集群,应用呈多元化和分布化,更大的网络带宽也带来了海量数据对 I/O处理的计算需求不断飙升,新型的网络功能虚拟化也在进一步蚕食CPU的算力,同时GPU的负载转移工作也是杯水车薪。
网络带宽远远超过计算能力
目前,服务器网络带宽正面临快速增长。200Gbps以太网网卡已经成为主流,厂商还在不断研发新的400Gbps NIC,而1Tbps很快将成为下一个目标。另一方面,处理网络I/O的计算容量空间正在不断缩小。例如,对于典型的使用32字节键值的键值存储,为了在100 X86 CPU内核的情况下保持400Gb/s的线速,一个内核大约需要500个周期来处理每个键值对。即使在这种理想的假设下,这种微不足道的计算预算也仅仅能够在网络堆栈中执行一些LLC或内存访问,留给应用程序逻辑的东西少得可怜。换句话说,未来具有线速I/O处理需求的应用程序注定要受到CPU和内存的限制。
多年来,各种底层网络层功能已经被应用到了网卡硬件中。这些硬件卸载构成了网络I/O处理的主干,范围从简单的分散聚集I/O、校验、计算和数据包分段到完整的传输层加速器,如TCP卸载和RDMA。
商用服务器对于线速I/O的低延迟处理需求达到了前所未有的高度,硬件无法跟上数据中心网络工作负载的快速变化。例如,用于访问网络附加存储、新标准和隧道格式的压缩技术都在快速发展,超过了ASIC开发和部署的生命周期。此外,数据中心网络范式从专有的中间盒,例如防火墙和入侵检测系统,转变为虚拟网络功能(VNF) ,这也进一步推动了计算需求。VNF给CPU的网络处理带来了负担,并且也对计算提出了更高的要求。
CPU和GPU的挑战
网络I/O的性能问题长期以来一直备受关注,其重点在于消除操作系统网络堆栈中的低效率以及优化NIC-CPU交互。目前实现VNF的常用方法是完全绕过网络堆栈,直接从用户级库(例如DPDK)访问原始数据包。此外,CPU和NIC硬件提供了几种机制来提高I/O处理的效率,例如,将数据直接引入CPU LLC(DDIO),并通过减少CPU内核之间的缓存争用(例如,接收端扩展)和降低中断频率(例如,中断调制)来提高可扩展性。但即使采用了这些增强功能,在10Gbps的速度下依旧需要多个CPU内核来执行公共网络功能。此外,现有系统也会因为CPU资源争用而导致延迟增加,包处理性能也出现波动。

GPU也被用于加速网络数据包处理应用(例如,PacketShader、SSLShader、SNAP和GASPP)。不幸的是,由于GPU控制和PCIe数据传输,GPU引入了高延迟开销。此外,在大多数I/O密集型工作负载(如路由)中,GPU的TCO增益和功率效率受到了质疑,仅在CPU上使用延迟隐藏技术就能够在较低的延迟下实现类似的性能。目前关于使用GPU加速网络处理还存在许多争议。伴随着一系列的挑战,网络与计算的高效融合势在必行。
网内计算:网络与计算融合的助推器
网内计算(In-network computing)是近年来出现的一个新的研究领域,侧重于网络内的计算,利用新型可编程网络设备(如可编程交换机ASIC,网络处理器,FPGA和可编程NIC)的功能,将计算从CPU转移到网络。
虽然网内计算的概念最早可以追溯到二十年前,但许多人认为,如今将软硬件创新结合的时代正是网内计算真正发挥作用的时代。从系统的角度看,网内计算的定义意味着无需向网络中添加新设备,因为你已经使用了交换机和NIC。因此,网内计算的开销很小,因为不需要额外的空间、成本或空闲功率。此外,网内计算在事务通过网络时就终止事务,可以减少网络上的负载。迄今为止,网内计算是在三类设备上实现的:FPGA,SmartNIC和可编程交换机。

可编程switch-ASIC的引入和SmartNIC的兴起是网内计算的推动力。在过去,网络设备的功能是固定的,仅支持制造商定义的功能。相比之下,可编程网络设备允许用户在用高级语言编写代码时实现自己想要的功能。今天,可编程网络领域使用的主要语言是P4,是一种开源的、特定领域的语言。最初,该语言主要用于定义新协议和网络相关功能(例如,带内网络遥测)。很快,研究人员就开始在语言和平台的基础上将更复杂的功能移植到网络中。
网内计算的优势:高吞吐量、低延迟、低能耗
网内计算的主要优势是性能,包括吞吐量和延迟。如今,许多网络设备支持亚微秒级的延迟,在非超额订阅的情况下差异很小。但是,这并不是减少延迟的主要来源。由于网内计算指的是网络内的处理,这意味着事务在其路径中就终止,无需到达终端主机,从而节省了终端主机引入的延迟,以及网内计算节点到终端主机之间的网络设备。特别是在云环境中,服务提供商都在努力克服服务延迟,因此减少延迟非常重要。
第二个性能优势吞吐量,它是数据包处理速率的属性。交换机ASIC处理速度高达每秒100亿个数据包,因此可能支持每秒数十亿次的操作。这类交换机被设计为管道,连续移动数据而不出现卡顿。在大多数情况下,即使一个操作(数据包)暂停(排队),例如在共享资源(拥塞)上竞争时,其他数据包的处理并不会受影响。使用网内计算实现的应用程序与基于主机的同类产品相比,性能提升了一万倍。

网内计算还有一个让人意想不到好处是能耗。尽管大家都认为网络交换机是一个耗电的设备,但如果只考虑每瓦操作,网络交换机更具吸引力,每瓦特支持数百万次操作,这意味着对于某些应用程序来说,这种方法的效率比基于软件的解决方案高一千倍。举例来说,在一个交换机上,一百万个键值存储查询的“成本”小于一瓦特。由于网络交换机是用户网络的一部分,因此大部分功耗已经包含在包转发过程中,并且网内计算的开销很小,仅占交换机总功耗的几个百分点。
软硬件结合促进网内计算落地
如今硬件和软件创新的结合,给网内计算注入了新的生机。在硬件方面,许多硬件供应商已经发布了可在不牺牲性能的情况下提供可编程性的产品,例如可编程芯片(Barefoot Tofino)、现代智能网卡SmartNIC(Cavium XP,Netronome Agilio)。在软件方面,除了网内遥测和第4层负载平衡等新的网络功能外,还提出了许多超越传统分组处理的新的应用级功能,如键值缓存、RDMA。
SmartNIC
21世纪初,随着英特尔的IXP系列网络处理器的引入,在NIC中加入可编程硬件的想法得到了积极的研究。然而,这些处理器主要用于专用的网络设备,而不是商用服务器。虽然2007年之后该领域的研究活动几乎为零,但现在来看当时发表的许多著作还是可圈可点的
智能卡以服务器网络工作负载为目标。NIC上的计算单元有两种主要的设计选择:完全可编程的网络处理器(例如,Mellanox BlueField、Cavium LiquidIO、Netronome Agilio-CX)和通过高速互连直接连接到NIC ASIC的FPGA(Mellanox InnovaFlex和Microsoft Catapult board)。从概念上讲,基于SoC的SmartNIC是早期网络处理器的嫡系后裔。它们依赖于一个定制的高线程CPU,配备了大量的固定功能单元和硬件加速处理原语。
另一方面,基于FPGA的SmartNIC类似于常规FPGA板,但也有明显区别。与在网络连接的FPGA中一样,它们具有低延迟,高带宽数据以及NIC和FPGA之间不涉及CPU的控制路径。此外,它们还提供从FPGA到主机存储器和其他主机资源的快速数据路径。最常见的设计称为“bump-in-the-wire”:所有输入流量首先到达FPGA,然后传递给NIC ASIC,后者将数据传输到主机(出口顺序相反)。

这种设计很有吸引力。 首先,它不需要对原始NIC ASIC进行深度更改。此外,它允许重用NIC上的优化DMA硬件,从而使SmartNIC向后兼容主机上的标准网络堆栈。FPGA也可以拥有独立的到主机存储器(如Catapult)的DMA,并且可以用作常规的旁视FPGA。
可编程交换芯片
Barefoot Tofino
Tofino2芯片U系列是高端产品,具有数目最多的80个引擎,三种带宽模式均可选。它定位于运营商市场服务于5G、边缘计算以及那些想要把诸如负载均衡和防火墙等软件功能都包含在交换机当中的超大型数据中心客户。它还考虑运用于存储集群市场,在满足高带宽需求的同时把一些计算工作卸载到交换机当中。Barefoot通过去除SerDes模组来调整带宽,目标市场包括NFV卸载、计算卸载以及网络应用层实现。

这些卸载应用至关重要,并且已经有企业采纳该方法。目前UCloud通过运行于Tofino芯片的P4程序,取代了之前运行于200台x86服务器之上的负载均衡工作,而且是线速处理。阿里在负载均衡方面也采用了Tofino,据说一个单片的Tofino芯片相当于100台服务器的软LB的性能,而且已经接受了2018双十一场景的严酷考验。

此外可以通过Tofino网络来实现大量的计算任务,不仅仅是机器学习,只要是连接交换机的服务器涉及到Key/value存储,都可以利用交换机来缓存热数据。Memcached很适合做分布式存储,它虽然很小但是因为热数据被频繁访问,所以利用交换机上相对很小的存储区就可以大幅提升访问性能,同时降低由于热数据访问而形成的尾延时。任何程序经过编译后运行在Tofino芯片上都会是线性处理,它是单向流架构,所以无需要考虑性能调优的问题,运行起来就是全速。因此对于计算网络应用,Tofino方案非常简单,它本来就是实时处理,用户不需要再担心中断等类似问题。
RDMA
RDMA(Remote Direct Memory Access)的全称为远程直接内存访问,是为了解决网络传输中服务器端数据处理的延迟而产生的。RAMA网络可应用在可编程交换芯片和SmartNIC中,目前市场上大致有三类RDMA网络,分别是Infiniband、RoCE、iWARP。
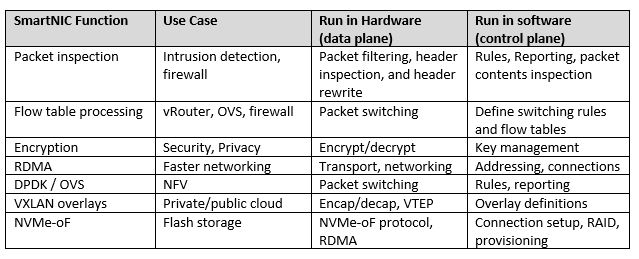
在网络的开放控制中,SDN解决的是路由控制的问题,而RDMA要解决的是流量控制问题。要解决什么样的流量呢?如果是点对点两两互打的话,这个对交换机来说并没有什么太大的压力,每两点产生的流量再大,有线速保障的交换芯片都可以处理过来。但是如果碰到多打一的情况,交换机芯片再强大也处理不了。对这种情况只能从源端进行解决,把原来的大流量变成原来的三分之一,出口那边才可能扛住。在源端分流最常用的方法是从TCP的端侧流控,但这有一个缺点,速度比较慢,有可能对端反馈过来的时候在交换机里已经产生丢包了。于是有了RDMA,可以做端到端的全程流控,整个网络都可以参与流量拥塞的反压。
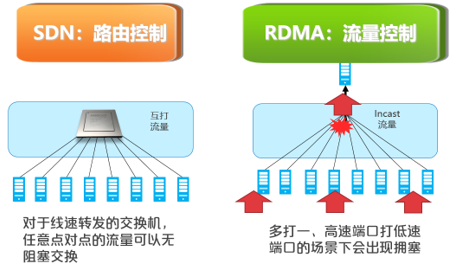
下图是RDMA的技术实现,首先在网络侧需要优化配置PFC和ECN等参数,整个RDMA最难的就是这些参数该怎么配。智能网卡侧实现数据远程搬运,同时可以降低CPU的流控负担。最后,原有的TCP协议栈也要重新改写,替换为RoCEv2 verbs的接口。RDMA最终的目标是高吞吐、低时延和不丢包。
RDMA技术最早应用于科学计算,是一套比较封闭而且价格比较昂贵技术。在以太网中,RDMA主要应用于大数据计算、分布式存储和深度学习网络等大吞吐量,低时延的场景。目前,RDMA的使用其实已经比较广泛了,最早是微软将其应用至云数据中心的场景,BAT等互联网公司主要用于为AI训练任务和分布式存储。值得一提的是,迈络思(Mellanox)的智能网卡就是使用RDMA和TCP/IP加速和虚拟化对存储的访问,迈络思也是InfiniBand与RDMA技术的主要发明者。
网内计算面临的挑战
网内计算有许多优势,但同样也存在很多挑战。有两个重要问题在流量加密时,如何体现网内计算优势,以及网内计算带来的安全风险。此外,网络设备的体系结构不适用于机器学习应用程序。虽然运行机器学习的系统肯定可以从网络内的加速中受益,但到目前为止,在网络中运行训练模型已经被证明是一件很困难的事。
除此之外,内计算还面临着一些重大的技术挑战。最大的挑战可能是需要从程序员那里抽象出网络硬件。虽然P4是一种声明性语言,但它仍然在数据包层面运行。理想情况下,程序员能够使用更高级别的抽象进行编码。该语言目前还缺乏对状态操作的支持,因为当前的解决方案是针对特定目标的。此外,为了实现当今的高性能,程序员必须了解硬件目标并在代码中利用其功能。在不同的网络硬件目标之间移植代码并非易事,通常需要对代码进行大量更改。在异构目标(例如,CPU,GPU,交换机ASIC)之间移植相同的代码更是难上加难。调试工具将在未来网络计算中发挥至关重要的作用。目前,虽然有几种形式的验证工具,但构建适合网络设备架构的调试器和移动数据(而不是指令)的管道很难。
随着网内计算的发展,会出现更多的挑战,例如虚拟化。是否可以在同一网络设备上运行多个应用程序?如何隔离资源?CPU上的虚拟化和网络设备之间的区别是什么?这些问题都值得我们思考。
到目前为止,大多数网内计算研究都是从网络社区中产生的,需要其他研究社区的参与。从编译器和抽象,到调度和资源分配,再到虚拟化和新的用例,网内计算在异构计算环境中作为一个“新的个体”,仍有许多需要创新和发现的地方。
参考
1.https://baijiahao.baidu.com/s?id=1616906150596202072&wfr=spider&for=pc
2.https://www.sigarch.org/the-new-life-of-smartnics/
3.https://www.nextplatform.com/2018/12/04/programmable-networks-get-a-bigger-4.foot-in-the-datacenter-door/
4.https://www.sdnlab.com/22915.html
5.https://conferences.sigcomm.org/sigcomm/2018/workshop-netcompute.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK